Интеллектуальное моделирование взаимосвязи инновационной активности и уровня человеческого капитала
Савельева О.С.1![]()
1 «Федеральный исследовательский центр Южный научный центр Российской академии наук» (ЮНЦ РАН), Россия, Ростов-на-Дону
Скачать PDF | Загрузок: 50 | Цитирований: 4
Статья в журнале
Социальное предпринимательство и корпоративная социальная ответственность (РИНЦ)
опубликовать статью | оформить подписку
Том 2, Номер 4 (Октябрь-декабрь 2021)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=48906161
Цитирований: 4
Аннотация:
В данном исследовании ставилось целью апробировать инструменты BigData для изучения регионального человеческого капитала и инновационной активности на региональном уровне. Инструменты BigData, по мнению автора, лучше всего соотносятся с теорией человеческого капитала, так как, во-первых, она концентрируется на увеличении производительности благодаря способностям и возможностям человека. Во-вторых, делает акцент на образование, которое имеет чуть ли не решающее значение в сфере разработки и продвижения инноваций.
В работе представлены результаты анализа человеческого капитала в его взаимосвязи с уровнем инновационного развития регионов России. Исследование проводилось в два этапа. Первым шагом выступил кластерный анализ: для выявления похожих по показателям регионов и последующего составления стратегий развития по кластерам; вторым – регрессионный: для определения значимых факторов, показателей, больше всего оказывающих влияние на инновационную активность. База данных формировалась, основываясь на показателях Росстата в разрезе регионов РФ за 2000–2019 гг.
Автор приходит к выводу, что на уровень инновационной активности в разной степени оказывают влияние все компоненты человеческого капитала. Инновации чаще всего связывают с уровнем интеллектуального и образовательного развития, но между тем, исследование показало важность всестороннего, комплексного инвестирования в человеческий капитал.
Ключевые слова: региональный человеческий капитал, инновационная активность, региональное развитие, интеллектуальный анализ данных, Big Data
Финансирование:
Статья подготовлена в рамках реализации ГЗ ЮНЦ РАН, № гр. проекта АААА-А19-119011190184-2.
JEL-классификация: J24, O31, O34
Введение. Основным стратегическим вызовом и одновременно условием повышения уровня социально-экономического развития России и качества жизни ее граждан в настоящее время является переход к инновационной экономике. В свою очередь, этот переход возможен лишь на основе развития региональных инновационных систем, которое напрямую зависит от качества человеческого капитала и процессов, протекающих в сфере науки и инноваций регионального уровня.
Человеческий капитал и возможности применения инструментов Big Data в повышении инновационной активности. Человеческий капитал – это иллюстрация того, что люди вкладывают в себя, другими словами, в свои навыки, что в конечном итоге увеличивает их экономическую производительность. Эта теория основана на идее, что человеческий капитал ведет к творчеству, что в конечном итоге может привести к инновациям. Сторонники этой теории считают, что образованные люди являются продуктивными людьми, основным двигателем прогресса. Теория человеческого капитала основывается на предположении, что формальное образование играет важную роль и даже необходимо для увеличения производственной мощности населения и развития инновационной активности.
Теоретики человеческого капитала утверждают, что продуктивность и эффективность сотрудников повышаются за счет образования и повышения уровня познавательной способности экономически продуктивных человеческих способностей, что является результатом врожденных качеств и инвестиций людей в себя. Логика инвестирования в человеческий капитал построена на трех точках зрения: во-первых, новое поколение должно быть обеспечено знаниями, которые были у предыдущих поколений. Во-вторых, новое поколение следует обучать способам использования имеющихся знаний для разработки и изобретения различных продуктов или услуг. В-третьих, новое поколение следует поощрять к открытию совершенно новых подходов удовлетворения потребностей общества с помощью творчества.
Другой отправной точкой нашего исследования явилось использование инструментов Big Data. Термин Big Data охватывает целый набор инструментов и непрерывно развивающихся технологий сбора и анализа больших объемов самых разных данных. Также данный термин применяют для обозначения самих данных, которые обрабатываются данным методом.
В 2001 г. вышла работа D. Laney, в которой было предложено определение Big Data как «крупномасштабных, высокоскоростных и разнообразных информационных активов» [4] (Laney, 2001). Оно получило название «3V», так как базировалось на трех основных признаках больших данных – так называемых V: Volume, Velocity, Variety, и подразумевало, что размер данных велик, данные будут создаваться быстро и данные могут быть разного типа и собираться из разных источников [1] (Batrouni, Bertaux, Nicolle, 2018).
В более поздних исследованиях выделяют большее количество V, рассматривая еще такие признаки, как veracity – достоверность данных, viability – жизнеспособность, variability – переменчивость и value – ценность данных как в качестве накопленной информации, так и добавленной стоимости для компаний [7].
В контексте Big Data предписывающая аналитика – это относительно недавнее направление, поэтому в настоящее время оно находится на стадии разработки и апробации. Исследователи пытаются синтезировать несколько наук и методологий, таких как машинное обучение (ML), исследование операций (OR), статистический анализ и моделирование.
Аналитику с применением инструментов Big Data можно смело назвать аналитикой нового уровня. Ниже приводится сравнение традиционной и аналитики Big Data (табл. 1).
Таблица 1
Сравнение традиционной аналитики и BigData
|
Традиционная аналитика
|
Big Data
аналитика
|
|
Пошаговый анализ
небольших объемов информации
|
Анализ сразу всего
массива информации
|
|
Подготовка данных для
анализа
|
Не требуется подготовка
|
|
Построение гипотезы и
ее апробация на данных
|
Поиск корреляций сразу
по всему массиву данных
|
|
Трудоемкая
предварительная подготовка данных
|
Анализ данных в
реальном времени, после автоматизации процесса не требует подготовки
|
Анализ больших данных основан на статистических методах и простых принципах корреляции. С каждым годом методов и технологий анализа Big Data становится все больше. Этими вопросами занимается наука о данных – Data Science.
Практики считают, что первоочередной задачей науки о данных является распознавание образов в маccиве данных, анализ и эффективное практическое применение. Когда мы сравниваем методы, используемые в изучаемой области, с традиционной статистикой, получаем, что наука о данных фокусируется на изучении очень больших разнородных цифровых данных в едином контексте, подключая информационные возможности для их анализа. Большим плюсом Data Science является меньшая ограниченность особенностями предметной области, что позволяет сопоставлять самые разные данные [15] (Shikhovtsova, Vinichenko, 2016).
За последнее десятилетие Big Data получили распространение как инструмент управления человеческими ресурсами вместе с искусственным интеллектом. На рисунке 1 показаны задачи по подбору персонала, в которых искусственный интеллект имеет наибольшее значение в 2020 году.
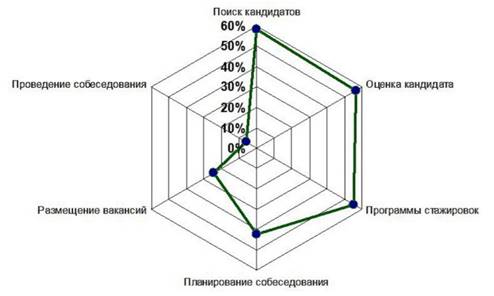
Рисунок 1. Использование искусственного интеллекта при подборе кадров Источник: [12] (Kalinovskaya, 2020).
С 2013 года большие данные имеют независимый фокус в управлении человеческими ресурсами – People Data («данные о людях»; технология для обработки всего спектра данных о человеческих ресурсах, генерируемых как в среде компании, так и за ее пределами, с целью принятия управленческих решений для достижения корпоративных целей) [10] (Dolzhenko, 2019).
Для нашего исследования особый интерес представляет новое перспективное направление, где Big Data применяется для привлечения, выявления, развития и удержания людей, которые считаются талантливыми. На практике слово «талантливый» часто применяют к сотрудникам с высоким потенциалом, «игрокам А», стратегически важным сотрудникам или сотрудникам на ключевых должностях. Они представляют 20% рабочей силы и получают более ценные ресурсы и возможности для карьерного роста от организации. «Игроки А» вносят значительный вклад в общую производительность организации. Их навыки порой уникальны, потому что их трудно заменить.
Современная практика применения Big Data в HR интересна тем, что позволяет выявить таланты у всех людей, а не только «отличников». Преимущества анализа талантов с точки зрения эффективности очевидны. Например, если организация может определить причинно-следственную связь между расходами на обучение и рентабельностью, тогда это дает возможность разработать поддающуюся количественной оценке стратегию обучения.
Несмотря на потенциальные преимущества, аналитика талантов как отдельная область бизнеса развивалась достаточно медленно. По результатам исследования глобальных тенденций развития человеческого капитала в 2014 г. проведенный опрос показал, что компании понимают важность данного направления, но при этом выявил значительные пробелы в их текущей готовности практического использования. В опросе, проведенном Falletta в 2014 г., только 15% респондентов заявили, что аналитика талантов играет ключевую роль в их организации [2] (Falletta, 2014). Аналогичные результаты были получены Lawler и соавторами в 2015 г., хотя в других отчетах подчеркивалось, что в некоторых отраслях очень распространено использование аналитики талантов благодаря доступности данных [5] (Lawler, Boudreau, 2015).
Однако все быстро изменилось. Например, отчет IBM за 2016 год обнаружил, что использование прогнозной аналитики для поиска талантливых сотрудников увеличилось на 40% за предыдущие два года [3].
В высокоинтеллектуальных профессиях выявление талантов действительно очень сложный процесс. Например, исследование в аэрокосмической сфере показало [6] (N’Cho, 2017), что выдающийся талант должен иметь не менее десяти лет опыта, чтобы его признали руководители высшего звена. Выявить талант в начале процесса действительно сложно. С другой стороны, необходимы молодые специалисты, способные выполнять задачи в области новых технологий и совершенствовать свой потенциал. Аналитика талантов может помочь ответить на этот вопрос, внося свой вклад в определение потенциала людей на основе врожденных характеристик, особенностей личности, а также образования и культурного происхождения.
При этом важно не только выявить таланты, но и удержать их. Аналитика талантов поможет определить правильное время и развивать таланты, удовлетворяя потребности и организации, и сотрудника. Например, перераспределить сотрудников на новые должности или перевести в другие отделы.
Инструменты BigData могут применяться на разных шагах работы с персоналом, включая выявление талантов, отбор, привлечение и сохранение (табл. 2).
Таблица 2
Возможности анализа талантов в организации
|
Шаг
процесса управления талантами
|
Вклад
аналитики талантов
|
|
Анализ
личности
|
Сбор
и анализ информации о личности, образовании и культурном происхождении
|
|
Отбор
|
Отбор
кандидатов в зависимости от текущих целей организации
|
|
Привлечение
|
Сбор
и анализ информации для привлечения молодого поколения
|
|
Развитие
и удержание
|
Определение
правильного времени и правильного развития таланта в рамках организации
|
|
Перераспределение
|
Перевод
на другие должности или в другие отделы
|
На данном этапе исследования мы ставили целью апробировать инструменты Big Data для изучения регионального человеческого капитала и инновационной активности для начала на региональном уровне. Инструменты Big Data, по нашему мнению, лучше всего соотносятся с теорией человеческого капитала, от которой мы будем отталкиваться в дальнейшем при рассмотрении поставленной проблемы. Теория человеческого капитала кажется нам наиболее подходящей в рамках данного исследования, так как, во-первых, концентрируется на увеличении производительности благодаря способностям и возможностям человека. Во-вторых, делает акцент на образовании, которое имеет чуть ли не решающее значение в сфере разработки и продвижения инноваций.
Для анализа данных представляется целесообразным использовать следующие инструменты Big Data:
1. Кластерный анализ: для выявления похожих по показателям регионов и последующего составления стратегий развития по кластерам.
2. Регрессионный анализ: для определения значимых факторов, показателей, больше всего оказывающих влияние на инновационную активность.
Интеллектуальный анализ Big Data может быть двух видов: с учителем и без. Другими словами, распознавание образов для обнаружения закономерностей в данных может быть контролируемым и неконтролируемым. При распознавании образов с учителем происходит обучение на основе какого-то набора данных, чтобы помочь алгоритмам обнаруживать закономерности. Без учителя – означает, что обучение на основе данных не проводится; закономерности обнаруживаются другими способами, такими как статистический анализ.
Для распознавания образов с учителем необходимо иметь определенные предварительные знания. Это связано с тем, что данные, используемые для обучения программного обеспечения, должны быть предварительно отобраны.
При неконтролируемом распознавании образов в этом нет необходимости. Группа данных просто обрабатывается алгоритмом, чтобы увидеть, что «интересно». При этом закономерности могут быть и не найдены.
Кластерный анализ – это форма неконтролируемого распознавания образов, «обучения без учителя», основывается на объединении наиболее похожих наблюдений в группы (кластеры) (рис. 2).
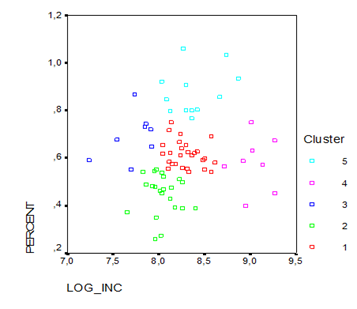
Рисунок 2. Пример кластерного анализа
Источник: составлено автором по результатам работы в программе Statistica.
Следующим шагом аналитика является изучение данных, составляющих каждый кластер. Например, исследование зеленого кластера может выявить концентрацию регионов с наиболее высоким уровнем образования. Аналитик должен понять:
1) что интересного в кластерах?
2) какие наблюдения в данных могли вызывать такую кластеризацию?
Доступны несколько типов алгоритмов кластеризации, такие как алгоритмы на основе связности, центроида, распределения и плотности.
Регрессионный анализ используется для оценки силы и направления взаимосвязи между переменными, которые линейно связаны друг с другом (рис. 3). Две переменные X и Y называются линейно связанными, если связь между ними можно записать в виде:
Y = mX + b, (1)
где m – наклон или изменение Y из-за данного изменения X;
b – точка пересечения или значение Y, когда X = 0.
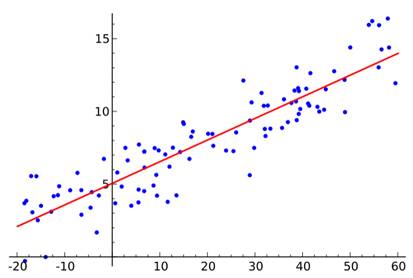
Рисунок 3. Пример линейной регрессии
Источник: составлено автором по результатам работы в программе Statistica.
Регрессионный анализ может помочь нам построить модель линейной зависимости инновационной активности и рассматриваемых наблюдений человеческого капитала.
Анализ регионального человеческого капитала во взаимосвязи с инновационной активностью. В работе представлены результаты анализа человеческого капитала в его взаимосвязи с уровнем инновационной активности регионов России. База данных формировалась, основываясь на показателях Росстата в разрезе регионов РФ за 2000–2019 гг.
Нет единой точки зрения на сущность и структуру человеческого капитала, тем более регионального. В нашем исследовании мы рассматривали человеческий капитал, состоящий из следующих элементов:
· интеллектуальный капитал;
· демографический капитал;
· трудовой капитал;
· образовательный капитал;
· социокультурный капитал [11, 14] (Zabelina, Kozlova, Romanyuk, 2013; Myzin, Gurban, 2011).
Для каждого составного элемента были выбраны следующие показатели по всем субъектам РФ (табл. 3).
Таблица 3
Показатели регионального человеческого капитала
|
Показатель
|
Сокращенное название
|
|
Интеллектуальный
капитал
| |
|
Численность персонала,
занятого научными исследованиями и разработками
|
И1
|
|
Численность кандидатов
наук
|
И2
|
|
Численность докторов
наук
|
И3
|
|
Удельный вес
организаций, осуществляющих технологические инновации в отчетном году, в
общем числе обследованных организаций
|
И4
|
|
Используемые передовые
производственные технологии по субъектам Российской Федерации
|
И5
|
|
Демографический капитал
| |
|
Общий прирост населения
|
Д1
|
|
Ожидаемая
продолжительность жизни при рождении
|
Д2
|
|
Заболеваемость на 1000
человек населения
|
Д3
|
|
Смертность населения в
трудоспособном возрасте на 100 000 чел.
|
Д4
|
|
Трудовой капитал
| |
|
Численность рабочей
силы в возрасте 15 лет и старше
|
Т1
|
|
Численность безработных
в возрасте 15–72 лет
|
Т2
|
|
Безработные с высшим
образованием, %
|
Т3
|
|
Безработные со средним профессиональным
образованием
|
Т4
|
|
Образовательный капитал
| |
|
Число образовательных
организаций высшего образования и научных организаций
|
О1
|
|
Численность студентов
на 10 000 человек
|
О2
|
|
Численность
профессорско-преподавательского состава в вузах
|
О3
|
|
Численность студентов,
получающих средне-профессиональное образование на 10 000 человек
населения
|
О4
|
|
Социокультурный капитал
| |
|
Численность зрителей
театров на 1000 человек населения
|
С1
|
|
Число посещений музеев
на 1000 человек
|
С2
|
|
Численность населения с
доходами ниже прожиточного минимума, %
|
С3
|
|
| |
Регионы России не являются однородными по рассматриваемым показателям, порой очень сильно отличаются друг от друга [13] (Mikhalkina, Kosolapova, Senkiv, 2015). Учитывая данный факт, исследование проводилось в два этапа. Первым шагом выступил кластерный анализ: для выявления похожих по показателям регионов и последующего составления стратегий развития по кластерам; вторым – регрессионный: для определения значимых факторов, показателей, больше всего оказывающих влияние на инновационную активность. Для ухода от разной размерности данных использовалась процедура стандартизации. Наиболее удачным вариантом явилось разбиение всех наблюдений (показателей человеческого капитала по регионам) на 4 кластера (табл. 4).
Для кластеризации оказались подходящими следующие показатели: численность персонала, занятого научными исследованиями и разработками; численность кандидатов наук; численность докторов наук; ожидаемая продолжительность жизни при рождении; смертность населения в трудоспособном возрасте; численность рабочей силы; число образовательных организаций высшего образования и научных организаций; численность профессорско-преподавательского состава в вузах; численность зрителей театров на 1000 человек населения.
Таблица 4
Кластеры регионов по уровню человеческого капитала
|
I. Среднестатистический
|
Белгородская
обл., Воронежская обл., Калужская обл., Курская обл., Липецкая обл.,
Рязанская обл., Тамбовская обл., Тульская обл., Ярославская обл.,
Ленинградская обл., Р. Адыгея, Р. Калмыкия, Р. Крым, Астраханская обл.,
Волгоградская обл., Ростовская обл., г. Севастополь, Р. Северная Осетия –
Алания, Р. Башкортостан, Р. Мордовия, Р. Татарстан, Чувашская Р.,
Нижегородская обл., Пензенская обл., Самарская обл., Саратовская обл.,
Свердловская обл., Тюменская обл., Тюменская обл., Челябинская обл.,
Новосибирская обл., Омская обл., Томская обл., Хабаровский кр.
|
|
II.
Концентрация человеческого капитала. «Показательные» регионы
|
г.
Москва, г. Санкт-Петербург
|
|
III.
Низкий демографический и трудовой капитал
|
Брянская
обл., Владимирская обл., Ивановская обл., Костромская обл., Орловская обл.,
Смоленская обл., Тверская обл., Р. Карелия, Р. Коми, Архангельская обл.,
Вологодская обл., Калинингpадская обл., Мурманская обл., Новгородская обл.,
Псковская обл., Р. Марий Эл, Удмуртская Республика, Пермский кр., Кировская
обл., Оренбургская обл., Ульяновская обл., Курганская обл., Ханты-Мансийский
а.о. – Югра, Р. Алтай, Р. Тыва, Р. Хакасия, Алтайский кр., Красноярский кр.,
Иркутская обл., Кемеровская обл., Р. Бурятия, Р. Саха (Якутия), Забайкальский
край, Камчатский кр., Приморский кр., Амурская обл., Магаданская обл.,
Сахалинская обл.
|
|
IV.
Высокий демографический и трудовой, низкий социокультурный капитал
|
Московская
обл., Краснодарский кр., Р. Дагестан, Р. Ингушетия, Кабардино-Балкарская Р.,
Карачаево-Черкесская Р., Чеченская Р., Ставропольский кр.
|
Отличительные особенности были выделены на основе графика средних и составленной на его основе таблицы уровня значимых показателей по кластерам (рис. 4; табл. 5).
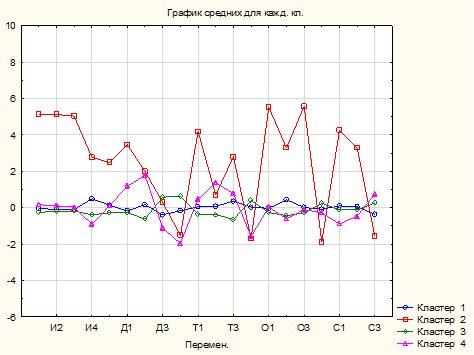
Рисунок 4. График средних кластерного анализа регионального человеческого капитала
Источник: составлено автором по результатам работы в программе Statistica.
Таблица 5
Уровень значимых показателей по кластерам
|
Показатель
|
Кластер I
|
Кластер II
|
Кластер III
|
Кластер IV
|
|
Численность
персонала, занятого научными исследованиями и разработками
|
средний
|
очень высокий
|
средний
|
средний
|
|
Численность
кандидатов наук
|
средний
|
очень высокий
|
средний
|
средний
|
|
Численность
докторов наук
|
средний
|
очень высокий
|
средний
|
средний
|
|
Ожидаемая
продолжительность жизни при рождении
|
средний
|
высокий
|
ниже среднего
|
высокий
|
|
Смертность
населения в трудоспособном возрасте на 100 000 чел
|
средний
|
низкий
|
выше среднего
|
низкий
|
|
Численность
рабочей силы в возрасте 15 лет и старше
|
средний
|
очень высокий
|
ниже среднего
|
выше среднего
|
|
Число
образовательных организаций высшего образования и научных организаций
|
средний
|
очень высокий
|
средний
|
средний
|
|
Численность
профессорско-преподавательского состава в вузах
|
средний
|
очень высокий
|
средний
|
средний
|
|
Численность
зрителей театров на 1000 человек населения
|
средний
|
высокий
|
средний
|
ниже среднего
|
Стоит начать с кластера II, в который вошли Москва и Санкт-Петербург. Он характеризуется высокими значениями человеческого капитала по всем показателям. В данных регионах самые высокие показатели интеллектуального и образовательного капитала (численность персонала, занятого научными исследованиями и разработками, количество кандидатов и докторов наук, профессорско-преподавательского состава, а также организаций высшего образования и научных организаций). Логичным выглядит, что эти два города обладают самыми мощными ресурсами по всем направлениям и являются лидерами в концентрации человеческого капитала.
Кластер I можно назвать «среднестатистическим» по стране. Он имеет средние значения по всем показателям. В него вошли 34 региона. Основная цель регионов в данном кластере – это ориентация на кластер II, повышение всех показателей.
В кластер III вошли 38 регионов, которые отстают по демографическим и трудовым показателям. В этих регионах высокая смертность при ожидаемой продолжительности населения ниже среднего, что логично перетекает в низкий уровень численности рабочей силы.
Кластер IV, наоборот, характеризуется высоким демографическим потенциалом, а следовательно, и более большой численностью рабочей силы. При этом в нем отмечается низкий уровень культурного потенциала. В него вошли субъекты СКФО, а также, что вызывает интерес, Московская область. Но если посмотреть на показатель расстояния до центра, то видно, что Московская область достаточно сильно отличается от всех остальных наблюдений в данном кластере. Более детальный анализ показал, что попасть во II «прогрессивный» кластер Московской области помешали более низкие демографические показатели, чем в Москве и Санкт-Петербурге: более низкая ожидаемая продолжительность жизни, но более высокая смертность.
Вторым шагом выступило построение регрессионной модели, которая показала, что наиболее сильное влияние на показатель инновационной активности оказывают качество трудовой силы (хорошие демографические показатели, высокий уровень образования) и собственно наличие организаций, занимающихся инновационными разработками. Причем наибольший вес имеют удельный вес организаций, осуществляющих технологические инновации (0,93), и численность профессорско-преподавательского состава в вузах (0,96). Что вполне выглядит логичным.
Для нашего уравнения значимы 9 независимых переменных. Модель принимает следующий вид:
Инновационная активность = 0,93*И4 + 0,24*Д1 + 0,38*Д2 + 0,25*Д4–0,17*Т3 + 0,17*Т4 + 0,96*О3–0,18*С1–0,15*С2.
Коэффициент детерминации R2 = 0,92, т.е. на 92% модель показывает зависимость и изменения инновационной активности организаций в сочетании с рассматриваемыми параметрами.
Заключение
Уравнение регрессии показало, что на уровень инновационной активности в разной степени оказывают влияние все компоненты человеческого капитала. Инновации чаще всего связывают с уровнем интеллектуального и образовательного развития, но между тем исследование показало важность всестороннего, комплексного инвестирования в человеческий капитал.
При этом стоит заметить, что в базу данных не вошел ряд очень значимых показателей, как, например, качество образования и научной деятельности, осуществляемой организациями. Их оценка является очень сложной и спорной. Например, не перестает подвергаться критике чрезмерно наукометрический подход к научной деятельности. Ловушки метрик очень хорошо проиллюстрированы в исследованиях Вольчика В.В. и Маслюковой Е.В. [8, 9] (Volchik, Maslyukova, 2018; Volchik, Maslyukova, 2019). Авторы рассматривают концепт неявного знания, которое никак не может учитываться формальными показателями. В работе отмечается дуализм качества и количества в оценке производительности в сфере науки и образования. С одной стороны, качественные характеристики очень важны, но не подходят для нужд внешнего контроля. Однако если государство будет акцентировать свое внимание только на количественных показателях, мы можем получить ложный успех текущего научного развития, но невыполнение стратегических задач страны в среднесрочной и долгосрочной перспективе. Также авторы отмечают очень важный момент, что гонка показателей может быть даже губительна в сфере, которая в первую очередь базируется на творчестве. Это довольно серьезная, но и интересная проблема, особенно при исследовании инновационной активности, которая требует дальнейшего, более глубокого изучения.
Источники:
2. Falletta S. In search of HR intelligence: Evidence-based HR Analytics practices in high performing companies // People & Strategy. – 2014. – p. 28-37.
3. Redefining Talent: Insights from the Global C-Suite Study–The CHRO Perspective. - Armonk: IBM Institute for Business Value, 2016. – 20 p.
4. Laney D. 3D Data Management: Controlling Data Volume, Velocity, and Variety. META group Inc. [Электронный ресурс]. URL: https://studylib.net/doc/8647594/3d-data-management--controlling-data-volume--velocity--an...?.
5. Lawler E, Boudreau J. Global Trends in Human Resource Management: A Twenty Year Analysis. - Stanford: Stanford University Press, 2015.
6. N’Cho J. Contribution of talent analytics in change management within project management organizations The case of the French aerospace sector // Procedia Computer Science. – 2017. – p. 625-629. – doi: 10.1016/J.PROCS.2017.11.082.
7. The Missing V’s in Big Data: Viability and Value. Wired. [Электронный ресурс]. URL: https://www.wired.com/insights/2013/05/the-missing-vs-in-big-data-viability-and-value/ (дата обращения: 15.10.2020).
8. Вольчик В.В., Маслюкова Е.В. Ловушка метрик или почему недооценивается неявное знание в процессе регулирования сферы образования и науки // Журнал институциональных исследований. – 2018. – № 3. – c. 158-179. – doi: 10.17835/2076-6297.2018.10.3.158-179.
9. Вольчик В.В., Маслюкова Е.В. Реформы, неявное знание и институциональные ловушки в сфере образования и науки // Пространство экономики. – 2019. – № 2. – c. 146-162. – doi: 10.23683/2073-6606-2019-17-2-146-162.
10. Долженко Р.А. People data («Данные о людях») как новое направление работы с человеческими ресурсами // Вестник Омского университета. Серия: Экономика. – 2019. – № 1. – c. 63-72. – doi: 10.25513/1812-3988.2019.17(1).63-72.
11. Забелина О.В., Козлова Т.М., Романюк А.В. Человеческий капитал региона: проблемы сущности, структуры и оценки // Экономика, статистика и информатика. Вестник УМО. – 2013. – № 4. – c. 59-64.
12. Калиновская И.Н. Социальные данные как инструмент специалиста по управлению человеческими ресурсами организации // Вестник Витебского государственного технологического университета. – 2020. – № 1(38). – c. 173-187. – doi: 10.24411/2079-7958-2020-13818.
13. Михалкина Е.В., Косолапова Н.А., Сенькив О.Я. Модель оценки влияния факторов социально-экономического развития регионов России на формирование человеческого потенциала // Теrrа Economicus. – 2015. – № 2. – c. 57-72.
14. Мызин А.Л., Гурбан И.А. Проблемы оценки человеческого капитала в контексте исследования национального богатства регионов России // Экономика региона. – 2011. – № 1(25). – c. 104-109.
15. Шиховцова А.И, Виниченко М.В. Применение Вata Science в геймификации бизнес и HR процессов организации // Новое поколение. – 2016. – № 9. – c. 182-189.
16. Understanding Big Data: The Seven V’s. Dataconomy.com. [Электронный ресурс]. URL: http://dataconomy.com/2014/05/seven-vs-big-data (дата обращения: 15.10.2020).
Страница обновлена: 08.07.2026 в 23:16:57
Download PDF | Downloads: 50 | Citations: 4
Intelligent modeling of the relationship between innovation activity and human capital
Saveleva O.S.Journal paper
Social Entrepreneurship and Corporate Social Responsibility
Volume 2, Number 4 (October-December 2021)
Abstract:
The research purpose was to test BigData tools for studying regional human capital and innovation activity at the regional level. BigData tools, according to the author, are best correlated with the theory of human capital. Firstly, the theory of human capital focuses on increasing productivity due to human abilities and capabilities. Secondly, it focuses on education, which is almost crucial in the development and promotion of innovations.
The article presents the results of the analysis of human capital in its relationship with the level of innovative development of Russian regions. The study was conducted in two stages.
In order to identify regions that are similar in terms of indicators and then draw up development strategies for clusters, a cluster analysis was carried out at the first stage. At the second stage, regression analysis was carried out to determine the significant factors and indicators that most influence innovation activity.
The database was formed based on the indicators of Rosstat in the context of the regions of the Russian Federation for 2000-2019.
The author comes to the conclusion that the level of innovation activity is influenced to varying degrees by all components of human capital. Innovation is most often associated with the level of intellectual and educational development, but meanwhile, the study showed the importance of comprehensive, integrated investment in human capital.
Keywords: regional human capital, innovation activity, regional development, data mining, Big Data
Funding:
JEL-classification: J24, O31, O34
References:
Redefining Talent: Insights from the Global C-Suite Study–The CHRO Perspective (2016). Armonk: IBM Institute for Business Value.
Batrouni M., Bertaux A., Nicolle S. (2018). Scenario analysis, from BigData to black swan Computer Science Review. 131-139. doi: 10.1016/j.cosrev.2018.02.001.
Dolzhenko R.A. (2019). People data («Dannye o lyudyakh») kak novoe napravlenie raboty s chelovecheskimi resursami [People data as a new trend in human resource management]. Bulletin of Omsk University Series "Economics". 17 (1). 63-72. (in Russian). doi: 10.25513/1812-3988.2019.17(1).63-72.
Falletta S. (2014). In search of HR intelligence: Evidence-based HR Analytics practices in high performing companies People & Strategy. 28-37.
Kalinovskaya I.N. (2020). Sotsialnye dannye kak instrument spetsialista po upravleniyu chelovecheskimi resursami organizatsii [Social data as a tool for an organization's human resources management specialist]. Vestnik Vitebskogo gosudarstvennogo tekhnologicheskogo universiteta. (1(38)). 173-187. (in Russian). doi: 10.24411/2079-7958-2020-13818.
Laney D. 3D Data Management: Controlling Data Volume, Velocity, and VarietyMETA group Inc. Retrieved from https://studylib.net/doc/8647594/3d-data-management--controlling-data-volume--velocity--an...?
Lawler E, Boudreau J. (2015). Global Trends in Human Resource Management: A Twenty Year Analysis Stanford: Stanford University Press.
Mikhalkina E.V., Kosolapova N.A., Senkiv O.Ya. (2015). Model otsenki vliyaniya faktorov sotsialno-ekonomicheskogo razvitiya regionov Rossii na formirovanie chelovecheskogo potentsiala [Assessment model for the russian regionsʼ socio-economic development factors impact on the human potential building]. Terra economicus. 13 (2). 57-72. (in Russian).
Myzin A.L., Gurban I.A. (2011). Problemy otsenki chelovecheskogo kapitala v kontekste issledovaniya natsionalnogo bogatstva regionov Rossii [Problems of human capital assessment in the context of the study of the national wealth of Russian regions]. Economy of the region. (1(25)). 104-109. (in Russian).
N’Cho J. (2017). Contribution of talent analytics in change management within project management organizations The case of the French aerospace sector Procedia Computer Science. 121 625-629. doi: 10.1016/J.PROCS.2017.11.082.
Shikhovtsova A.I, Vinichenko M.V. (2016). Primenenie Vata Science v geymifikatsii biznes i HR protsessov organizatsii [Application of Data Science in gamification of business and HR processes of the organization]. Novoe pokolenie. (9). 182-189. (in Russian).
The Missing V’s in Big Data: Viability and ValueWired. Retrieved October 15, 2020, from https://www.wired.com/insights/2013/05/the-missing-vs-in-big-data-viability-and-value/
Understanding Big Data: The Seven V’sDataconomy.com. (in Russian). Retrieved October 15, 2020, from http://dataconomy.com/2014/05/seven-vs-big-data
Volchik V.V., Maslyukova E.V. (2018). Lovushka metrik ili pochemu nedootsenivaetsya neyavnoe znanie v protsesse regulirovaniya sfery obrazovaniya i nauki [The metrics trap, or why is implicit knowledge underestimated when regulation of science and education is handled]. Journal of Institutional Studies. 10 (3). 158-179. (in Russian). doi: 10.17835/2076-6297.2018.10.3.158-179.
Volchik V.V., Maslyukova E.V. (2019). Reformy, neyavnoe znanie i institutsionalnye lovushki v sfere obrazovaniya i nauki [Reforms, tacit knowledge, and institutional traps in education and science]. Prostranstvo ekonomiki. (2). 146-162. (in Russian). doi: 10.23683/2073-6606-2019-17-2-146-162.
Zabelina O.V., Kozlova T.M., Romanyuk A.V. (2013). Chelovecheskiy kapital regiona: problemy sushchnosti, struktury i otsenki [Regional human capital: problems of essence, structure and assessment]. Statistics and Economics. (4). 59-64. (in Russian).