Прогнозирование и анализ ценообразования цифровых товаров на маркетплейсах
Решетникова М.С.1 ![]() , Приказнов Ф.А.1
, Приказнов Ф.А.1 ![]()
1 Российский университет дружбы народов им. Патриса Лумумбы, Москва, Россия
Скачать PDF | Загрузок: 47
Статья в журнале
Вопросы инновационной экономики (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 15, Номер 2 (Апрель-июнь 2025)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=82670726
Аннотация:
Цифровые активы стали неотъемлемой частью современной экономики, особенно в условиях активного развития маркетплейсов, которые выступают площадками для их купли-продажи. На фоне роста популярности видеоигр и увеличения объёмов торговли игровыми аккаунтами возникает необходимость точной оценки их стоимости. Однако процесс ценообразования таких активов осложнён множеством факторов. Данная статья посвящена разработке модели прогнозирования стоимости цифровых товаров на маркетплейсах с использованием статистических и эконометрических методов. В ходе исследования выявлена экспоненциальная зависимость между рейтингом аккаунта и его ценой, что позволило значительно повысить точность предсказаний. Для повышения надёжности модели были применены методы нормализации и оптимизации данных. Особое внимание в статье уделено анализу факторов, влияющих на рыночную стоимость игровых аккаунтов, и оценке точности прогнозов. Полученные результаты демонстрируют универсальность предложенного подхода и возможность его адаптации для оценки других цифровых и физических товаров на различных маркетплейсах
Ключевые слова: цифровые товары, маркетплейсы, e-commerce, эконометрические методы
JEL-классификация: O31, O32, O33
Введение
В условиях активной цифровизации экономики особую значимость приобретает развитие цифровых активов и инфраструктуры их обращения. На современном этапе одним из ключевых инструментов распространения цифровых товаров становятся маркетплейсы, которые выполняют роль посредников между продавцами и покупателями, обеспечивая удобный и безопасный процесс купли-продажи [12 c 34].
Рост востребованности цифровых активов на фоне глобальных экономических и технологических изменений привёл к стремительному развитию маркетплейсов, что подтверждается значительным увеличением их выручки за последние годы. Динамика крупнейших маркетплейсов Российской Федерации демонстрирует положительную тенденцию, отражая как рост спроса на цифровые товары, так и расширение спектра предлагаемых услуг [2].
Изучение рыночной стоимости цифровых товаров становится особенно необходимым условием успешного ведения бизнеса в условиях цифровой экономиких [4, c 104]. Особую актуальность приобретают методы оценки цифровых активов, в частности игровых аккаунтов, которые могут быть адаптированы и применены в иных сегментах цифрового рынка.
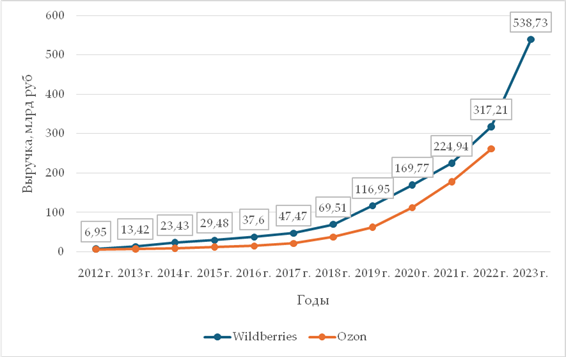
Рис. 1. Динамика выручки двух крупнейших маркетплейсов в РФ за 2012-2023 гг.
Источник: Составлено автором по данным [6, 7]
Имея информацию о рыночной цене запускаемого в производство продукта, можно с гораздо большей точностью вынести решение о рентабельности проекта до его непосредственного запуска. [1, c 234]. При этом чем более корректно спрогнозирована цена и чем более несмещенная оценка получена, тем меньше будет заложено риска в прогнозируемую модель целесообразности определенного проекта.
Таким образом, цель данного исследования заключается в определении методов получения наиболее точной рыночной оценки определенного продукта (в данном случае будет рассмотрен цифровой продукт, однако, впоследствии также будет показано, что полученную модель можно будет экстраполировать и на обычный, вещественный товар) и дальнейшего их применения.
Результатом исследования будет конечная модель, которая для определенных входных факторов, описывающих рассматриваемые компоненты анализируемого товара, имеющего вариативность, спрогнозирует ожидаемую цену.
Материалы и методы
В качестве объекта исследования был выбран рынок аккаунтов игры Brawl Stars (имеющей более 100 млн скачиваний на момент 2024-12-11) [18]. Это одна из наиболее популярных игр на Android от разработчика Supercell, также известной такими играми, как Clash Royale, Clash of Clans и Hay Day. Возраст целевой аудитории находится в диапазоне от 10 до 18 лет. Играя в игру (проводя битвы с другими игроками), пользователи «прокачивают» своих персонажей (делают их более сильными), а также открывают новых, вплоть до всех 79. По сути, внутриигровой прогресс будет исчисляться, с одной стороны, количеством персонажей, а с другой стороны – их уровнем прокачки (качеством). Именно это и будет составлять стоимость аккаунта. Поскольку «прокачивать» и получать новых персонажей – достаточно долго и энергозатратно, многие пользователи предпочитают сразу купить готовый аккаунт с определенным прогрессом. Перейдем далее к представлению самих данных.
Таблица 1. Структура исследуемых данных
|
Переменная
|
Тип
|
Пример
значения
|
Описание
|
|
price
|
int
|
219,
1200, 499
|
Цена
|
|
days_inactive
|
int
|
687,
34, 116
|
Количество
дней без активности
|
|
published_date
|
datetime
|
"2024-05-02
20:57:51"
|
Дата
публикации
|
|
brawlers_count
|
int
|
31, 71,
46
|
Количество
персонажей
|
|
legendary_count
|
int
|
1, 8, 4
|
Количество
легендарных персонажей
|
|
mythic_count
|
int
|
5, 19,
10
|
Количество
мифических персонажей
|
|
mail
|
factor
|
"firstmailler.net"
|
Домен
электронной почты
|
|
level
|
int
|
70,
174, 108
|
Уровень
|
|
cups
|
int
|
10433,
30163, 19753
|
Количество
кубков
|
|
full_legendary_brawlers_addons
|
int
|
0, 4, 0
|
Полные
улучшения для легендарных персонажей
|
|
full_mythic_brawlers_addons
|
int
|
0, 5, 1
|
Полные
улучшения для мифических персонажей
|
|
legendary_addons
|
int
|
0, 22,
2
|
Улучшения
для легендарных персонажей
|
|
mythic_addons
|
int
|
1, 38,
8
|
Улучшения
для мифических персонажей
|
|
is_good_mail
|
bool
|
True, False
|
«Хорошая»
ли почта
|
Всего в таблице 10060 строк, каждая строка представляет из себя конкретную сделку.
Далее рассмотрим основные описательные статистики для переменных.
Таблица 2. Описательные статистики для количественных переменных
|
Metric
|
days_inactive
|
price
|
brawlers_count
|
legendary_count
|
mythic_count
|
level
|
cups
|
|
N
|
10060
|
10060
|
10060
|
10060
|
10060
|
10060
|
10060
|
|
Mean
|
171,09
|
330,29
|
44,77
|
3,1
|
9,27
|
88,3
|
14567,41
|
|
SD
|
254,68
|
544,76
|
17,2
|
2,65
|
6,52
|
47,15
|
9112,51
|
|
Median
|
37
|
190
|
44
|
2
|
8
|
83
|
13551
|
|
Trimmed
|
111,41
|
227,48
|
44,96
|
2,77
|
8,77
|
85,15
|
13953,91
|
|
MAD
|
20,76
|
163,09
|
17,79
|
2,97
|
7,41
|
41,51
|
8493,82
|
|
Min
|
0
|
5
|
1
|
0
|
0
|
5
|
300
|
|
Max
|
885
|
13500
|
79
|
10
|
25
|
407
|
73074
|
|
Range
|
888
|
13495
|
78
|
10
|
25
|
402
|
72774
|
|
Skew
|
1,69
|
7,7
|
-0,07
|
0,97
|
0,57
|
0,91
|
0,82
|
|
Kurtosis
|
1,29
|
108,18
|
-0,53
|
0,28
|
-0,53
|
1,91
|
1,35
|
|
SE
|
2,54
|
5,43
|
0,17
|
0,03
|
0,07
|
0,47
|
90,85
|
Источник: составлено автором на основе [19] с использованием R.
Во-первых, N в 10060 для каждой переменной свидетельствует о том, что в наших данных нет пропущенных значений. Далее, стоит обратить внимание на значение медиан, чтобы примерно понимать, что представляют из себя различные совокупности.
Так, медианное значение цены сделки – 190 рублей. Среднее при этом составляет 330 рублей, что говорит о правосторонней скошенности (об этом также говорит и достаточно высокое значение Skew в 7,7 (если Skew >0, распределение скошено вправо). Медианное количество персонажей (brawlers_count) составляет 44 [при 79 максимально возможных), в то время как количество легендарных и мифических персонажей составляют 2 (при 10 максимально возможных) и 8 (при 25 максимально возможных) соответственно.
Средний уровень на аккаунте составляет 88. Более интересна информация по cups (рейтингу). Рассмотрим эту переменную более детально. При среднем в 14500 имеем медиану в 13500, что свидетельствует о незначительной скошенности в правую сторону (об этом же говорит и skew в 0,82). Усеченное среднее составляет 13900, что говорит о незначительном влиянии обоесторонних выбросов на среднее (сравнение медианы и среднего, а также значение skew нам говорят примерно о том же). Куртозис составил 1,35, что меньше 3, то есть распределение является платокуртическим (плосковершинным), т. е. приплюснуто к оси oY, и имеет относительно длинные, но вполне симметричные хвосты.
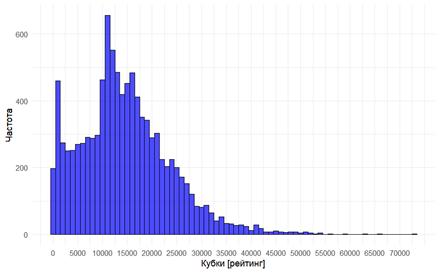
Рисунок 1. Гистограмма кубков [рейтинга] аккаунтов.
Источник: составлено автором на основе [19] с использованием R.
Распределение скошено вправо, а также имеет незначительно скопление около 0. Обратную ситуацию наблюдается у цены. Это единственная переменная, у которой куртозис больше трех, при этом значительно больше; он составляет 108,18 единиц. Такое распределение без сомнения можно назвать лептокуртическим (островершинным), т. е. в значительной степени вытянутым вверх в области среднего, которое составляет 190 (по медиане).С учетом того, что максимальное значение составляет примерно 13500, а skew = 7,7 и указывает на правостороннюю асимметрию, можно полагать, что частота аккаунтов резко обваливается после увеличения цены до 300, и далее продолжает равномерное снижение вплоть до 13500.
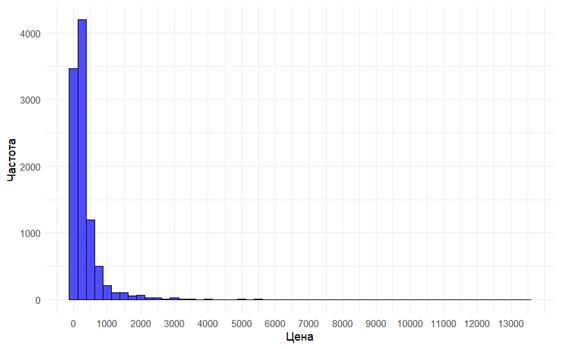
Рисунок 2. Гистограмма цены аккаунтов
Источник: составлено автором на основе [19] с использованием R.
На данном этапе становится вполне очевидно, что данные требуют определенной нормализации. Здесь предлагается сузить диапазон рассмотрения цены с 50 рублей до 2000, а кубков – с 5000 до 40000, и в дальнейшем работать с более удобными данными [20].
Следующий этап предобработки данных будет отведен точечным диаграммам, которые помогают более точно отразить попарную взаимосвязь различных переменных [9 c 345, 14].
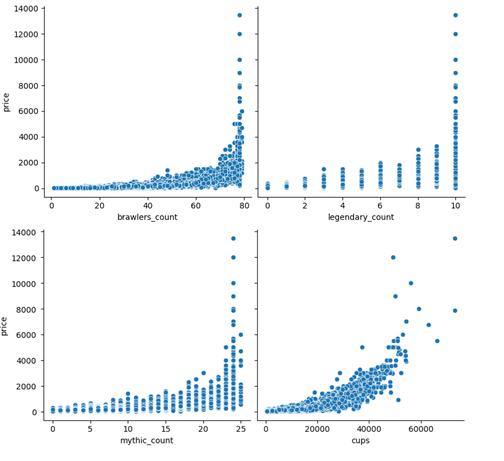
Рисунок 3. Scatter plots наиболее важных характеристик аккаунта (количество всех персонажей, легендарных персонажей, мифических персонажей, величина рейтинга)
Источник: составлено автором с использованием python (библиотеки: pandas и seaborn) на основе данных [19]
Внимание привлекает тот факт, что верхняя часть каждого из четырех графиков практически всегда образует очень четкую тенденцию. Эта тенденция, как несложно заметить, будет наиболее точно аппроксимирована экспоненциальной (или степенной) моделью.
Почему практически все данные подвержены экспоненциальной зависимости? Для того, чтобы объяснить данный факт, можно прибегнуть к аналогии. В микроэкономике существует закон «убывающей предельной отдачи» [11]. Заключается он в том, что при каждом последующем дополнительном использовании ресурса эффект от него уменьшается (становится меньше, чем при предыдущем, уменьшая удельную отдачу от ресурсов). Однако, во-первых, здесь идет речь о другого рода зависимости (логарифмической или степенной с показателем степени <1), во-вторых, процесс игры мало напоминает процесс производства. Тем не менее, суть заключается в том, что играя в игру, изначально пользователь достигает достаточно бурного роста, а далее, при таких же временных затратах, ему все тяжелее и тяжелее развиваться (напоминает эффект «низкой базы»). Иными словами, пользователь может достичь 10000 рейтинга с нуля примерно за месяц игры. Подняться с 10000 до 20000 ему придется уже за месяца 2-3. А с 20000 до 30000 уйдут все полгода. Ввиду этого факта предложение для более высокого рейтинга будет снижаться, причем возрастающими темпами. И это находит обратное отражение в цене (экспоненциальное увеличение).
Можно также апеллировать к трудовой теории стоимости [13, с 329]. Конечно, в игры в первую очередь играют ради удовольствия, однако, создавая аккаунт и обретая внутриигровой прогресс, пользователи создают товар [аккаунт], который может удовлетворить потребность другого человека. Это есть ничто иное как создание добавленной стоимости. С учетом того, что отдача, отражающаяся в изменении количественной переменной (например, рейтинга), уменьшается, игрок должен для получения того же увеличения вложить больше труда. Однако стоимость его труда неизменна вне зависимости от того, на какой стадии развития внутри игры он находится, поэтому при прочих равных большие трудозатраты создадут больше себестоимости (больше издержек) [16 c 67].
Этот тезис можно также подтвердить тем, что существует специальные организации «бустов» (boost – англ., повысить, увеличить) аккаунтов. Поскольку аккаунты имеют стоимость и могут быть проданы, появляются люди, которые специально играют на аккаунтах, чтобы поднять их рейтинг (поскольку того же результата они добиваются за меньшее количество времени, и их предельная отдача за час потраченного времени увеличивается). Конечно, также стоит учитывать и тот факт, что они могут получать гораздо меньше удовольствия от самой игры, поэтому и будут требовать определенную компенсацию в виде повышения часовой ставки.
Теперь следует сделать плотность более равномерной. Для этого проведем узкую группировку переменной cups, с шагом, например, в 100 (этот шаг действительно можно назвать «узким», поскольку sd переменной составляет примерно 9000). И по каждому шагу рассчитаем среднее значение цены. Это приведет к абсолютно равномерной плотности, поскольку каждому диапазону x будет соответствовать одинаковое количество значений y. Применим сразу же экспоненциальную аппроксимацию.
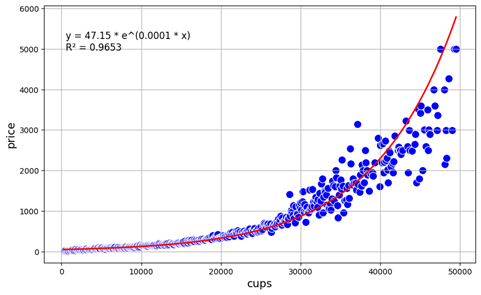
Рисунок 4. Экспоненциальная аппроксимация cups-price
Источник: составлено автором с использованием Python (библиотеки: pandas & seaborn) на основе данных [19]
Коэффициент детерминации в 0,96 демонстрирует крайне мощную связь между двумя переменными. Cups превосходно описывает цену. Также можно наблюдать наличие гетероскедастичности в модели, что указывает на то, что при заключении сделок по аккаунтам, у которых кубки примерно выше 30000, и цена примерно выше 1000, значительное влияние начинают оказывать другие факторы.
Другие факторы можно разделить на три группы:
¾ Другие переменные, которые представлены в df, но пока что не были учтены в модели. Это может быть исправлено посредством включения дополнительных факторов.
¾ Другие переменные, которые не представлены в df вообще (это может быть исправлено посредством проведения дополнительного сбора данных).
¾ Иррациональность субъектов. У нас есть данные по фактическим сделкам, однако каждая отдельная сделка может быть как переоценена (ошибка покупателя), так и недооценена (ошибка продавца).
Крайне примечательно, что на диапазоне от 0 до 30000 рейтинга замечена мощная аппроксимация, несмотря на то что в изначальной зависимости с неравной плотностью была огромная вариативность. Это говорит о том, что, во-первых, иррациональность продавцов и покупателей примерно одинакова, и рынок в целом дает корректную оценку аккаунтам, которая напрямую связана с экономическим смыслом образования стоимости аккаунтов (убывающая предельная отдача от затраченного времени на развитие), во-вторых, факторы помимо рейтинга на каждом шаге группировки также оказывают примерно одинаковое влияние, не вызывая значительные смещения и не приводя к отклонениям от тенденции [10 c 5, 17 c 456].
Отобразим теперь данные по предсказанным и фактическим средним значениям.
Табл. 3. Фактические значения price по cups и предсказания экспоненциальной модели.
|
cups
|
avarage price
|
predicted_price
|
|
5000
|
90
|
77
|
|
10000
|
147
|
125
|
|
15000
|
223
|
203
|
|
20000
|
357
|
329
|
|
25000
|
605
|
535
|
|
30000
|
1204
|
870
|
|
35000
|
1766
|
1414
|
|
40000
|
2616
|
2298
|
|
45000
|
3420
|
3736
|
Модель слегка недооценивает значения на уровне до 30000, чтобы нормально справиться в гетерескедастичностью после 30000 (ввиду специфики экспоненциальной модели). Кроме того, сделав плотность равномерной, было усилено влияние больших значений cups, которые сильно оттягивают на себя регрессию.
Далее будет рассмотрена непосредственно сама модель с модифицированными параметрами на основе метода метода наименьших квадратов (МНК). Целевая функция метода наименьших квадратов (МНК) была модифицирована с целью учета ограничения на положительное отклонение оценки. Это позволило определить нижнюю границу рыночных значений, обеспечивая минимизацию отклонений от модели при контролируемой переоценке в высоковариативных зонах. Проведенный анализ показал, что модель систематически недооценивает значения в центральной части распределения и переоценивает их в правой части. Для устранения переоценки в области высокой вариативности было введено ограничение на допустимое отклонение ошибки модели (не выше 0,05). Оптимизация целевой функции с учетом данного ограничения выполнена с использованием надстройки «Поиск решения» в Excel.
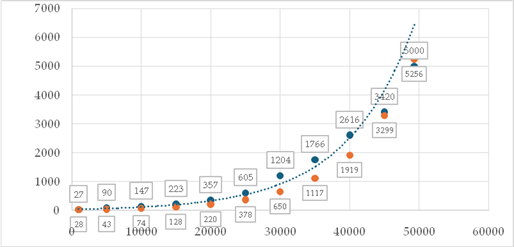
Рисунок 5. Визуализация применения экспоненциальной регрессии с ограничением на ошибки остатков
Источник: составлено автором с использованием Excel на основе данных [19]
Синим пунктиром показана обычная линяя тренда, оранжевым – более консервативные предсказания. Таким образом, был преодолен риск переоценки рыночной стоимости и покупки слишком дорогих аккаунтов в модели с одним предиктором. Однако отметим, что была получена нижняя граница оценки рыночной цен с целью избежать рисков, связанных с покупкой переоцененных аккаунтов. С эконометрической точки зрения подобная ситуация именуется ошибкой первого рода, поскольку модель предполагает, что аккаунт недооценен и призывает к действию (покупку). Ошибка второго рода заключается в том, что модель не призывает к действию (покупке) аккаунта, который недооценен (то есть не совершает действие, когда нужно) [8 c 11].
В случае, если модель рассматривается не для целей перепродажи, а для целей, например, запуска проекта, то ситуация будет аналогичная. Если дана более высокая оценка цене, то есть шанс принятия нерентабельного проекта увеличится. В противном случае увеличивается шанс непринятия рентабельного проекта. Поскольку была намеренно уменьшена вероятность ошибок первого рода ценой увеличения ошибок второго рода, модель можно назвать консервативной. Если для целей исследования есть основания принять данный риск, то модель можно редактировать, изменяя ограничения на остатки разницы логарифмов фактической и прогнозируемой цен с “<=5” до, например, “>=-5”. Тогда модель будет пытаться всегда брать верхнюю планку цены в рамках диапазонов повышенного разброса.
Результаты и обсуждение
Данная модель прогнозирования цены была построена для цифрового товара категории «аккаунт», данные при этом были взяты с определенного маркетплейса. Само же назначение модели в первую очередь сообразно для точечного определения «недооценки» каждого аккаунта в целях увеличения выгоды покупки.
При этом в предпосылках, а также формировании нулевой гипотезы (при интерпретации ошибок первого и второго рода) было также обозначено, что модель ценообразования непосредственно в виде, в котором она была построена здесь, то есть при применении соответствующих методов как обработки данных, так и получения окончательной аппроксимации, может быть применена для целей более точной оценки проекта для запуска нового продукта, поскольку от цены формируется выручка, от выручки в конечном счете прибыль, а от прибыли денежные потоки, которые в итоге используются для подсчета чистой приведенной стоимости проекта. При этом чем более точная дается оценка цене, тем меньше шансов допустить ошибку второго или первого рода при принятии инвестиционного решения. Также модель может быть применена для выхода лица на маркетплейс с продуктом, который уже находится в продаже, либо для выхода компании на рынок. Однако каждый из этих сценариев можно рассматривать как частный случай реализации проекта.
Дальнейший вопрос связан с возможностью применения данной модели для предсказания цены нецифровых товаров. Предположим, российская компания решает проверить целесообразность старта производства ноутбуков, состоящих преимущественно из отечественных компонентов (в рамках программы импортозамещения) [предположим, что предпосылками для запуска такого проекта являются: наличие уникальных технологий в данной сфере у рассматриваемой компании, а также возможность получения субсидирования от государства; данный факт не имеет непосредственного отношения к нашей модели, однако для отражения экономической сущности должен быть отмечен] [3, 15 c 8].
Поскольку компания собирается производить не просто ноутбук исключительно одной модели с одинаковыми комплектующими, но множество различных сборок, у нее появляется необходимость в выделении различных факторов, которые влияют на цену ноутбука.
Во-первых, компании следует досконально исследовать, что в сущности влияет на цену (потребительскую ценность) ноутбука. Вполне очевидно, что производительность, вес, компактность, надежность – это то, что хочет потребитель, однако в каких объективных характеристиках, желательно количественно выражаемых, это отражено? И какой именно характер влияния на цену, предположительно, имеют эти переменные? Предположим, потребитель N готов купить ноутбук производительностью X единиц за Y рублей. Но если производительность была бы в два раза выше, готов ли потребитель заплатить в два раза больше? Или, быть может, он будет готов платить в 4 раза больше или наоборот, не более чем в 0,5 раз больше? Вероятно также, что это может зависеть от базы расчета (то есть при разных Y прирост будет влиять по-разному). Например, в модели прогнозирования цены на аккаунты сразу было обозначено подозрение на экспоненциальную связь, которая обусловлена спецификой сущности «внутриигрового прогресса».
Далее, компании следует приступить к сборке данных. В данной ситуации наиболее рационально будет попросить данные у таких компаний, как, например DNS, М.Видео и Эльдорадо. Затем следует привести все данные к единому виду.
По окончании сбора данных следует выбрать ключевые фактические детерминанты. В случае с ноутбуком это однозначно может быть процессор, величина ОЗУ, тип ОЗУ, тип матрицы, частоты монитора, емкости аккумулятора и т.п. При этом процессор сам по себе будет являться следствием уже непосредственно его характеристик (количество ядер, потоков, кэш-памяти и т.п.), то же самое с видеокартой. Поэтому не исключено, что в рамках нормализации исходных данных можно будет для процессора посчитать совокупную величину «производительность» или что-то подобное. После окончательного приведения в порядок исходных данных можно запускать тот же алгоритм: построение тепловой карты корреляции, scatter-plot графиков, распределение плотности и т.п. Причем отметим, что некорректное изначальное распределение плотностей, вызванное мощной правосторонней асимметрией распределения с высоким значения куртозиса будет в сделках по любому товару – ведь везде есть тенденция большего числа покупок на относительно средние цены, и меньшие числа покупок на дорогие варианты товара (ноутбуки за 40-60 тысяч покупают гораздо чаще, чем ноутбуки за 500 тысяч, что вполне логично).
После окончания преобразования данных компании следует протестировать различные модели, как однофакторные (как в случае модели с прогнозированием цены на аккаунты, поскольку была обнаружена мощная мультиколлинеарность), так и многофакторные, если это необходимо. Рассматривая R-квадрат, а также значения остатков, компания должна, исходя из своего отношения к ошибкам первого и второго рода внести корректировки [5, c 356].
Заключение
В заключение следует отметить, что в рамках данного исследования была разработана статистически значимая модель прогнозирования рыночной цены товара на основе анализа выбранного признака. Модель демонстрирует минимальную смещенность оценок и обеспечивает высокую точность предсказаний.
В процессе разработки модели был сформулирован алгоритм первичной обработки данных, включающий анализ распределений переменных и коррекцию, направленную на нормализацию данных. В ходе анализа выявлены аномалии в распределении цен, характеризующиеся высокой плотностью наблюдений в околомедианных интервалах. Для устранения данной асимметрии предложены методы нормализации, что позволило повысить точность оценки.
В исследовании также обозначены условия применимости модели за пределами конкретного рынка цифровых товаров. Разработанный алгоритм может быть успешно адаптирован к оценке стоимости базовых и вещественных товаров при соблюдении соответствующих предпосылок. Представленный подход обладает гибкостью и воспроизводимостью, что позволяет использовать его в различных экономических и рыночных контекстах.
Источники:
2. Анализ российского рынка маркетплейсов. [Электронный ресурс]. URL: https://tiec.mgimo.ru/upload/ckeditor/files/tiec-8-2023_sergeeva.pdf (дата обращения: 25.03.2025).
3. Анализ финансовых показателей российских маркетплейсов. [Электронный ресурс]. URL: https://fundamental-research.ru/article/view?id=43660 (дата обращения: 25.03.2025).
4. Багиев Г. Л., Тарасевич В. М., Анн Х. Маркетинг. - СПб.: Питер,, 2022. – 736 c.
5. олубков Е. П. Маркетинговые исследования: теория, методология и практика. - М.: Финпресс, 2018. – 464 c.
6. Динамика финансовых показателей ООО Вайлдберриз. [Электронный ресурс]. URL: https://checko.ru/company/1067746062449/finances/dynamics?alpha=2110&delta= (дата обращения: 09.12.2024).
7. Динамика финансовых показателей ООО Интернет Решения. [Электронный ресурс]. URL: https://checko.ru/company/1027739244741/finances/dynamics?alpha=2110&delta= (дата обращения: 06.12.2024).
8. Коровина М. А., Довтаев С.-а Ш. Анализ финансовых результатов экономического субъекта // Деловой вестник предпринимателя. – 2023. – № 3. – c. 11.
9. Котлер Ф., Келлер К. Л. Маркетинг менеджмент. - СПб.: Питер, 2021. – 816 c.
10. Куликова О. М., Суворова С. Д. Маркетплейс: бизнес-модель современной торговли // Инновационная экономика: перспективы развития и совершенствования. – 2020. – № 6. – c. 4-6.
11. Кузьмин Д. В. Микроэкономика. / учебное пособие для иностранных студентов экономических факультетов вузов. - М.: Изд-во РУДН, 2007. – 94-96 c.
12. Любушин Н. П., Леонтьев Н. Л. Анализ финансово-хозяйственной деятельности предприятия. - М.: Юрайт, 2020. – 414 c.
13. Мэнкью Н. Г. Принципы экономики. - СПб.: Питер Ком, 1999. – 329-330 c.
14. Моделирование потребительского поведения как фактор развития рынка. [Электронный ресурс]. URL: https://www.m-economy.ru/art.php?nArtId=1190 (дата обращения: 25.03.2025).
15. Оразов А. А. Моделирование и прогнозирование потребительского поведения при изменении экономических условий // Вестник науки. – 2024. – № 3. – c. 7-9.
16. Румянцева Е. Е., Успенский А. В. Экономика фирмы. - М.: Инфра-М, 2019. – 368 c.
17. Фатхутдинов Р. А. Стратегический менеджмент. - М.: Дело, 2023. – 480 c.
18. Brawl Stars (страница игры на Play Market). [Электронный ресурс]. URL: https://play.google.com/store/apps/details?id=com.supercell.brawlstars&hl=ru (дата обращения: 06.12.2024).
19. Playerok.com - маркетплейс цифровых товаров и услуг (данные по сделкам выгружены за март-май 2024 года при помощи API). [Электронный ресурс]. URL: https://playerok.com/ (дата обращения: 05.12.2024).
20. Outlier Detection & Removal. How to Detect & Remove Outliers. [Электронный ресурс]. URL: https://www.analyticsvidhya.com/blog/2021/05/feature-engineering-how-to-detect-and-remove-outliers-with-python-code/ (дата обращения: 10.12.2024).
Страница обновлена: 16.07.2026 в 09:34:39
Download PDF | Downloads: 47
Prediction and analysis of how marketplaces set prices for digital goods
Reshetnikova M.S., Prikaznov P.A.Journal paper
Russian Journal of Innovation Economics
Volume 15, Number 2 (April-June 2025)
Abstract:
Digital assets have become an integral part of the modern economy, especially with the rapid development of marketplaces that serve as platforms for buying and selling such assets. With the growing popularity of video games and the increasing volume of trading in game accounts, the need for accurate valuation of these assets has emerged. However, the process of pricing such assets is complicated by a variety of factors.
The article develops a model for predicting the value of digital goods on marketplaces using statistical and econometric methods. The study revealed an exponential relationship between the account ranking and its price, which significantly improved the prediction accuracy. To increase the reliability of the model, data normalization and optimization methods were applied.
Special attention is given to the analysis of the factors influencing the market value of gaming accounts and the evaluation of the accuracy of the predictions. The results obtained demonstrate the universality of the proposed approach and its potential adaptation for the valuation of other digital and physical goods in different marketplaces.
Keywords: digital goods, marketplaces, e-commerce, econometric method
JEL-classification: O31, O32, O33
References:
Abryutina M. S., Grachev A. V. (2019). Analysis of financial and economic activity of the enterprise
Bagiev G. L., Tarasevich V. M., Ann Kh. (2022). Marketing
Fatkhutdinov R. A. (2023). Strategic management
Korovina M. A., Dovtaev S.-a Sh. (2023). Analysis of financial results of an economic entity. Delovoy vestnik predprinimatelya. (3). 11.
Kotler F., Keller K. L. (2021). Marketing Management
Kulikova O. M., Suvorova S. D. (2020). Marketplace: the business model of the modern trade. Innovation economy: prospects for development and improvement. (6). 4-6.
Kuzmin D. V. (2007). Microeconomics
Lyubushin N. P., Leontev N. L. (2020). Analysis of financial and economic activity of the enterprise
Menkyu N. G. (1999). Principles of economics
Orazov A. A. (2024). Modeling and forecasting consumer behavior under changing economic conditions. Vestnik nauki. (3). 7-9.
Outlier Detection & RemovalHow to Detect & Remove Outliers. Retrieved December 10, 2024, from https://www.analyticsvidhya.com/blog/2021/05/feature-engineering-how-to-detect-and-remove-outliers-with-python-code/
Rumyantseva E. E., Uspenskiy A. V. (2019). The economics of the company
olubkov E. P. (2018). Marketing research: theory, methodology and practice