Парсинг электронных ресурсов. Библиотека selenium или fake useragent?
Попов А.Ю.1![]() , Ремез М.В.1, Жилина Е.В.1
, Ремез М.В.1, Жилина Е.В.1![]() , Ожиганова М.И.2
, Ожиганова М.И.2![]()
1 Ростовский государственный экономический университет (РИНХ), Россия, Ростов-на-Дону
2 Севастопольский государственный университет, Россия, Севастополь
Скачать PDF | Загрузок: 116 | Цитирований: 1
Статья в журнале
Информатизация в цифровой экономике (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 3, Номер 4 (Октябрь-декабрь 2022)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=49863092
Цитирований: 1
Аннотация:
В настоящее время большое количество компаний используют парсинг электронных ресурсов. Собирая информацию в сети Интернет, можно получить множество различных преимуществ перед другими компаниями. Однако, сбор данных может быть затруднен использованием электронными ресурсами, средствами защиты от парсинга. Поэтому, правильно выбранная методика обхода блокировок в процессе парсинга, имеет решающее значение успеха в получении данных с электронных ресурсов. В статье рассмотрены различные способы парсинга данных электронных библиотек, показывающие недостатки одних и преимущества других. На основе библиотеки Selenium предлагается универсальное решение получения скрытых данных веб-ресурсов. Возможности Selenium позволяют запускать браузер, отправлять запросы через адресную строку и сохранять код найденной страницы.
Ключевые слова: веб-скрейпинг, обход защиты от парсинга, анти-парсер, python, selenium, fake useragent
JEL-классификация: O3, Q16
Введение. Веб-скрейпинг, или парсинг – это процесс автоматического сбора информации из различных электронных ресурсов. Такой процесс осуществляется с помощью компьютерной программы – парсера, разработанной или настроенной под определенную информацию на конкретном электронном ресурсе. Собранная информация используется для различных целей, например: анализ и сравнение цен, агрегация для создания каталогов, мониторинг новостных потоков и многое другое [6–9] (Platonov, 2020; Panshin, Zhukovskaya, 2020; Sopina, Kan, 2020; Khorovinnikova, 2021).
Разрабатывая парсер, можно столкнуться с тем, что электронные ресурсы используют методы блокировки от автоматического сбора информации. Такие методы могут проверить свойства IP-адреса, избыточность трафика, значения user agent и т.д. Некоторые параметры отличаются у пользователя и у программы автоматического сбора информации, оценив их, защита электронного ресурса производит блокировку.
Существуют и другие методы зашиты от парсинга (антипарсеры), например: ловушки для ботов, использование капчи, динамическое формирование кода сайта и прочее.
В качестве примера использования электронными ресурсами блокировки от парсинга можно рассмотреть электронную библиотеку Elibrary.ru. Данный электронный ресурс позволяет в систематизированном виде получать информацию об авторах, вузах, их публикационной активности и индексах цитирования в разрезе календарных годов, количества цитирований, рейтинга публикационных изданий и т.д. На рисунке 1 приведен исходный код простейшего парсера, разработанного авторами с использованием языка программирования Python и библиотек Requests и BeautifulSoup [3, 4].
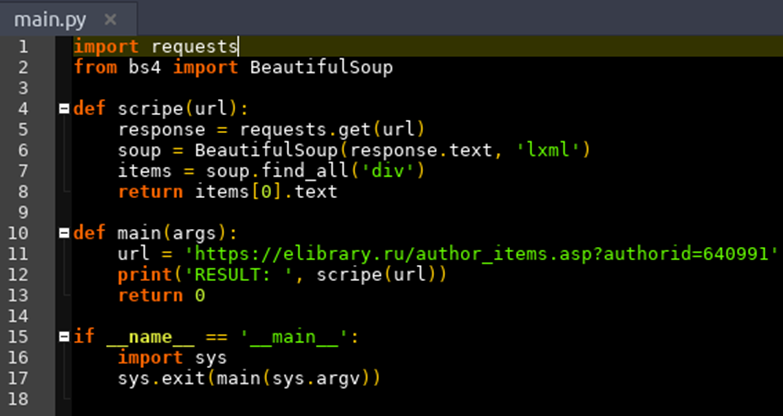
Рисунок 1. Исходный код парсер-программы
Источник: составлено авторами.
Такие электронные ресурсы, как Elibrary.ru, анализируют заголовок HTTP-запроса. Этот заголовок называется пользовательским агентом, он содержит различную информацию: от наименования операционной системы до типа приложения и его версии.
Используя библиотеку Requests, парсер выдает себя значениями в user agent. Блокировка электронного ресурса срабатывает, и IP-адрес машины, на которой выполняется программа, игнорируется. Результат работы парсер-программы изображен на рисунке 2.
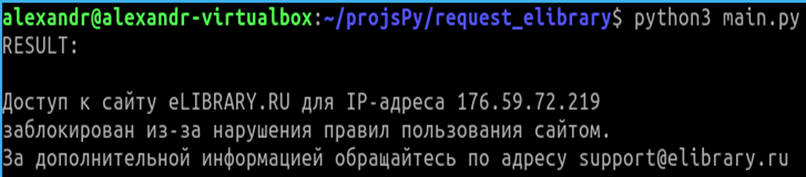
Рисунок 2. Результат работы парсер-программы
Источник: составлено авторами.
Таким образом, базовые программные решения на языке Python не позволяют получить данные электронных ресурсов, требующих определенных действий пользователя.
Основная часть
Библиотека Selenium
Selenium – это открытая библиотека для автоматизированного тестирования веб-приложений. Она управляет браузером и имитирует действия пользователя [2], затрудняя средствам защиты электронных ресурсов определять, кто находится у них на сайте, реальный пользователь или программа, что способствует обходу блокировок [5] (Pervushin, Samsonov, Krasnov, Zhilina, 2020).
Предметная область парсинга. Электронный ресурс Elibrary.ru
Предположим, что в электронной библиотеке Elibrary.ru на страницах авторов необходимо собрать информацию [1] (Akperov, Akperov, Alekseichik et al, 2020): ФИО автора, наименование организации, общее количество публикаций, название первой по списку публикации.
Просмотрев код страницы Elibrary.ru, можно определить теги и атрибуты позиций, подвергаемых парсингу. Если у нужной позиции нет никаких уникальных атрибутов, свойств или параметров, то можно взять ближайшие к ним. На рисунках 3, 4 представлены примеры выбора уникальных атрибутов (параметров) поиска. Так, на рисунке 3 показан поиск атрибута, необходимого для нахождения тега, содержащего информацию о ФИО автора.

а) скрин страницы автора в электронной библиотеке Elibrary.ru
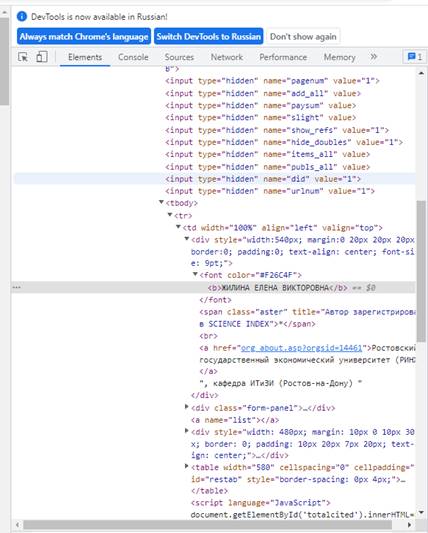
б) скрин кода страницы, формат HTML
Рисунок 3. Выбор уникального атрибута, ФИО
Источник: составлено авторами.
На рисунке 4 показан поиск атрибута, необходимого для нахождения года и количества публикаций в этом году.
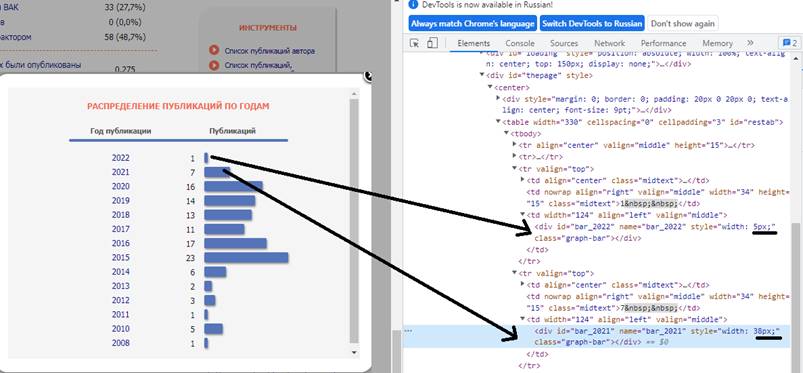
Рисунок 4. Выбор уникального атрибута, года публикационной активности
Источник: составлено авторами.
За количество публикаций отвечает параметр, выраженный в пикселях (px).
Обход блокировки от парсинга с помощью библиотеки Selenium
На рисунке 4 приведен исходный код программы парсера с применением библиотеки Selenium.
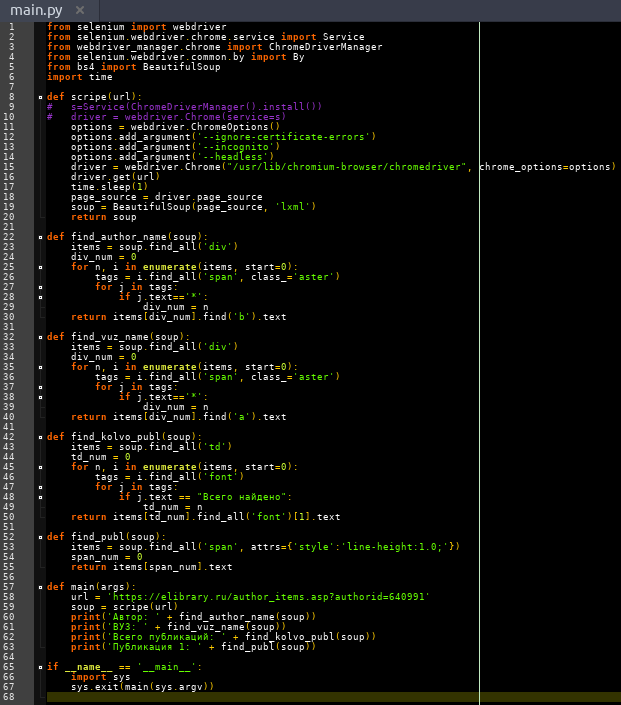
Рисунок 4. Исходный код программы парсера с использованием библиотеки Selenium
Источник: составлено авторами.
Далее на рисунке 5 приведен графический алгоритм в виде блок-схемы парсинга веб-ресурсов, используя драйвер Selenium.
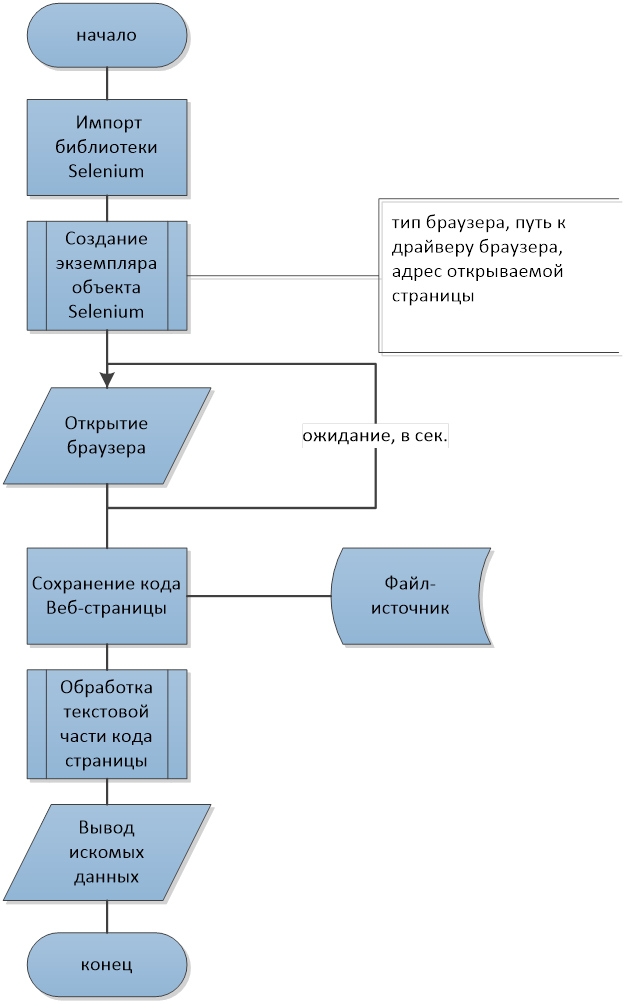
Рисунок 5. Алгоритм работы парсера
Источник: составлено авторами в специализированной программе MS Visio.
Приведенная в качестве примера программа работает по следующему алгоритму:
1) создается объект библиотеки Selenium, которому задаются такие параметры, как тип браузера, путь к драйверу браузера, адрес открываемой страницы и др.;
2) после открытия браузером страницы задается время ожидания, равное одной секунде;
3) сразу по истечении времени ожидания производится сохранение кода страницы для его дальнейшей обработки;
4) сохраненный код страницы обрабатывается функциями, каждая из которых находит необходимую информацию, после чего информация выводится на экран.
Результат работы программы парсера с применением библиотеки Selenium приведен на рисунке 6.
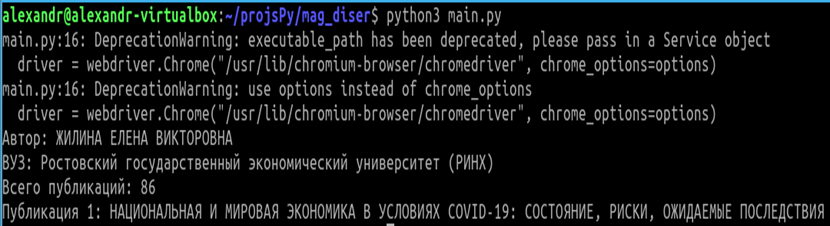
Рисунок 6. Результат работы программы парсера с применением библиотеки Selenium
Источник: составлено авторами.
Обход блокировки от парсинга имитацией реального User-Agent
Еще одним способом обхода блокировок является имитация реального User-Agent.
User-Agent – это идентификатор клиентского приложения, представляющий собой строку характеристик, по которым серверы и сетевые узлы определяют тип приложения, операционную систему, производителя и/или версию пользовательского агента.
В предыдущем случае, когда выполнялась программа, исходный код которой представлен на рисунке 1, User-Agent заголовка запроса явно выдавал, что к электронному ресурсу обращается программа на языке программирования Python, использующая библиотеку Requests. На рисунках 7 и 8 представлен исходный код программы с выводом характеристик заголовка запроса и результат работы этой программы.
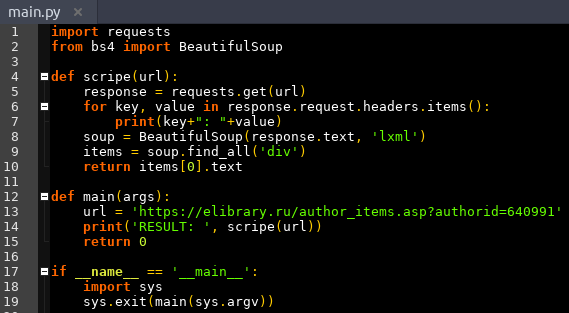
Рисунок 7. Исходный код программы с выводом характеристик заголовка запроса
Источник: составлено авторами.
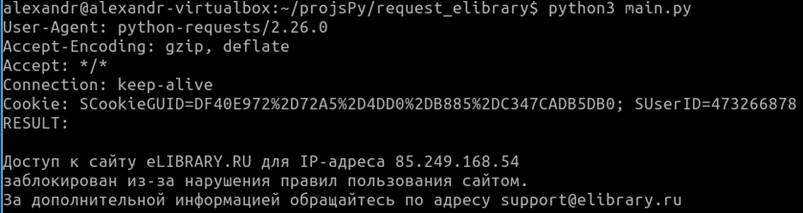
Рисунок 8. Результат работы программы с выводом характеристик заголовка запроса
Источник: составлено авторами.
Для того чтобы избежать блокировки, необходимо сымитировать реальный вид заголовка запроса. В этом может помочь библиотека fake useragent. Данная библиотека производит генерацию фейкового User-Agent. Для проверки работы такого метода обхода блокировок можно взять исходный код программы, представленной на рисунке 4, и немного его видоизменить. На рисунке 9 представлен исходный код программы парсера с использованием библиотеки fake useragent, а на рисунке 10 приведен результат работы программы с выводом характеристик заголовка запроса.
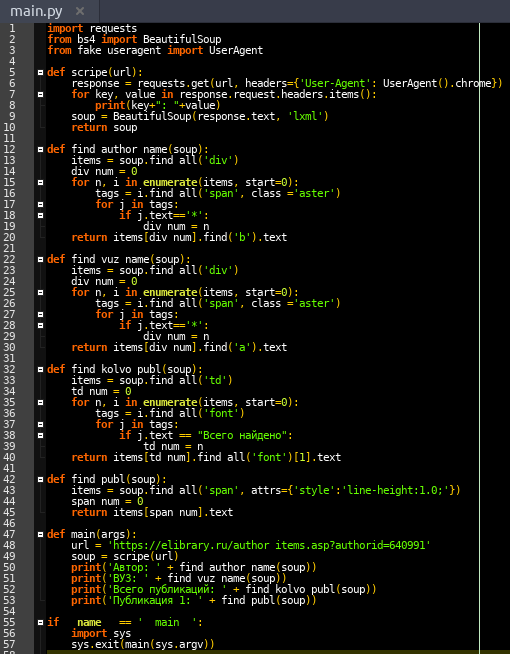
Рисунок 9. Исходный код с использованием библиотеки fake useragent
Источник: составлено авторами.

Рисунок 10. Результат работы программы с использованием библиотеки fake useragent
Источник: составлено авторами.
Таким образом, электронный ресурс Elibrary.ru не выявил ничего подозрительного в запросе программы парсера и позволил скопировать html-код страницы.
Заключение
Основной принцип обхода блокировки от парсинга – программа-алгоритм должна вести себя так, как вел бы себя человек-пользователь, зашедший на сайт.
Программа, использующая библиотеку fake useragent, не является надежным способом обхода блокировок. Возможно, через десятки или сотни таких запросов у защиты электронного ресурса могут возникнуть подозрения. Для снижения риска блокировки необходимо уменьшать скорость работы парсера, добавлять случайные перерывы между запросами и действиями, а также случайные щелчки, прокрутки и движения мыши.
Приведенная в качестве примера программа, использующая библиотеку Selenium, обходит блокировки электронного ресурса Elibrary.ru, так как производит запуск браузера, отправляет запрос через адресную строку, после чего выполняет ожидание и сохранение кода страницы. В то время как программа, использующая библиотеку Requests, отправляет запрос к сайту напрямую, без использования браузера. Тем самым обнаруживается защитой сайта и попадает под блокировку.
Действия Selenium напоминают работоспособность драйвера в браузере, имитируя действия пользователя. Парсинг электронной библиотеки Elibrary.ru позволит получить достоверную информацию по автору, вузам, публикационной активности, цитируемости журналов. Ввод параметров поиска позволит в дальнейшем автоматизировать процесс обработки данных веб-страниц, систематизация которых будет направлена на объективность получения рейтинговых данных соответствующих исследований.
Источники:
2. Web Scraping using Beautiful Soup and Selenium for dynamic page. Medium.com. [Электронный ресурс]. URL: https://medium.com/ymedialabs-innovation/web-scraping-using-beautiful-soup-and-selenium-for-dynamic-page-2f8ad15efe25.
3. Модуль BeautifulSoup4 в Python, разбор HTML. Docs-python.ru. [Электронный ресурс]. URL: https://docs-python.ru/packages/paket-beautifulsoup4-python.
4. Парсинг на Python с Beautiful Soup. Pythonru.com. [Электронный ресурс]. URL: https://pythonru.com/biblioteki/parsing-na-python-s-beautiful-soup.
5. Первушин М.Р., Самсонов К.Ю., Краснов А.В., Жилина Е.В. «Парсинг» внешних данных в проекте «Чат-бот» для РГЭУ РИНХ // Проблемы проектирования, применения и безопасности информационных систем в условиях цифровой экономики: Материалы XX Международной науч.-практич. конф., посвященной 85-летию экономиста-математика, доктора экономических наук, профессора Виктора Алексеевича Кардаша. Ростов-на-Дону, 2020. – c. 242-249.
6. Платонов В.В. Визуализация больших данных в экономических науках в условиях информационного общества // Вопросы инновационной экономики. – 2020. – № 4. – c. 1831-1848. – doi: 10.18334/vinec.10.4.111373.
7. Паньшин И.В., Жуковская И.Ф. Эффект цифровизации при отчуждении труда: новый взгляд на формирование информационного капитала // Экономика труда. – 2020. – № 1. – c. 867-886. – doi: 10.18334/et.7.10.110896.
8. Сопина Н.В., Кан Е.Н. Зависимость уровня конкурентоспособности России от степени развития сектора информационно-коммуникационных технологий // Экономические отношения. – 2020. – № 2. – c. 395-408. – doi: 10.18334/eo.10.2.100859.
9. Хоровинникова Е.Г. Принятие управленческих решений по внедрению информационных технологий в HR-менеджмент // Лидерство и менеджмент. – 2021. – № 3. – c. 329-340. – doi: 10.18334/lim.8.3.112383.
Страница обновлена: 02.08.2026 в 12:41:36
Download PDF | Downloads: 116 | Citations: 1
Parsing of electronic resources. Selenium library or fake useragent?
Popov A.Y., Remez M.V., Zhilina E.V., Ozhiganova M.I.Journal paper
Informatization in the Digital Economy
Volume 3, Number 4 (October-December 2022)
Abstract:
Currently, a large number of companies use the parsing of electronic resources. By collecting information on the Internet, you can get many different advantages over other companies. However, data collection can be hampered by the use of electronic resources, anti-parsing tools. Therefore, the correctly chosen method of bypassing locks in the process of parsing is crucial for success in obtaining data from electronic resources. The article discusses various ways of parsing digital library data, showing the disadvantages of some and the advantages of others. Based on the Selenium library, a universal solution for obtaining hidden data from web resources is proposed. Selenium features allow you to launch a browser, send requests through the address bar and save the code of the page found.
Keywords: web scraping, parsing protection bypass, anti-parser, python, selenium, fake useragent
JEL-classification: O3, Q16
References:
Akperov I.G., Akperov G.I., Alekseichik T.V. et al (2020). Soft models of management in terms of digital transformation Rostov-on-Don: PEI HE SU (IUBIP).
Khorovinnikova E.G. (2021). Prinyatie upravlencheskikh resheniy po vnedreniyu informatsionnyh tekhnologiy v HR-menedzhment [Making managerial decisions on the introduction of information technologies in HR management]. Leadership and management. 8 (3). 329-340. (in Russian). doi: 10.18334/lim.8.3.112383.
Panshin I.V., Zhukovskaya I.F. (2020). Effekt tsifrovizatsii pri otchuzhdenii truda: novyy vzglyad na formirovanie informatsionnogo kapitala [The digitalization effect in the labour alienation: a new look at information capital]. Russian Journal of Labor Economics. 7 (1). 867-886. (in Russian). doi: 10.18334/et.7.10.110896.
Pervushin M.R., Samsonov K.Yu., Krasnov A.V., Zhilina E.V. (2020). «Parsing» vneshnikh dannyh v proekte «Chat-bot» dlya RGEU RINKh ["Parsing" of external data in the Chatbot project for RSEU RINH] Problems of design, application and security of information systems in the digital economy. 242-249. (in Russian).
Platonov V.V. (2020). Vizualizatsiya bolshikh dannyh v ekonomicheskikh naukakh v usloviyakh informatsionnogo obshchestva [Big data visualization in economic sciences in the information society]. Russian Journal of Innovation Economics. 10 (4). 1831-1848. (in Russian). doi: 10.18334/vinec.10.4.111373.
Sopina N.V., Kan E.N. (2020). Zavisimost urovnya konkurentosposobnosti Rossii ot stepeni razvitiya sektora informatsionno-kommunikatsionnyh tekhnologiy [Dependence of the level of Russian competitiveness on the degree of development of the information and communication technologies sector]. Journal of International Economic Affairs. 10 (2). 395-408. (in Russian). doi: 10.18334/eo.10.2.100859.
Web Scraping using Beautiful Soup and Selenium for dynamic pageMedium.com. Retrieved from https://medium.com/ymedialabs-innovation/web-scraping-using-beautiful-soup-and-selenium-for-dynamic-page-2f8ad15efe25