Модели и алгоритмы генерации синтетических наборов данных для ML
Жуков А.В.1![]() , Жилина Е.В.1
, Жилина Е.В.1![]()
1 Ростовский государственный экономический университет (РИНХ), Россия, Ростов-на-Дону
Скачать PDF | Загрузок: 52
Статья в журнале
Информатизация в цифровой экономике (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 2, Номер 3 (Июль-сентябрь 2021)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=49265553
Аннотация:
В статье разработан алгоритм, позволяющий генерировать синтетические данные для последующего обучения нейронных сетей, а также для наполнения баз данных «фейковыми» BigData с целью нагрузочного тестирования и проведения различных экспериментов. В качестве инструментария разработки применялся язык Python.
Ключевые слова: алгоритм, датасет, GPU, CPU
Введение. В течение последних лет активно развиваются искусственные нейронные сети (ИНС), ключевым моментом в их реализации является их обучение [7] (Krichevskiy, 2019). Без правильно настроенных весов нейронов нейросеть подобна простой связке контейнеров, которая не способна решать практические задачи. Методов обучения на данный момент имеется небольшое количество, но при этом доминирующим фактором является обучение нейронной сети с учителем, где обычно в роли учителя могут выступать заранее сгенерированные датасеты. Каждый раз, находя взаимосвязи в заранее подобранных данных, ИНС обучается с целью, чтобы уже на реальных данных выявить те же зависимости и получить готовое решение. В настоящий момент сама генерация таких датасетов – весьма затруднительное и трудоемокое занятие, ведь такие наборы данных должны удовлетворять двум основным требованиям [2, 3]:
1) данные должны отражать реальное положение вещей в предметной области;
2) данные не должны быть противоречивыми.
Такие данные, как еще их называют, синтетические, генерируются в настоящий момент специальными инструментами/библиотеками на специализированных языках, но во всех случаях используется генерация на CPU (центральном процессоре компьютера), но нет таких экспериментов для генерации данных на GPU (центральном процессоре видеокарты).
Основная часть
Анализируя совокупность существующих программных решений, можно выделить особенности, которые требуют доработки. В основе архитектуры GPU заложен механизм, позволяющий распараллеливать независимые друг от друга вычисления. GPU выполняет малую долю от тех операций, на которые рассчитан центральный процессор компьютера [4]. Но при этом те операции, которые ему доступны, он делает с большой скоростью. В GPU используется большее количество ядер.
Тем не менее центральные процессоры (CPU) более мощные, чем графические. Они спроектированы под более сложную логику и могут без проблем за один такт выполнять более ресурсоемкие операции. CPU работает на более высоких тактовых частотах и при этом имеет возможность управлять вводом/выводом данных от компонентов компьютера. К примеру, CPU может интегрироваться с виртуальной памятью, которая необходима для запуска современных операционных систем. Такое на сегодняшний день недостижимо для GPU.
Учитывая данные отличия между GPU и CPU, можно сделать вывод: генерацию синтетических данных удобнее производить именно на центральном процессоре видеокарты. При генерации любых типов данных каждого последующего значения нет необходимости дожидаться вычисления значения предыдущего, именно поэтому данный процесс можно распараллелить.
Распараллеливание на Python достижимо через внешние библиотеки (табл. 1).
Таблица 1
Программные решения для работы с GPU на Python
|
Программный пакет
|
Что использует
|
Пользовательский язык
для действий на GPU
|
|
PyCUDA
|
CUDA
|
C/C++
|
|
PyOpenCL
|
OpenCL
|
C
|
|
Numba
|
CUDA, HSA, CPU
|
Python
|
|
Theano
|
CUDA,CPU
|
Python
|
|
ArrayFire Python Wrapper
|
ArrayFire
(CUDA,OpenCL,CPU)
|
Python
|
from numba import jit
from numpy import arrange

Листинг 1. Пример выполнения кода на Numba
В данном примере видно, что работа идет в стиле языка Python, за исключением нескольких команд типа @jit, которые указывают на компилируемые функции.
Для реализации алгоритма генерации синтетических данных необходимо определить целевую аудиторию. Но при этом можно сконструировать универсальное решение с типовым набором параметров, которое включает подключения советующих программных библиотек и их компонентов (листинг 2).
import os
import random
from random import randint, choice
import pandas as pd
from numba import cuda # Библиотека Nvidia для работы с GPU
import numpy as np
Листинг 2. Подключение необходимых библиотек
Вычисления на GPU идут при помощи таких абстракций, как потоки, блоки и гриды.
Поток – это назначенная цепочка инструкций, поступающих/текущих в ядре CUDA (реализован по типу конвейера); на одном и том же ядре CUDA может существовать до 32 потоков (в таком случае заполняются все звенья этого конвейера). Это выполнение ядра с заданным индексом. Каждый поток получает и использует свой индекс для доступа элементов в массиве таким образом, что вся совокупность имеющихся потоков совместно обрабатывает все множество данных.
Блок – это группа потоков, которые могут выполняться как последовательно, так и параллельно. При этом выполнением потоков можно управлять вручную. Также есть возможность останавливать потоки в определенной точке в ядре и дождаться, пока все остальные потоки в том же блоке также достигнут точки останова.
Грид – это группа блоков, между которыми в гриде отсутствует любая синхронизация.
В качестве первых типов датасетов выберем генерацию «фейковых» данных с возможностью сохранения в файл необходимого количества записей, данных, а также количества необходимых ресурсов-файлов (листинг 3) [4]:


Листинг 3. Ввод начальных значений для генерации (фрагмент)
Алгоритм ядра будет направлен на получение входных значений по генерации данных, отправке их на GPU, генерации данных, проверке данных на соответствие принципам генерации синтетических данных и передачи их на устройство, где они записываются указанными порциями в файлы.
Обычно при измерении скорости выполнения скриптов на Python используется библиотека time.
import time
start_time = time.time()
main()
print("--- %s seconds ---" % (time.time() – start_time))
Листинг 4. Пример подключения и работы библиотеки time
Фиксируем время перед началом работы алгоритма, затем в конце выполнения программы отнимаем от текущего времени расчетное время, и ответ получаем в секундах.
Эксперименты
Предположим, что необходимо сформировать 10 файлов MS Excel с данными, в каждый из которых запишем по 10 000 строк.
1. Использование CPU для генерации данных.
Первой строкой будет время генерации, второй строкой – время записи в файлы и третьим параметром выведем общее время, которое получится путем сложения двух значений (рис. 1).
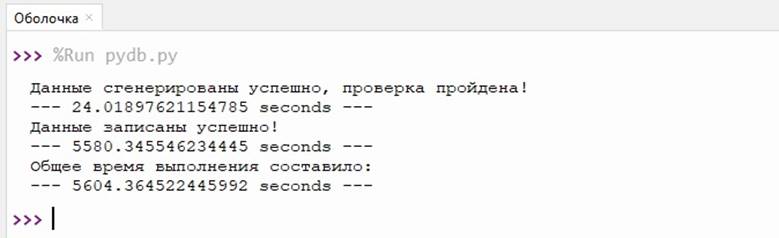
Рисунок 1. Время выполнения алгоритма на CPU
Источник: составлено авторами.
Как видно на рисунке 1, генерация данных прошла успешно, быстро, но на запись данных в файлы ушло много времени.
2. Использование GPU для генерации данных (рис. 2).
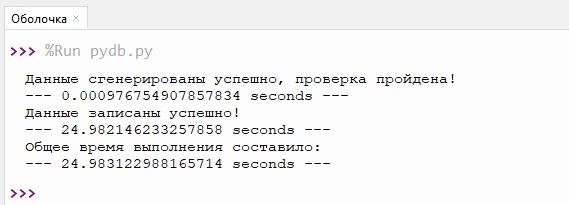
Рисунок 2. Время выполнения алгоритма на GPU
Источник: составлено авторами.
Н рисунке 2 результаты показывают, что фактически были получены те же синтетические данные, аналогичные первому эксперименту, но быстрее: в течение нескольких секунд (чуть меньше 25). Те же данные при генерации на CPU получились у нас лишь спустя полтора часа ожидания.
Заключение. Первоначальное теоретическое исследование, а в дальнейшем и практическая реализация алгоритма показали, что видеокарта может быть использована не только для отрисовки графического ряда в операционной системе, но и для использования ее в параллельных вычислениях при генерации несвязанных данных.
Источники:
2. 7 архитектур нейронных сетей для решения задач NLP. Портал neurohive.io. [Электронный ресурс]. URL: https://neurohive.io/ru/osnovy-a-science/7-arhitektur-nejronnyh-setej-nlp.
3. Применение нейронных сетей в задачах небольшой размерности. Портал auriga. [Электронный ресурс]. URL: https://auriga.com/ru/blog/2019/neural-networks-small-scale-tasks.
4. Как GPU-вычисления буквально спасли меня на работе. Пример на Python. Портал Habr. [Электронный ресурс]. URL: https://habr.com/ru/company/piter/blog/505590.
5. Представляем pydbgen: генератор случайных данных. Портал machinelearningmastery. [Электронный ресурс]. URL: https://www.machinelearningmastery.ru/introducing-pydbgen-a-random-aframe-abase-table-generator-b5c7bdc84be5.
6. Создание синтетического набора данных для ML с использованием Scikit Learn. Портал machinelearningmastery. [Электронный ресурс]. URL: https://www.machinelearningmastery.ru/synthetic-aset-generation-for-ml-using-scikit-learn-and-more-beab8cacc8f8.
7. Кричевский М.Л. Методы машинного обучения при выборе стратегии предприятия // Вопросы инновационной экономики. – 2019. – № 1. – c. 251-266. – doi: 10.18334/vinec.9.1.40093.
Страница обновлена: 18.07.2026 в 07:26:19
Download PDF | Downloads: 52
Models and algorithms for generating synthetic datasets for ML
Zhukov A.V., Zhilina E.V.Journal paper
Informatization in the Digital Economy
Volume 2, Number 3 (July-september 2021)
Abstract:
An algorithm that allows generating synthetic data for subsequent training of neural networks, as well as for filling databases with "fake" Big Data for the purpose of load testing and conducting various experiments has been developed. Python was used as a development tool.
Keywords: algoritm, dataset, GPU, CPU
References:
Krichevskiy M.L. (2019). Metody mashinnogo obucheniya pri vybore strategii predpriyatiya [Methods of machine learning in choosing a strategy of an enterprise]. Russian Journal of Innovation Economics. 9 (1). 251-266. (in Russian). doi: 10.18334/vinec.9.1.40093.