Python-программа реализации метода пошагового уточнения ранжирования объектов: направления повышения потребительского качества программного продукта
Хубаев Г.Н.1, Щербакова К.Н.2, Петренко Е.А.1
1 Ростовский государственный экономический университет (РИНХ), Россия, Ростов-на-Дону
2 Фгану НИИ Специализированные вычислительные устройства защиты и автоматика, Россия, Ростов-на-Дону
Скачать PDF | Загрузок: 65
Статья в журнале
Информатизация в цифровой экономике (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 1, Номер 3 (Июль-сентябрь 2020)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=48125396
Аннотация:
Описаны новизна, преимущества и особенности программной реализации на алгоритмическом языке Python метода пошагового уточнения ранжирования объектов, приведен пример апробации созданной Python-программы, указаны направления повышения потребительского качества программного продукта
Ключевые слова: ранжирования объектов, Python, программная реализация, область применения
Введение. Как отмечают эксперты [1], «российские специалисты в области информационных технологий высоко ценятся во всем мире. Но лишь единицы из тысяч ИТ-продуктов, разработанных в нашей стране, успешно продаются на глобальном рынке». Неудивительно, что и ничтожно мало поступлений в доходную часть бюджета страны от экспорта ИТ-продуктов. Примечательно, что и цена, и число продаж зачастую мало зависят от реального качества представленного на рынок программного продукта (ПП). И при этом лишь незначительную долю ПП можно считать относительно завершенными рыночными продуктами. Одновременно в России «продолжает снижаться доля разработки программного обеспечения – в 2019 г. она составила 10 % против 14 % в 2018 г.» [2]. И это притом, что и школьники, и студенты постоянно и очень успешно выступают на международных конкурсах по информатике. Правда, в [3] утверждается, что именно ошибки в выборе приоритетных направлений развития экономики страны привели к ослаблению конкурентных рыночных позиций российского ИТ-бизнеса. И даже сегодняшние реальные усилия государства по финансовому подкреплению индустрии ИТ не оказали заметного влияния на успехи российского ИТ-бизнеса на внешних и внутреннем рынках.
Но почему не растет столь необходимый для ускоренного социально-экономического развития страны объем продаж российских ИТ-товаров? Ведь, как показали наши исследования [4], показатель «ВВП на одного работающего (в долларах.)» статистически значимо зависит именно от приращения объема экспорта услуг ИКТ (за три года, в % от экспорта услуг – лаг составляет три года; статистические характеристики: b1/Ϭb1 =23,2; R2ск =0,87; Fкр=539,9. Значимость Fкр=1,25E-08; Германия), а показатель «ВВП на душу населения, ППС» зависит от приращения величины сборов за использование интеллектуальной собственности (за один год, в текущих ценах – лаг составляет один год; статистические характеристики: b1/Ϭb1=20,9; R2ск=0,87; Fкр=436,5. Значимость Fкр=2,89E-08; Швеция). И как известно, компьютерная программа, в отличие от большинства других товаров, является практически полностью интеллектуальным продуктом.
В такой ситуации для укрепления конкурентных рыночных позиций российского ИТ-бизнеса на внутреннем и внешнем рынках представляется очевидной необходимость активизировать и интенсифицировать процесс разработки конкурентоспособных, обладающих новизной и прикладной полезностью отечественных программных продуктов, созданных с использованием оригинальных алгоритмов.
В статье, базируясь на ранее выполненных исследованиях, описаны новизна, преимущества и прикладная полезность метода пошагового уточнения ранжирования объектов, особенности программной реализации метода на алгоритмическом языке Python, приведен пример апробации созданной Python-программы, указаны направления совершенствования программного продукта для повышения его потребительского качества.
1. Новизна, преимущества, фрагмент алгоритма реализации метода. Экспертное упорядочение (ранжирование) объектов широко используется в практике человеческой деятельности. Ранжируют спортсменов (теннисистов, шахматистов), экспертов, предприятия, административно-территориальные образования, варианты внешнего вида объекта в процессе проектирования и т.д. С развитием научно-технического прогресса, с повсеместным внедрением искусственного интеллекта интенсивность использования экспертных методов вряд ли уменьшится. Ведь выбор цели и критериев для оценки вероятности ее достижения (или степени приближения к цели) еще долгое время будет оставаться в ведении человека.
Метод пошагового уточнения ранжирования объектов (ПУРО), предложенный и описанный в [5], предназначен для использования в процессе экспертизы. На первом этапе организаторы экспертизы формируют состав экспертной группы. Для этого из ранее созданной базы данных (БД), содержащей сведения о характеристиках (компетенциях) экспертов-участников экспертиз-опросов в конкретных предметных областях, осуществляется (с использованием таблицы или датчика случайных чисел) отбор группы экспертов для участия в реализации процедуры ранжирования конкретных объектов, выбранных организаторами экспертизы. Всем экспертам вновь созданной группы присваивают идентификаторы также с использованием таблицы или датчика случайных чисел.
1.1. Анализ особенностей и перспективной полезности метода. Отличия метода:
1. Дельфийская процедура используется при ранжировании экспертами характеристик объектов (а не для прогнозирования будущего).
2. Для количественного анализа степени сходимости мнений экспертов после каждого тура опросов, выявления согласованных групп экспертов и оценки целесообразности завершения экспертизы используется расстояние Кемени (мера близости на отношениях линейного порядка), а в качестве результирующего ранжирования – медиана Кемени.
3. Для группировки участников экспертного опроса, у которых могут оказаться схожими взгляды относительно вариантов ранжирования рассматриваемых характеристик, устанавливаются пороговые значения расстояния Кемени между ответами экспертов, исходя из вероятности совпадения их мнений, например, близкой к 0.8; 0.9; 0.95; 0.99.
4. Для поиска в каждой из образовавшихся групп экспертов согласованного с членами группы ранжирования (упорядочения) характеристик рассчитывается медиана Кемени.
Преимущества метода:
1. Корректность метода (теорема о корректности доказана в 1978 году – «медиана Кемени – единственное результирующее строгое ранжирование, являющееся нейтральным, согласованным и кондорсетовым»; пояснение Г.Х. с ориентацией на концепцию Жана А.Н. Кондорсе: «кондорсетовым» – разумным, соответствующим «здравому смыслу»).
2. Повышение точности результатов экспертизы за счет наличия обратной связи при реализации каждого последующего тура.
3. При использовании пошагового уточнения ранжирования характеристик сохраняются известные преимущества и дельфийской процедуры (анонимность и возможность ознакомления с объяснениями, представленными в защиту сильно отличающихся ответов), и алгоритма поиска согласованного упорядочения объектов – корректный расчет медианы и расстояния Кемени.
4. Совместное использование и дельфийской процедуры, и предложенного Кемени корректного подхода к упорядочению функций позволило:
- получить содержательно приемлемый количественный критерий для обоснованного завершения экспертизы – устанавливается определенная величина относительного (например, 5 %) изменения суммарного расстояния Кемени;
- формировать группы экспертов, ориентируясь на выбранные (в зависимости от степени согласованности мнений) пороговые значения расстояния Кемени, и исследовать причины взаимосвязи оценок экспертов;
- находить согласованное с членами каждой группы экспертов упорядочение характеристик, рассчитав точно или приближенно медиану Кемени.
Прикладные области применения метода описаны в [6–8] (Khubaev, 2017; Khubaev, 2019) и др. работах, включая использование в учебном процессе, при расчетах совокупной стоимости владения товаром, при сравнении:
– вариантов внешнего вида объектов (проектируемых и/или продаваемых товаров: программных продуктов, сайтов, автомобилей и др.),
– вариантов решения сложных проблем;
– при ранжировании лиц, принимающих решения (ЛПР), участников различных конкурсов и др. по составу компетенций и др. характеристик.
1.2. Фрагмент алгоритма реализации метода. Рассмотрим условный пример. Требуется тремя экспертами упорядочить 5 (пять) объектов. Пусть каждый из объектов – это один из вариантов (Vi) интерфейса программного продукта – ИС, веб-приложения и др.; экспертов-участников экспертного опроса обозначим буквами E1, E2, E3.
Шаг 1. Всем участвующим в экспертизе потенциальным пользователям-экспертам показывают исходные объекты и просят проранжировать (выполнить упорядочение по степени привлекательности или полезности, понятности, удобства использования и т.д.) все подготовленные варианты интерфейса ПП (в данном случае – всего 5 вариантов).
Шаг 2. Каждое ранжирование Ei представляют в виде матрицы упорядочения в канонической форме: 1, если Vi предшествует Vj; -1, если Vj предшествует Vi, или 0, если Vi и Vj равноценны.
Шаг 3. Рассчитывают расстояния между ранжированиями E1-E3, используя формулу Кемени:
dij=1/2∑∑l Fij – Rijl,
где Fij и Rij – матрицы упорядочения в канонической форме.
Предположим теперь, что процедура пошагового упорядочения множества объектов (вариантов интерфейса) успешно завершена. Получена матрица расстояний Кемени между всеми ранжированиями экспертов. Теперь необходимо корректно выделить согласованные группы ответов экспертов, т.е. реализовать процедуру поиска согласованных групп ответов экспертов (классов экспертов) и выбора для этой выделенной группы согласованного упорядочения ответов.
Пусть получены расстояния Кемени между ранжированиями {dij}.
Шаг 4. Перевести элементы матрицы расстояний в относительные единицы по формуле d0ij=dij/dmax. Максимальное расстояние между ранжированиями экспертов равно dmax=m(m-1). Получим таблицу расстояний Кемени в относительных единицах {d0ij}.
Шаг 5. Выбрать, исходя из реальной степени согласованности ответов экспертов, пороговое значение расстояния dпор.
Шаг 6. Преобразовать матрицу относительных значений расстояния Кемени {d0ij} в соответствии с выбранным пороговым значением dпор. В процессе такого преобразования каждое значение d0ij сопоставляется с dпор, и если 0<d0ij≤dпор, то ставится 1, в противном случае – 0.
Шаг 7. Выполняется поиск ранжирования, максимально согласованного с выделенной группой взаимосвязанных ответов. Причем согласованное ранжирование должно быть точкой, наиболее согласующейся со множеством возможных упорядочений. Однако при достаточно большом числе экспертов расчеты можно существенно упростить, если ориентироваться только на ответы участников экспертизы. Ведь если выборка достаточно велика, то вероятность получить искомое согласованное упорядочение близка к единице. С этой целью рассчитываются величины Σdij и Σd2ij. Ранжирование эксперта, у которого величина Σd2ij. минимальна, считается максимально согласованным с выделенной группой ответов.
Шаг 8. Определяют расстояние между всеми участниками опроса – потенциальными пользователями и медиану Кемени (почти точно, если экспертов ≥20):
Таблица 1
Результаты расчета после первого тура опросов
|
Dij
|
E1
|
E2
|
E3
|
Сумма
расстояний
По строкам |
Сумма
квадратов расстояний
По строкам |
Медиана,
т.е. самое
согласованное со всеми участниками ранжирование |
|
E1
|
0
|
6
|
4
|
10
|
36+16=52
|
|
|
E2
|
6
|
0
|
2
|
8
|
36+4=40
|
|
|
E3
|
4
|
2
|
0
|
6
|
16+4=20
|
Медиана,
так как сумма
квадратов расстояний минимальна |
|
|
Общая
сумма после
Первого тура (шага) равна 24 |
| ||||
В том случае, если обнаружено несколько групп взаимосвязанных ранжирований, то определяют медианы для каждой из образовавшихся групп.
На этом ПЕРВЫЙ ТУР (ШАГ) завершен. Всех участников экспертного опроса информируют о том, как выглядит общая (для всех участников) МЕДИАНА, и просят при желании изменить свои ранжирования первого тура.
Шаг 9. Определяют, при каком изменении (в %) общего (суммарного) рассогласования можно прекращать опросы. Устанавливают пороговую величину рассогласования.
Предположим теперь, что, ознакомившись с результатами первого тура, участник E1 изменил свое первоначальное ранжирование. Вновь выполняют все перечисленные шаги до тех пор, пока на очередном шаге изменение общего рассогласования окажется меньше установленного порогового значения.
[Пояснение. В анкетах очередного тура, рассылаемых участникам экспертизы, проставляются: наименования ранжируемых объектов, диапазон рангов в предыдущем туре по каждому объекту, средние ранги объектов среди всех опрошенных и объяснения, представленные в защиту ответов, отличающихся на ≥50 % от среднего ранга объекта среди всех опрошенных – по отношению к количеству ранжируемых объектов. Пусть, например, количество ранжируемых объектов V равно 10, рассчитанный после очередного тура средний ранг объекта Vj равен 3. Поэтому всех экспертов, указавших объекту Vj ранги ≥8, просят объяснить причины отклонения их ответов от мнения большинства, так как (8–3)/(количество объектов)*100 %=50 %].
Пример апробации созданной Python-программы. После очередного шага изменение суммарного рассогласования (суммарного расстояния Кемени между всеми ранжированиями) не превысило установленную пороговую величину (обычно в диапазоне 3÷10 %). Окончательный результат ответов экспертов представлен в таблице 2.
Таблица 2
Результаты экспертизы на последнем шаге
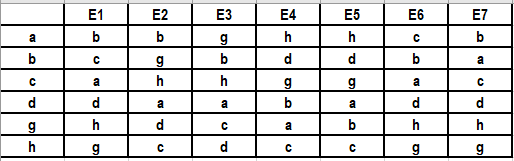
Рисунок 1. Окно приложения
![]()
Рисунок 2. Доступные таблицы для просмотра результатов
Расстояния Кемени между всеми ранжированиями экспертов сформированы в виде таблицы 3.
Таблица 3
Окончательные результаты расчетов с оценкой расстояний Кемени между всеми ранжированиями экспертов

При относительной величине порогового значения расстояния Кемени dп0=0,15 (вероятность взаимосвязи ≥0,85) взаимосвязь между ранжированиями имеет вид: E1 ↔ E6 ↔ E7; E2 ↔ E3; E4 ↔ E5.
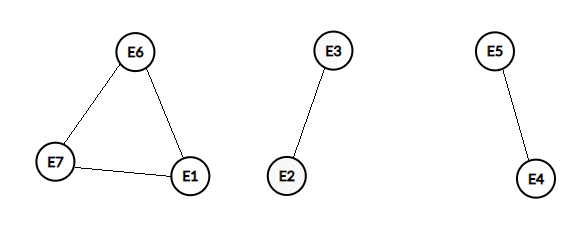
Рисунок 3. Графы взаимосвязи между ранжированием экспертов E1 – E7
Если, например, предположить, что на рисунке 3 представлены результаты интуитивно согласованного коллективного выбора разными группами экспертов варианта расширения состава, например: 1) функций товара конкретного назначения или 2) компетенций, которыми должен обладать специалист в определенной предметной области и т.д., то каждый граф можно интерпретировать как одну из групп экспертов с согласованным мнением относительно варианта расширения состава характеристик рассматриваемого объекта. Причем ранжирование характеристик осуществляется, исходя из уровня их полезности, значимости, важности, разными группами экспертов. Здесь каждый граф – это группа (кластер, класс) экспертов с минимальным расстоянием Кемени между упорядочениями характеристик объекта экспертами этой группы).
2. Направления повышения потребительского качества созданной Python-программы
Здесь мы определим перечень первоочередных задач, решение которых позволит повысить потребительское качество разработанной Python-программы. Прежде всего, необходимо:
1. Выполнить сравнительный анализ и обоснованный выбор варианта интерфейса созданного ПП. Для абсолютного большинства покупателей-пользователей исключительно актуальной является задача сравнительной оценки и выбора варианта дизайна объекта. В [9] (Khubaev, 2011) предложены корректные процедуры, ориентированные на пошаговое использование расстояния и медианы Кемени и непараметрических методов статистики при сравнении вариантов интерфейса программного продукта, внешнего вида любого художественно оформленного объекта (см. также [10] (Khubaev, 2016)). Эти методы, включая метод ПУРО, будут использованы при выборе варианта интерфейса созданной компьютерной программы.
2. Выполнить сравнительную оценку потребительского качества руководства пользователя (инструкции, справочной системы) по критерию минимума затрат времени покупателя-пользователя на изучение функциональных возможностей ПП. Как известно, затраты времени на освоение нового учебного материала – учебной дисциплины, руководства пользователя, методических рекомендаций и др. зависят от уровня начальной (исходной) подготовки обучаемого, от его способностей, от степени мотивации, от условий обучения, сложности изучаемого материала и других факторов. Задача определения затрат времени на получение знаний, на реальное освоение нового учебного материала исключительно актуальна для всех отраслей общественного производства и науки – ведь в условиях непрерывного ускорения НТП каждый человек вынужден учиться всю сознательную жизнь.
В процессе анализа содержания Руководства пользователя необходимо ответить на ряд вопросов: насколько легко непрофессионалу в области ИТ-технологий понять содержание инструкции для покупателя-пользователя? как в каждом конкретном случае оценить величину затрат времени на изучение Руководства пользователя? как определить вероятность практического освоения конкретного материала за заданное время?
В [11] предложена универсальная методика оценки затрат времени на получение знаний, включающая методы и инструментальные средства для расчета статистических характеристик распределения времени освоения любого учебного материала при различных условиях формирования исходной информации: в процессе анкетирования обучаемых, по данным натурных экспериментов и по результатам экспертных опросов. Статистические характеристики затрат времени (математическое ожидание, дисперсию, коэффициент вариации, эксцесс, асимметрию) и распределение (в виде таблиц и гистограмм) оценивают путем имитационного моделирования. На основании результатов имитационного моделирования легко определить доверительные границы для конкретного значения затрат времени на изучение Руководства пользователя.
3. Рассчитать величину совокупной стоимости владения (ССВ) программным продуктом. Большинство программных систем (программных продуктов, информационных систем) относят к объектам длительного пользования. В понятие IT-затрат входят затраты, связанные с приобретением, внедрением и использованием ПП. Эти затраты формируют совокупную стоимость владения программной системой (Total Cost of Ownership –TCO), включающей первоначальные и последующие затраты, определяя их как единые затраты на программную систему в процессе ее создания и эксплуатации.
Для расчета ССВ (см. [12, 13] (Khubaev, 2010; Khubaev, Rodina, 2012)):
– выделяют с использованием метода пошагового уточнения ранжирования объектов (ПУРО) упорядоченный перечень основных затрат ресурсов;
– определяют, используя метод пошагового уточнения значений показателя с оценкой характеристик распределения (ПУЗ-ОХР), статистические характеристики (математическое ожидание, стандартное отклонение, коэффициент вариации, медиану, асимметрию, эксцесс) и распределение (в виде гистограмм и таблиц) совокупной стоимости владения ПП. Результаты расчета позволяют оценивать вероятность попадания ССВ в конкретный диапазон значений (примеры реальных расчетов ССВ представлены в [13] (Khubaev, Rodina, 2012)).
Описанные методы, будучи оригинальными и обладая очевидной прикладной полезностью, реализованы в виде программ для ЭВМ и использованы в т.ч. при разработке прикладных программ в различных предметных областях.
4. Определить затраты времени и трудовых ресурсов на получение интересующего покупателя-пользователя результата, например, на выполнение и каждой функции, и полного состава функций при использовании как представленных на рынке ПП, так и создаваемого ПП (в условиях применения конкретного состава системного программного обеспечения и технических средств).
В [14, 15] (Khubaev, 1995; Khubaev, 2012) предложена оригинальная методика, позволяющая корректно количественно оценивать и сопоставлять затраты на применение ПП одного назначения, сравнивать ПП по экономическим критериям. При использовании методики впервые появляется возможность корректно, более обоснованно и с большей достоверностью осуществлять следующее:
– соотносить потребности конкретного пользователя с возможностями существующих и проектируемого ПП;
- выделять из числа выполняемых вручную операций те, которые нужно реализовать в новой версии ПП в первую очередь, чтобы минимизировать затраты времени и трудовых ресурсов на решение задачи;
- определять, выполнение каких машинных операций следует ускорить, например, перепрограммировав, модифицировав структуру БД и т.п.;
- рассчитывать экономическую целесообразность автоматизированного выполнения конкретной операции, решения задачи (комплекса задач), сопоставив затраты на ручной и машинный варианты;
- выбирать оптимальную структуру БД (информационной системы) в процессе проектирования или модификации, базируясь, например, на результатах формализованного анализа информационных потребностей пользователей и др.
Кроме того, в технической документации абсолютного большинства рыночных ПП отсутствуют сведения, позволяющие оценить выходные характеристики программной системы и их динамику при изменении объемов входной информации, структуры БД, состава комплекса технических средств, СУБД, языка программирования и т.д. Более того, в литературе по проектированию и анализу ИС, ПП и БД практически не описаны способы корректного получения таких данных, определения их прогнозной ценности, доверительных границ для рассчитанных статистических характеристик.
В [16] (Khubaev, 1999) применительно к проблемам проектирования и анализа ИС, ПП и БД впервые:
- выявлены и систематизированы важнейшие особенности программных продуктов как объектов активного экспериментирования;
- описаны свойства факторов, влияющих на выходные характеристики ПП. Показано, что большинство факторов являются управляемыми, количественными, независимыми; они оказывают непосредственное (прямое) воздействие на исследуемый объект;
– определены основные требования к свойствам моделей, формируемым по результатам активных экспериментов;
– выделены критерии выбора плана эксперимента при исследовании ПП;
– даны рекомендации по применению конкретных планов для постановки экстремальных по выбранным критериям экспериментов.
5. Оценить степень защищенности проектируемого ПП, рассчитав предварительно ущерб от кражи интеллектуальной собственности путем копирования текста программы для ЭВМ и от реализации других угроз защищаемому объекту. Ведь ПП, будучи созданным практически полностью в результате интеллектуального труда разработчиков (в отличие от большинства других товаров), требует определенных, зачастую значительных затрат ресурсов на защиту от кражи результата интеллектуального труда, заключенного в ПП.
Важнейшим потребительским свойством программных продуктов для защиты информации (исполняемых программ, БД, текстовых файлов) является качество выполнения защитных функций. Это качество можно характеризовать величиной среднего значения, дисперсии и законом распределения времени вскрытия защиты, значением вероятности вскрытия защиты за определенное время либо, наоборот, вероятности того, что за заданное время защита не будет вскрыта.
По аналогии с другими ПП при сравнительной оценке характеристик потребительского качества программных систем защиты информации вся работа по вскрытию (взлому) защиты также может быть представлена в виде последовательности элементарных операций. Для каждой такой операции определяются статистические характеристики и закон распределения времени ее выполнения, а затем с использованием имитационного моделирования или аналитическими методами оцениваются вероятностные характеристики и законы распределения времени решения всей задачи по вскрытию защиты.
Причем основные компоненты методики оценки производительности ПП, т.е. оценки затрат времени пользователя на реализацию функций ПП, остаются неизменными (см., например, [14–20] (Khubaev, 1995; Khubaev, 2012; (Khubaev, 1999; Khubaev, 2002; Khubaev, 2008; Khubaev, 2009; Khubaev, 2012)).
[Замечание. При оценке времени вскрытия защиты ПП от копирования с ориентацией на метод [20] (Khubaev, 2012) следует учитывать результаты исследований А.М. Костина [21] (Kostin, 2009). Эксперименты со студентами выпускных курсов специальностей ИТ и защиты информации показали, что величина правосторонней асимметрии распределения затрат времени на вскрытие защиты одного и того же ПП разными исполнителями может отличаться в десятки раз].
Заключение
1. Описаны новизна и прикладные преимущества метода пошагового уточнения ранжирования объектов, представлен фрагмент алгоритма разработки компьютерной программы, рассмотрен пример программной реализации метода на алгоритмическом языке Python.
2. Определены основные направления повышения потребительского качества созданного программного продукта, включая:
–обоснованный выбор варианта интерфейса Python-программы,
– оценку потребительского качества руководства пользователя (инструкции, справочной системы) по критерию минимума затрат времени покупателя-пользователя на изучение функциональных возможностей компьютерной программы,
- оценку совокупной стоимости владения (ССВ) программным продуктом,
– оценку степени защищенности ПП, рассчитав предварительно ущерб от кражи интеллектуальной собственности путем копирования текста программы для ЭВМ и от реализации других угроз защищаемому объекту,
– определение затрат времени и трудовых ресурсов на получение интересующего покупателя-пользователя результата.
Источники:
2. Рынок ИТ: итоги 2019. [Электронный ресурс]. URL: https://www.cnews.ru/reviews/rynok_it_itogi_2019 (дата обращения: 20.02.2022).
3. Хубаев Г. Н. Как уменьшить вероятность ошибок при выборе приоритетных направлений социального и экономического развития страны // Бюллетень науки и практики. – 2019. – № 12. – c. 265-280.
4. Хубаев Г.Н. Прогнозирование динамики индикаторов уровня развития экономики страны: модели, методы, инструментальные средства (на примере Германии, России и Швеции) // Вестник юргту (нпи). – 2020. – № 5. – c. 224-240.
5. Хубаев Г.Н. Об одном методе получения и формализации априорной информации при отборе значимых факторов. / Сб. докладов итоговой научной конференции Ростовского института народного хозяйства. Вып. 1. - Ростов-на- Дону, 1973. – 238-244 c.
6. Khubaev G. Expert review: method of intuitively agreed choice // 5th International Conference «Economy modernization: new challenges and innovative practice» (November 12, 2017, Sheffield, UK). P. 65-80
7. Хубаев Г.Н. Методы формирования согласованного коллективного выбора в процессе экспертизы (на примере ранжирования способов решения сложных проблем) // Бюллетень науки и практики. – 2017. – № 7 (20). – c. 59-77.
8. Хубаев Г.Н. Универсальный метод оптимизации состава характеристик объектов // Бюллетень науки и практики. – 2019. – № 5. – c. 265-275.
9. Хубаев Г.Н. Сравнение вариантов дизайна объекта: модели и алгоритмы // Вестник Ростовского государственного экономического университета (РИНХ). – 2011. – № 3. – c. 167-174.
10. Хубаев Г.Н. Проектирование объектов различного назначения: сравнительная оценка вариантов внешнего вида // Содружество (Научный российско-китайский журнал). – 2016. – № 8 (7). – c. 76-80.
11. Khubaev Georgy. Assessment of the time required for the acquisition of knowledge // 5th International Scientific Conference “Applied Sciences and technologies in the United States and Europe: common challenges and scientific findings” (New York, USA; February 12, 2014). Section 6. Pedagogy. New York, 2014. Pp. 86-90
12. Хубаев Г.Н. Расчет совокупной стоимости владения программным продуктом: методическое и инструментальное обеспечение // Вопросы экономических наук. – 2010. – № 5(44). – c. 82-87.
13. Хубаев Г., Родина О. Модели, методы и программный инструментарий оценки совокупной стоимости владения объектами длительного пользования (на примере программных систем). / монография. - Saarbrucken: LAP LAMBERT Academic Publishing, 2012. – 370 c.
14. Хубаев Г.Н. Методика экономической оценки потребительского качества программных средств // Программные продукты и системы. – 1995. – № 1. – c. 2-8.
15. Хубаев Г.Н. Оценка резервов снижения ресурсоёмкости товаров и услуг: методы и инструментальные средства // Прикладная информатика. – 2012. – № 2(38). – c. 111-117.
16. Хубаев Г.Н. Информационные и программные системы как объекты активного экспериментирования // Программные продукты и системы. – 1999. – № 2. – c. 2-7.
17. Хубаев Г.Н. Безопасность распределенных информационных систем: обеспечение и оценка // ИЗВЕСТИЯ ВУЗОВ. Северо-Кавказский регион. ТЕХНИЧЕСКИЕ НАУКИ. Спецвыпуск: Математическое моделирование и компьютерные технологии. – 2002. – c. 11-13.
18. Хубаев Г.Н. Оценка времени вскрытия защиты информационных систем: статистический подход // Проблемы экономики. – 2008. – № 6. – c. 136-139.
19. Хубаев Г.Н. Ресурсоемкость продукции и услуг: процессно-статистический подход к оценке // Автоматизация и современные технологии. – 2009. – № 4. – c. 22-29.
20. Хубаев Г.Н. Оценка резервов снижения ресурсоёмкости товаров и услуг: методы и инструментальные средства // Прикладная информатика. – 2012. – № 2(38). – c. 111-117.
21. Костин А.М. Модели и методы оценки трудозатрат на вскрытие защиты от копирования рыночных экономических информационных систем. / автореф. дис.,.. канд экон. наук: 08.00.13. - Ростов-на-Дону, 2009. – 23 c.
Страница обновлена: 01.08.2026 в 13:27:27
Download PDF | Downloads: 65
Python-program for implementing the method of step-by-step refinement of object ranking: directions for improving the consumer quality of a software product
Khubaev G.N., Shcherbakova K.N., Petrenko E.A.Journal paper
Informatization in the Digital Economy
Volume 1, Number 3 (July-september 2020)
Abstract:
The novelty, advantages and features of the software implementation in the algorithmic Python language of the step-by-step refinement method of the objects ranking are described. An example of testing the created Python program is given. Directions for improving the consumer quality of the software product are indicated.
Keywords: object rankings, Python, software implementation, consumer quality
References:
Khubaev G. N. (2019). Kak umenshit veroyatnost oshibok pri vybore prioritetnyh napravleniy sotsialnogo i ekonomicheskogo razvitiya strany [How to reduce the probability of errors when selecting the priority directions of the social and economic development of the country]. Byulleten nauki i praktiki. (12). 265-280. (in Russian).
Khubaev G., Rodina O. (2012). Modeli, metody i programmnyy instrumentariy otsenki sovokupnoy stoimosti vladeniya obektami dlitelnogo polzovaniya (na primere programmnyh sistem) [Models, methods and software tools for estimating the total cost of ownership of durable objects (using the example of software systems)] (in Russian).
Khubaev G.N. (1973). Ob odnom metode polucheniya i formalizatsii apriornoy informatsii pri otbore znachimyh faktorov [On one method of obtaining and formalizing a priori information in the selection of significant factors] (in Russian).
Khubaev G.N. (1995). Metodika ekonomicheskoy otsenki potrebitelskogo kachestva programmnyh sredstv [Methodology of economic assessment of consumer quality of software]. Programmnye produkty i sistemy. (1). 2-8. (in Russian).
Khubaev G.N. (1999). Informatsionnye i programmnye sistemy kak obekty aktivnogo eksperimentirovaniya [Information and software systems as objects of active experimentation]. Programmnye produkty i sistemy. (2). 2-7. (in Russian).
Khubaev G.N. (2002). Bezopasnost raspredelennyh informatsionnyh sistem: obespechenie i otsenka [Security of distributed information systems: provision and evaluation]. IZVESTIYa VUZOV. Severo-Kavkazskiy region. TEKhNIChESKIE NAUKI. Spetsvypusk: Matematicheskoe modelirovanie i kompyuternye tekhnologii. 11-13. (in Russian).
Khubaev G.N. (2008). Otsenka vremeni vskrytiya zashchity informatsionnyh sistem: statisticheskiy podkhod [Assessment of the opening time of information systems protection: statistical approach]. The problems of Economy. (6). 136-139. (in Russian).
Khubaev G.N. (2009). Resursoemkost produktsii i uslug: protsessno-statisticheskiy podkhod k otsenke [Resources capacity of production and service: process-statistical approach to valuation]. Avtomatizatsiya i sovremennye tekhnologii. (4). 22-29. (in Russian).
Khubaev G.N. (2010). Raschet sovokupnoy stoimosti vladeniya programmnym produktom: metodicheskoe i instrumentalnoe obespechenie [Calculation of the total cost of ownership of a software product: methodological and instrumental support]. Voprosy ekonomicheskikh nauk. (5(44)). 82-87. (in Russian).
Khubaev G.N. (2011). Sravnenie variantov dizayna obekta: modeli i algoritmy [Comparison of object design options: models and algorithms]. The journal «Vestnik of Rostov state university of economics». (3). 167-174. (in Russian).
Khubaev G.N. (2012). Otsenka rezervov snizheniya resursoyomkosti tovarov i uslug: metody i instrumentalnye sredstva [Evaluating the reserves to reduce resource consumption for producing goods and services: methods and tools]. Applied Informatics. (2(38)). 111-117. (in Russian).
Khubaev G.N. (2012). Otsenka rezervov snizheniya resursoyomkosti tovarov i uslug: metody i instrumentalnye sredstva [Evaluating the reserves to reduce resource consumption for producing goods and services: methods and tools]. Applied Informatics. (2(38)). 111-117. (in Russian).
Khubaev G.N. (2016). Proektirovanie obektov razlichnogo naznacheniya: sravnitelnaya otsenka variantov vneshnego vida [Designing of different objects: comparative assessment of options appearance]. Sodruzhestvo (Nauchnyy rossiysko-kitayskiy zhurnal). (8 (7)). 76-80. (in Russian).
Khubaev G.N. (2017). Metody formirovaniya soglasovannogo kollektivnogo vybora v protsesse ekspertizy (na primere ranzhirovaniya sposobov resheniya slozhnyh problem) [Methods of forming the agreed collective choice in the expertise process (on an example of ranking methods of solving complex problems)]. Byulleten nauki i praktiki. (7 (20)). 59-77. (in Russian).
Khubaev G.N. (2019). Universalnyy metod optimizatsii sostava kharakteristik obektov [A universal method for optimizing the composition of object characteristics]. Byulleten nauki i praktiki. (5). 265-275. (in Russian).
Khubaev G.N. (2020). Prognozirovanie dinamiki indikatorov urovnya razvitiya ekonomiki strany: modeli, metody, instrumentalnye sredstva (na primere Germanii, Rossii i Shvetsii) [Forecasting the dynamics of indicators of the level of development of the country's economy: models, methods, tools (on the example of Germany, Russia and Sweden)]. Vestnik yurgtu (npi). (5). 224-240. (in Russian).
Kostin A.M. (2009). Modeli i metody otsenki trudozatrat na vskrytie zashchity ot kopirovaniya rynochnyh ekonomicheskikh informatsionnyh sistem [Models and methods for estimating labor costs for opening copy protection of market economic information systems] (in Russian).