Оценка влияния агломерационного эффекта на экономическое развитие городских округов Самарской области
Павлов Ю.В.1![]() , Хмелева Г.А.1
, Хмелева Г.А.1![]()
1 Самарский государственный экономический университет, Россия, Самара
Скачать PDF | Загрузок: 84 | Цитирований: 4
Статья в журнале
Экономика, предпринимательство и право (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 12, Номер 10 (Октябрь 2022)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=49851265
Цитирований: 4
Аннотация:
Концентрация ресурсов, предприятий, населения в городах создаёт условия для возникновения агломерационного эффекта. В статье исследуется вопрос о влиянии факторов агломерационного эффекта на валовый муниципальный продукт в городских округах Самарской области. Ввиду наличия перекрёстного влияния факторов друг на друга обычная регрессионная однофакторная или многофакторная модель может не вполне отражать социально-экономические зависимости. Для построения наиболее точной модели данных зависимостей применяется частный метод наименьших квадратов с конструированием модели, отражающей причинно-следственные связи между блоками условных переменных. Для построения модели применяется зарубежная компьютерная программа SmartPLS3. Новизна исследования заключается в выявлении причинно-следственных связей формирования агломерационных эффектов. Как результат исследования, выявлены приоритеты развития отдельных социально-экономических блоков для ускорения развития городских округов Самарской области.
Ключевые слова: агломерационный эффект, факторы агломерационного эффекта, эффект локализации, эффект урбанизации, дезагломерация, агломерация
JEL-классификация: R11, R12, R13
Введение
Вопрос об оценке силы влияния факторов агломерационного эффекта на результативность региональной экономики находится в рамках основного вопроса региональной экономики о выборе концентрированного или выравнивающего развития. Ввиду ограниченности ресурсов возникает необходимость их концентрации для получения агломерационного эффекта. Однако чрезмерная концентрация может вести к снижению темпов развития периферийных территорий либо вовсе к получению дезагломерационного эффекта. Такой эффект проявляется в избыточной концентрации ресурсов на отдельной территории, что оказывает влияние на экономику в виде ухудшения в транспортной системе, перенаселенности и роста цен на землю, ухудшения экологии и прочее.
Количественная оценка агломерационного эффекта позволит представить рекомендации по концентрации или деконцентрации социально-экономической деятельности в регионе. Агломерационный эффект вызывается разнообразными группами факторов, что накладывает определенные сложности на его измерение. Методология оценки разнообразна, единой методики не существует, примеры решений представлены в следующих работах:
1. Оценка эффекта масштаба [18] (Kukoverov, 2018).
2. Оценка эффекта локализации [17] (Kovaleva, 2011).
3. Оценка эффекта урбанизации [12] (Vorobev, Davidson, Kislyak, Kuznetsov, 2014).
4. Оценка влияния системы расселения [20] (Pavlov, 2020).
5. Оценка институционального влияния [1] (Ahrend, 2014).
В качестве результирующей переменной, которая характеризует уровень агломерационного эффекта, обычно выступает производительность труда [1; 13] (Ahrend, 2014; Gonchar, Ratnikova, 2014). В качестве факторных переменных могут выступать простые и производные показатели. В качестве простых показателей могут применять (в зависимости от исследуемого фактора агломерационного эффекта) численность населения, плотность населения, уровень ВВП и т.д. [16; 4; 2] (Zubarevich, 2013; Ciccone, Hall, 1996; Brulhart, Sbergami, 2009). В качестве сложных показателей применяют оценку специализации, индекс Херфиндаля-Хиршмана, авторские коэффициенты диверсификации структуры экономики, отраслевые формулы оценки эффекта масштаба, индекс Джини и т.д. [22; 19; 23; 12; 18; 14] (Rastvortseva, 2018; Pavlinova, 2019; Tolmachev, 2011; Vorobev, Davidson, Kislyak, Kuznetsov, 2014; Kukoverov, 2018; Drapkin, Mariev, Semenova, Kolyagina, 2016).
Для выявления зависимостей между факторными и результирующими переменными могут применяться методы однофакторной и многофакторной регрессии, построения системы управления [24] (Khmeleva, Nedelka, 2021). В статье представлен альтернативный взгляд на количественную оценку агломерационного эффекта.
Проблема исследования состоит в том, что для управления развитием агломераций необходимо иметь методику количественной оценки не только агломерационного эффекта, но и взаимодействия влияющих на него факторов. Большинство методик оценивают только силу агломерационного эффекта, при этом не все влияющие на него группы факторов учтены.
Цель работы – построение количественной модели оценки агломерационного эффекта и взаимовлияния групп его факторов, что позволит предоставить управленческие рекомендации.
Новизной исследования является построение количественной модели агломерационного эффекта с учетом взаимовлияния групп его факторов при помощи метода PLS-SEM.
Его особенности:
1. Учет полного числа факторов агломерационного эффекта (хотя бы в виде обозначения того, что такой фактор присутствует в модели, но без подробной детализации).
2. Применение особого метода выявления взаимосвязи между зависимой и факторными переменным: метод PLS-SEM. Это частный метод наименьших квадратов, он позволяет создавать модели, отражающие причинно-следственные связи между не просто двумя или несколькими переменными, а между любым количеством условных блоков переменных, представляющих из себя неявные скрытые переменные (на которые уже влияют явные переменные). Модели PLS-SEM являются путевыми моделями, в которых одни переменные могут быть следствием других, но при этом оставаться причинами для последующих переменных. Модели PLS-SEM являются альтернативой моделированию структурных уравнений на основе ковариаций (традиционному SEM). Данный метод уместен в случае работы с т.н. мягкими системами, в которых нет четко определенного набора показателей (тем самым присутствует некий субъективизм в выборе набора показателей при построении системы), либо исследуемое влияние некоего процесса невозможно описать напрямую, и из-за этого нужно формировать группу неявной переменной, описываемой неким набором показателей. Метод структурного моделирования восходит к множественной регрессии, но обладает рядом дополнительных возможностей: позволяет работать с коррелирующими независимыми переменными, формировать множество неявных переменных и т.п.
Методология
В качестве результирующей переменной в исследовании применяются производные от валового муниципального продукта (далее – ВМП) и заработной платы работников организаций. Полигоном исследования выступили городские округа Самарской области. Для оценки валового муниципального продукта разработано множество методик [21] (Pulyaevskaya, 2015). Воспользуемся методиками Института экономики города [1]. Выберем одну из 6 имеющихся у него методик. Приведем несколько допущений расчета ВМП:
1. Оценка будет производиться без учета отраслей (что снизит трудоемкость исследования).
2. Доля ненаблюдаемых доходов будет статичной и равна 27% (цифра обоснована в исследовании Института экономики города).
ВМП рассчитывается по формуле:
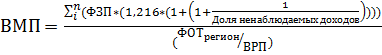 (1)
(1)
где:
а) ФЗП – фонд заработной платы каждого муниципалитета;
б) 1,216 – коэффициент для учета социальных взносов;
в) доля ненаблюдаемых доходов – разнообразные доходы, связанные с работой, но неучтенные статистикой (показатель спорный, но применим его, следуя рекомендациям Института экономики города, его размер берется в 27%, цифра получена ИЭГ эмпирически и может меняться);
г) ФОТ региона – фонд оплаты труда региона;
д) ВРП – валовый региональный продукт.
Фактически ВМП в данной форме коррелирует с фондом заработной платы по муниципалитетам. Согласно методологии PLS-SEM, можно предложить результирующую группу (а не один показатель), т.е. некое «региональное/муниципальное развитие», в котором объединить показатели ВМП и среднемесячной заработной платы. Это целесообразно, так как экономическое развитие должно отражаться непосредственно на улучшении уровня жизни населения. В качестве набора результирующих переменных предложим абсолютные и относительные показатели по ВМП и заработной плате. Все они составят одну результирующую скрытую переменную в программе SmartPLS3 (далее – применяем собирательное название для нее – ВМП).
На ВМП влияют группы факторов, отражающие степень концентрации ресурсов, описывая тем самым предпосылки агломерационного эффекта. В каждой группе факторов может быть несколько показателей, соответственно, каждый набор таких показателей формирует комплексную скрытую переменную, например демография территории.
При этом нужно учитывать, что группы факторов могут действовать на результат напрямую или же косвенно. Тем самым сформируется два уровня моделей:
1. Внутренняя модель: влияние групп факторов друг на друга и на ВМП.
2. Внешние модели: взаимовлияние набора показателей и скрытой переменной (для каждой скрытой переменной составляется своя внешняя модель).
Пояснение внутренней модели проведем в виде гипотез, которые необходимо количественно проверить. Не все показатели для факторов доступны в данных Росстата, поэтому применяются только те показатели, которые находятся в открытом доступе. Сформулируем гипотезы исследования (табл. 1).
Таблица 1
Выдвигаемые гипотезы исследования
|
Конструкция
|
Описание гипотезы
|
Номер гипотезы
|
|
Прямое влияние
| ||
|
Факторы
эффекта урбанизации
|
Концентрация численности населения,
качество населения, плотность населения, объем экономики, общеотраслевая
инфраструктура, диверсификация экономики (группа факторов – эффект
урбанизации) имеют прямую зависимость с ВМП. Крупные поселения более
эффективны
|
H1
|
|
Факторы
эффекта локализации
|
Концентрация предприятий определенного
вида экономической деятельности (отрасли экономики), объем экономики определенной
отрасли экономики, численность занятых на предприятиях определенной отрасли,
специализация экономики (группа факторов – эффект локализации) имеют прямую
зависимость с ВМП. Территориально-производственные комплексы («кластеры»
более эффективны)
|
H2
|
|
Факторы
эффекта масштаба
|
Рост масштабов выпуска и занятости на
определенном предприятии, степень монополизации экономики, индекс
Херфиндаля-Хиршмана (группа факторов – эффект масштаба) имеют прямую
зависимость с ВМП. Крупные предприятия более эффективны
|
H3
|
|
Институциональные
факторы
|
Наличие институциональной системы
управления агломерацией, переход на централизованные модели управления
агломерацией, снижение фрагментации власти в агломерации (группа факторов – институты)
имеют прямую зависимость с ВМП
|
H4
|
|
Косвенное влияние
| ||
|
Анализ
посредничества (факторы урбанизации → институты)
|
Анализ посредничества: ряд факторов эффекта
урбанизации влияют на формирование институтов системы управления агломерацией
|
H5
|
|
Анализ
посредничества (система расселения → институты)
|
Анализ посредничества: структура
системы расселения населения и ее сбалансированность (правило Ципфа), принадлежность
к ядру/периферии агломерации (диаграмма рассеяния индекса Морана), соседское
влияние на муниципалитеты, транспортно-географическая доступность, количество
поселений (группа факторов – эффект системы расселения) влияют на
формирование институтов системы управления агломерацией
|
H6
|
|
Анализ
посредничества (система расселения → факторы урбанизации)
|
Анализ
посредничества: факторы системы расселения влияют на ряд факторов эффекта урбанизации
|
H7
|
|
Анализ
посредничества (система расселения → факторы локализации)
|
Анализ
посредничества: факторы системы расселения влияют на ряд факторов эффекта
локализации
|
H8
|
|
Анализ
посредничества (факторы урбанизации → факторы урбанизации)
|
Анализ посредничества: ряд факторов
эффекта урбанизации влияют на некоторые другие факторы эффекта урбанизации
|
H9
|
|
Анализ
посредничества (факторы локализации → факторы локализации)
|
Анализ посредничества: факторы
локализации влияют на другие факторы локализации
|
H10
|
Любые отрицательные/нелогичные последствия для ВМП от концентрации населения, ресурсов, экономики будут в таком случае относиться к факторам дезагломерации.
Тем самым в работе сформировано несколько теоретических конструкций, которые объединяют в себе влияние факторов агломерационного эффекта. Главные группы факторов перечислены выше, каждая группа факторов может быть декомпозирована на более мелкие подгруппы факторов, объединенные по логическому/статистическому принципу:
1. Группа факторов «Эффект урбанизации».
1.1. Подгруппа «Демография».
1.2. Подгруппа «Жилье».
1.3. Подгруппа «Занятость».
1.4. Подгруппа «Инвестиции».
1.5. Подгруппа «Предпринимательство (все отрасли)».
1.6. Подгруппа «Предприятия (все отрасли)».
1.7. Подгруппа «Социальная сфера».
1.8. Подгруппа «Транспорт».
2. Группа факторов «Эффект локализации».
2.1. Подгруппа «Предпринимательство (по отдельным отраслям)».
2.2. Подгруппа «Предприятия (по отдельным отраслям)».
3. Группа факторов «Эффект масштаба».
3.1. Подгруппа «Эффект масштаба».
4. Группа факторов «Эффект системы расселения».
4.1. Подгруппа «Система расселения».
5. Группа факторов «Институциональные факторы».
5.1. Подгруппа «Институты».
Схематично модель агломерационного эффекта можно представить таким образом (покажем т.н. внутреннюю модель) (рис. 1).
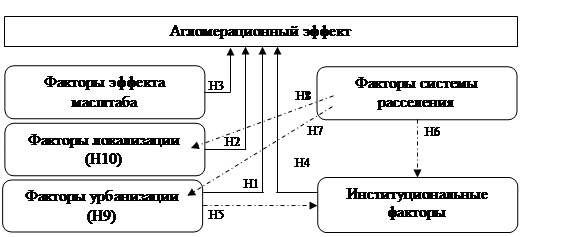
Рисунок 1. Теоретическая модель агломерационного эффекта.
Примечание: непрерывными стрелками отмечено прямое влияние на агломерационный эффект; прерывистыми стрелками – косвенное влияние на агломерационный эффект; номера гипотез в скобках – косвенное влияние на агломерационный эффект.
Источник: составлено авторами.
Допущения исследования:
- Восстановление пропусков в данных осуществляется на основе регрессионных моделей. Если построить регрессию невозможно (например, одно наблюдение), то применяется метод повторения результата последнего наблюдения.
Применение метода PLS-SEM подразумевает следующие преимущества:
1) можно обрабатывать множество факторных переменных, несмотря даже на наличие мультиколлинеарности между ними [7; с. 8] (Garson, 2016, р. 8);
2) работа сразу с несколькими независимыми и зависимыми переменными;
3) нетребовательность к большой выборке данных (количество переменных может даже быть больше, чем количество наблюдений);
4) может работать даже при наличии пропусков данных (отсутствии значений по некоторым переменным в некоторых периодах, в отличие от регрессии);
5) нет требований к нормальному распределению исходных данных.
Данные исследования
Данные для моделирования включали 2013–2021 годы по 10 городским округам Самарской области, что позволило получить 90 единиц наблюдений. Внутренняя модель исследования включает в себя набор конструкций. Выбрано 4 результирующих показателей и 21 факторных (табл. 2, 3).
Таблица 2
Факторные показатели
|
Подгруппа факторов
|
Обозначение показателя
|
Показатель
|
|
Гипотеза H1, H5
| ||
|
Демография
|
Население
|
Оценка
численности населения на 1 января текущего года, человек, на 1 января, все
население
|
|
Жилье
|
Жилфонд
|
Общая
площадь жилых помещений, тысяча метров квадратных, значение показателя за
год, Весь жилищный фонд
|
|
Занятость
|
Работники
|
Среднесписочная
численность работников организаций, человек, всего
|
|
РаботникиП
|
Плотность
занятости, чел/км
| |
|
Инвестиции
|
Инвестиции
|
Инвестиции
в основной капитал, осуществляемые организациями, находящимися на территории
муниципального образования (без субъектов малого предпринимательства), тысяча
рублей, в ценах 2013 г.
|
|
ИнвестицииП
|
Плотность
инвестиций в ценах 2013 года, тыс. руб. на 1 км
| |
|
Предпринимательство
(все отрасли)
|
Товары
|
Отгружено
товаров собственного производства, выполнено работ и услуг собственными
силами (без субъектов малого предпринимательства), тысяча рублей, цены 2013 г.
|
|
ТоварыП
|
Плотность
отгруженных товаров в ценах 2013 года, тыс. руб. на 1 км
| |
|
Предприятия
(все отрасли)
|
Предприятия
|
Количество
хозяйствующих субъектов по данным бухгалтерской отчетности, единица
|
|
Социальная
сфера
|
Образование
|
Уровень
образования населения (на 1000 человек в возрасте 15 лет и более, указавшие уровень
образования), промилле, высшее образование
|
|
Транспорт
|
ДорогиТ
|
Протяженность
автодорог общего пользования местного значения, на конец года, километр, с
твердым покрытием
|
|
Улицы
|
Общая
протяженность улиц, проездов, набережных (на конец отчетного года), километр
| |
|
Гипотеза H2
| ||
|
Предпринимательство
(по отдельным отраслям)
|
Розница
|
Оборот
розничной торговли (без субъектов малого предпринимательства), тысяча рублей,
в ценах 2013 г.
|
|
Предприятия
(по отдельным
отраслям)
|
ПредприятияБЫТ
|
Число
объектов бытового обслуживания населения, оказывающих услуги, значение
показателя за год
|
|
Гипотеза H3
| ||
|
Эффект
масштаба
|
Работников1
|
Работников
в среднем на 1 предприятие в отрасли
|
|
Гипотеза H6, H7, H8
| ||
|
Система
расселения
|
Площадь
|
Площадь,
км
|
|
Группа120
|
Группы
МО по населению в радиусе 120 км
| |
|
Кластер
|
Кластер
по диаграмме рассеяния Морана
| |
|
Ципф
|
Отклонение
фактической численности населения от идеальной, в % (если минус, то на
столько процентов нужно нарастить население до идеала от существующего
фактического значения)
| |
|
НаселениеП
|
Плотность
населения, чел/км
| |
|
Гипотеза H4
| ||
|
Институты
|
КССТА
|
Включение
в КС СТА
|
|
Примечание:
МО – муниципальное образование; КС СТА – Координационный совет
Самарско-Тольяттинской агломерации
| ||
Таблица 3
Результирующие показатели
|
Обозначение показателя
|
Показатель
|
|
ВМП
|
ВМП
в ценах 2013 года, тыс руб.
|
|
ВМПд
|
ВМП
в ценах 2013 года, тыс руб., на душу населения
|
|
ЗП
|
Среднемесячная
заработная плата работников организаций, рубль, в ценах 2013 г.
|
|
Примечание:
ВМП – валовый муниципальный продукт
| |
Некоторые показатели имеют обратную направленность (чем больше их значение, тем теоретически хуже для агломерационного эффекта, например, среднее расстояние от территории до остальных территорий). Однако программа SmartPLS3 укажет направленность взаимосвязи скрытой переменной и показателя, поэтому переводить в прямой вид показатели не будем.
Покажем построенную в Smart PLS итоговую структурную модель агломерационного эффекта после проведения многочисленных тестов гипотез (рис. 2).
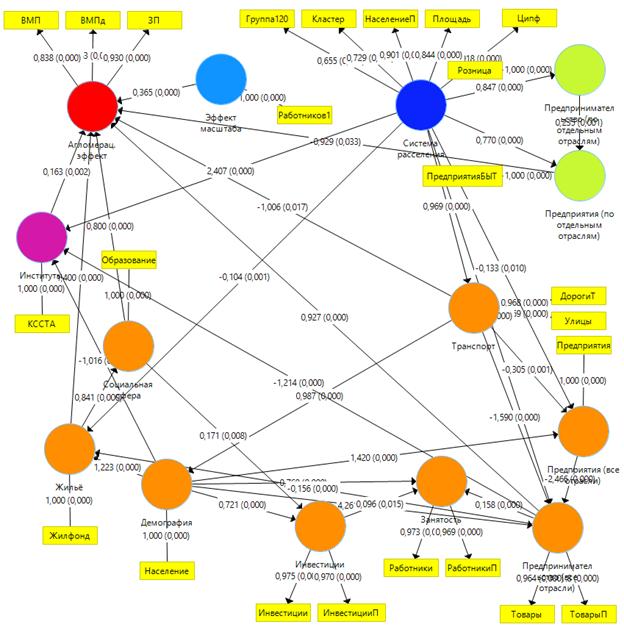
Рисунок 2. Теоретическая структурная модель агломерационного эффекта с коэффициентами пути (Path Coefficients)
Примечание: конструкты факторов эффекта урбанизации – оранжевый; конструкты факторов эффекта локализации – зеленый; конструкт факторов эффекта масштаба – голубой; конструкт факторов системы расселения – синий; конструкт институциональных факторов – фиолетовый; конструкт агломерационного эффекта – красный. Кругами выделены скрытые переменные, прямоугольниками – показатели.
Источник: построено авторами в SmartPLS3.
В предлагаемой теоретической модели представлены экзогенные, эндогенные и промежуточные скрытые переменные. Так, например, скрытая переменная Агломерационный эффект является эндогенной переменной (к ней идут стрелки от иных скрытых переменных, т.е. она определяется иными моделями), скрытая переменная Институты является переменной-посредником (стрелки к ней и от нее), скрытая переменная Система расселения – экзогенная (стрелки идут только от них, т.е. они определяют другие переменные) и т.д.
Построена рефлексивная модель, которая предполагает, что скрытая переменная может быть описана некой генеральной совокупностью показателей, из которых в модели представлена только их выборка.
Оценка силы и направленности влияния скрытых переменных на результат
Для оценки силы и направленности влияния скрытых переменных на результат был использован простой алгоритм PLS, который является стандартной процедурой частичного моделирования методом наименьших квадратов по умолчанию. Максимизация R2 происходит за счет большого количества итераций. В нашем случае проведено 300 итераций, установленных по умолчанию. В процессе итераций рассчитываются коэффициенты пути (Path Coefficients), они показывают силу и направленность влияния переменной на результат.
Коэффициенты следует оценивать таким образом: самое слабое влияние – при 0, чем дальше от 0, тем сильнее (положительное или отрицательное влияние). Коэффициенты пути можно сравнивать между собой, например, во сколько раз один фактор сильнее влияет по сравнению с другим фактором (например, коэффициенты 0,5 и -0,25 показывают разную направленность показателей и то, что один фактор сильнее другого в два раза). В итоге получены следующие оценки значимости скрытых переменных и направленности их влияния (табл. 4). Схема структурной модели с отметками силы связей показана на рисунке (рис. 2). Так как некоторые подгруппы факторов влияют на агломерационный эффект не только напрямую, но и опосредованно через другие подгруппы факторов, то можно разделить прямые, косвенные, совокупные эффекты.
Таблица 4
Оценка коэффициентов пути, их силы и направленности
|
Конструкты
|
Прямой
|
Косвенный
|
Совокупный
|
|
АЭ
|
АЭ
|
АЭ
| |
|
Демография
|
|
2,679
|
2,679
|
|
Жилье
|
1,400
|
0,673
|
2,073
|
|
Институты
|
0,163
|
|
0,163
|
|
Предпринимательство
(все отрасли)
|
0.927
|
-0,521
|
0,407
|
|
Предпринимательство
(по отдельным отраслям)
|
|
-0,218
|
-0,218
|
|
Предприятия
(все отрасли)
|
|
-1,003
|
-1,003
|
|
Предприятия
(по отдельным отраслям)
|
-0,929
|
|
-0,929
|
|
Система
расселения
|
|
0,933
|
0,933
|
|
Социальная
сфера
|
0,800
|
|
0,800
|
|
Транспорт
|
-1,006
|
2,304
|
1,298
|
|
Эффект
масштаба
|
0,365
|
|
0,365
|
Источник: составлено авторами в SmartPLS3.
Всего выявлено 193 косвенных связей между скрытыми переменными. Отдельно их отображать нет смысла, поэтому ограничимся пояснением, как считаются косвенные эффекты (фрагмент из выявленных 193 связей показан в таблице 5). Предположим, что была бы одна прямая и одна косвенная связь от Жилье к Агломерационному эффекту, проходящая через Социальную сферу. Косвенный эффект равен произведению прямых эффектов Жилья на Социальную сферу и Социальной сферы на Агломерационный эффект (например, приведем гипотетические цифры =0,1*0,02=0,002). Соответственно, совокупный эффект равен сумме прямого и косвенного эффекта (например, =0,3+0,002=0,302).
Таблица 5
Фрагмент косвенных связей и оценка их силы
|
Указан путь косвенной связи
|
Оценка силы косвенной связи по
выбранному пути
|
|
Транспорт ->
Предпринимательство (все отрасли) -> Жилье -> Агломерац. эффект
|
0,346
|
Анализ значимости конструктов на агломерационный эффект показал следующее в порядке убывания силы:
1. Факторы эффекта урбанизации (например, у Демографии – 3,079).
2. Факторы системы расселения.
3. Факторы эффекта локализации.
4. Факторы эффекта масштаба.
5. Институциональные факторы.
Покажем коэффициенты детерминации конструктов в предлагаемой модели (табл. 6). Коэффициент R2 для Агломерационного эффекта показывает 0,698; для Институтов – 0,575. Это значит, что такое значение вариации этих скрытых переменных объясняется предлагаемой моделью.
Таблица 6
Коэффициенты детерминации моделей скрытых переменных
|
Конструкт
|
Коэффициент детерминации конструкта (R2)
|
|
Агломерац.
эффект
|
0,863
|
|
Демография
|
0,975
|
|
Жилье
|
0,992
|
|
Занятость
|
0,966
|
|
Инвестиции
|
0,756
|
|
Институты
|
0,615
|
|
Предпринимательство
(все отрасли)
|
0,833
|
|
Предпринимательство
(по отдельным отраслям)
|
0,717
|
|
Предприятия
(все отрасли)
|
0,994
|
|
Предприятия
(по отдельным отраслям)
|
0,953
|
|
Социальная
сфера
|
0,708
|
|
Транспорт
|
0,939
|
Оценка вклада показателя в скрытую переменную
Нагрузки (Loadings) внешней модели находятся в центре внимания рефлективных моделей, представляющих пути от фактора к его репрезентативным показателям. Внешние нагрузки представляют собой абсолютный вклад показателя в определение его скрытой переменной. Нагрузки измерений (Loadings) представляют собой стандартизированные веса пути, связывающие факторы с показателями. Нагрузки варьируются от 0 до 1 по модулю, т.е от -1 до 1 [7; с. 61] (Garson, 2016, р. 61). Нагрузки должны быть значительными. В целом, чем больше нагрузки, тем прочнее и надежнее модель измерения. Надежность показателя можно интерпретировать как квадрат измерительной нагрузки: например, 708̂ 2 = надежность 0,50 [8, с. 103] (Hair Joseph, Hult Tomas, Ringle Christian, Sarstedt Marko, 2014, р. 103). Считается, что для хорошо подобранной отражающей модели нагрузки на пути должны быть выше 0,70 [10, с. 269] (Henseler Jörg, Ringle Christian, Sarstedt Marko, 2012, р. 269). Это связано с тем, что при нагрузке в 0,7 примерно половина дисперсии показателя объясняется его фактором, а также является уровнем, при котором объясненная дисперсия должна быть больше, чем дисперсия ошибки. Все вышеперечисленные показатели имеют нагрузку выше 0,7 за исключением показателя Группа 120 (значение 0,655). Его мы оставим в качестве исключения для более подробного учета пространственных факторов. Основанием служит то, что иногда такие допущения возможны для показателей со значением выше 0,5 [8, с. 129] (Hair Joseph, Hult Tomas, Ringle Christian, Sarstedt Marko, 2014, р. 129).
Оценка надежности модели
Для оценки модели необходимо разграничить понятия надежности, достоверности, валидности:
- надежность – степень устойчивости результатов при повторном измерении (т.е. оценивается степень разброса результатов при повторном измерении относительно друг друга, а не относительно истинного значения);
- достоверность – мера отклонения от истинного значения (т.е. оценивается отклонение от истины, а не от других результатов измерения);
- валидность – пригодность применяемого метода оценки.
Оценить надежность рефлективной модели (но не формативной!) можно с помощью проверки на конвергентную валидность (т.е. оценить, действительно ли есть связь между переменными, между которыми теоретически связь должна присутствовать) и на дискриминантную валидность (оценка того, что связь между двумя переменными, между которыми теоретической связи нет, отсутствует и фактически; подразумевается, что отобранные показатели для каждой скрытой переменной относятся действительно только к ней). Проверка по двум этим подходам позволяет сказать, что вся модель действительно валидна.
Конвергентная валидность оценивалась по двум методам: через получение таких мер, как совокупная надежность (composite reliability) или альфа Кронбаха [7, с. 63–65] (Garson, 2016, р. 63–65). Совокупная надежность является предпочтительной альтернативой альфа Кронбаха в качестве теста конвергентной валидности в рефлективной модели, потому что альфа Кронбаха может завышать или занижать надежность шкалы. По сравнению с альфой Кронбаха составная надежность может привести к более высоким оценкам истинной надежности. Приемлемое отсечение для составной надежности такое же, как и для любой меры надежности, включая альфа Кронбаха. Составная надежность варьируется от 0 до 1, где 1 соответствует идеальной оценочной надежности. В модели, подходящей для исследовательских целей, совокупная надежность должна быть равна или выше 0,6 [3; 11, с. 15] (Chin, 1998; Höck Michael, Ringle Christian, 2006, р. 15).
Также проведем оценку модели при помощи альфа Кронбаха (пороговое значение равно 0,6). Считается, что альфа Кронбаха имеет тенденцию занижать надежность модели. Шкала альфа Кронбаха от минус бесконечности до 1, но интерпретации поддаются только положительные значения.
Полученные данные по оценке надежности модели по мерам совокупной надежности, альфа Кронбаха для всех скрытых переменных составили больше 0,87.
Дискриминатная валидность оценивалась при помощи двух методов: усредненной извлеченной дисперсии (average variance extracted, AVE) и оценки гетеропризнака-монопризнака (Heterotrait-Monotrait Ratio (HTMT). AVE отражает среднюю общность для каждого скрытого фактора в рефлексивной модели. В адекватной модели AVE должен быть больше 0,5, а также больше, чем перекрестные загрузки, что означает, что факторы должны объяснять не менее половины дисперсии соответствующих показателей [3; 11, с. 15] (Chin, 1998; Höck Michael, Ringle Christian, 2006, р. 15). AVE ниже 0,50 означает, что дисперсия ошибки превышает объясненную дисперсию [6] (Fornell, Larcker, 1981). В нашем исследовании ограничимся простым сопоставлением по уровню 0,5.
Отсутствие дискриминантной валидности между скрытыми переменными обнаружим с помощью метода HTMT. Если значение HTMT меньше 1, то это означает, что между скрытыми переменными обнаружена дискриминантная валидность (т.е. действительно нет дублирования между показателями скрытых переменных) [9, с. 122] (Henseler Jörg, Ringle Christian, Sarstedt Marko, 2015, р. 122).
По результатам применения метода HTMT выявлены значения больше 1, что может означать наличие связи между показателями ряда пар скрытых переменных: Демография – Занятость, Транспорт – Жилье (а также с участием Транспорта – Занятость, Предприятия по всем отраслям, Предприятия по отдельным отраслям, Система расселения), Занятость – Система расселения, Система расселения – Предприятия по отдельным отраслям. Может присутствовать некая неуникальность отобранных показателей для перечисленных скрытых переменных. Вместе с тем второй способ оценки дискриминантной валидности по AVE позволяет нам оставить эти скрытые переменные в модели (в нашем случае все значения оказались выше 0,665).
Мультиколлинеарность среди показателей модели присутствует (что выявлено по таблице коэффициента фактора инфляции дисперсии – VIF в программе Smart PLS3), но в рамках рефлективной модели это не является проблемой, поэтому выбор рефлективной модели был верным [7, с. 71] (Garson, 2016, р. 71).
Как итог всех пройденных выше этапов – отбор значимых показателей для внешних моделей. Но теперь важно изучить внутреннюю модель, т.е. взаимосвязи между скрытыми переменными, о чем будет сказано далее.
Оценка уровня значимости гипотез
Для проверки выдвинутых гипотез применяется метод бутстраппинга (bootstrapping) в Smart PLS3. Суть метода в том, что из представленных значений показателей происходит поочередная случайная выборка всех значений за исключением одного, которое заменяется на пропущенное (например, на оговоренное число, применяемое при наличии пропусков в данных), для подвыборки происходит расчет оценки модели пути PLS. Для подсчета рекомендуется проводить не менее 5000 итераций. Так как проводимый процесс является случайным, то получаемые значения оценок могут незначительно отличаться при повторном проведении бутстраппинга [7, с. 111] (Garson, 2016, р. 111). Оценку вероятности верности гипотез проведем при помощи коэффициента p-value. Все гипотезы имеют значимость выше 95%. Таким образом, с вероятностью в 95% (на самом деле, выше) можно принять все выдвинутые гипотезы. Как итог этого этапа, построены взаимосвязи между скрытыми переменными, т.е. построена внутренняя модель.
Оценка объяснительной силы скрытой переменной
Скрытые переменные можно сравнить между собой на предмет того, насколько силен вклад каждой из них в объяснение вариации результирующей переменной. Для этого есть показатель f2, который показывает, насколько изменится процент детерминации в модели при исключении той или иной скрытой переменной. Интерпретация коэффициентов f2 следующая: 0,02 представляет собой «маленький» размер эффекта, 0,15 – «средний» эффект, а 0,35 представляет «высокий» размер эффекта [5] (Cohen, 1988). Покажем результаты в таблице 7. По сути, этот коэффициент показывает то, можно ли доверять полученным результатам при выявлении коэффициентов пути (path coefficients).
Таблица 7
Значения f2
|
Конструкт
|
Агломерационный эффект
|
|
Демография
| |
|
Жилье
|
0,334
|
|
Занятость
|
|
|
Инвестиции
|
|
|
Институты
|
0,112
|
|
Предпринимательство
(все отрасли)
|
0,285
|
|
Предпринимательство
(по отдельным отраслям)
| |
|
Предприятия
(все отрасли)
| |
|
Предприятия
(по отдельным отраслям)
|
0,056
|
|
Система
расселения
| |
|
Социальная
сфера
|
0,402
|
|
Транспорт
|
0,095
|
|
Эффект
масштаба
|
0,212
|
Исходя из коэффициента f2, все скрытые переменные являются значимыми. Их вклад в объяснение вариации агломерационного эффекта колеблется от высокого (социальная сфера и др.) до низкого (институты). Нет ни одной скрытой переменной (среди тех, которые влияют на агломерационный эффект), влияние которой бы не имело силы.
Анализ карты важности и производительности (IPMA)
Карта важности и производительности (IPMA) группирует данные о важности скрытой переменной в объяснении вариации эндогенной переменной с данными о силе и направленности этих скрытых переменных. Эти сведения могут помочь в определении приоритетов в управленческих действиях: предпочтительнее в первую очередь сосредоточиться на повышении производительности тех конструктов, которые имеют большое значение в отношении их объяснения определенного целевого конструкта, но в то же время имеют относительно низкую производительность (т.е. сначала нужно отобрать конструкты с высоким совокупным эффектом, а затем из них – с низкой производительностью) [7, с. 129] (Garson, 2016, р. 129). Результаты покажем на рисунке 3.
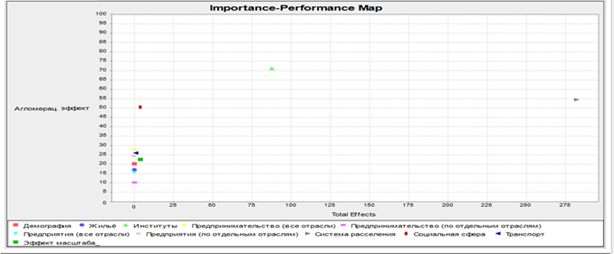
Рисунок 3. Карта важности и производительности (IPMA)
Примечание: данная карта получена при помощи процедуры Importance-Performance Map Analysis (IPMA) в программе SmartPLS3.
Источник: составлено авторами в SmartPLS3.
Выбор скрытых переменных для первичного управленческого воздействия осуществляется по алгоритму:
1. Отбор самых значительных по совокупному эффекту.
2. Отбор самых слабых по производительности.
По итогам исследования предлагается развивать следующие конструкты:
1. Эффект системы расселения. Конструкт – Система расселения (самый большой эффект).
2. Институциональное влияние. Конструкт – Институты.
3. Эффект локализации. Конструкт – Предпринимательство (по отдельным отраслям).
Их развитие является перспективным для получения агломерационного эффекта в городских округах Самарской области.
Заключение
По итогам проведенного исследования с помощью методологии PLS-SEM была построена структурная модель агломерационного эффекта для Самарской области. В данной модели для каждой группы факторов агломерационного эффекта сформированы свои конструкты (скрытые переменные). В рамках каждой скрытой переменной представлены показатели. Всего рассматривалось 5 групп факторов агломерационного эффекта (факторы эффекта масштаба, локализации, урбанизации, системы расселения институционального управления). Некоторые группы факторов были разложены на ряд подгрупп, например, в совокупном наборе скрытых переменных для эффекта урбанизации представлены такие сферы, как демография, жилье, транспорт и т.п. Всего было сформировано 13 скрытых переменных, оказывающих влияние на 1 результирующую скрытую переменную (агломерационный эффект). После многочисленных итераций по изучению всевозможных гипотез о взаимосвязи в модели остались 21 факторный и 3 результирующих показателя.
Коэффициент детерминации R2 скрытой переменной «Агломерационный эффект» показал довольно высокое значение в 86,3%. Надежность модели была проверена через меры совокупной надежности, Альфа Кронбаха, усредненной извлеченной дисперсии и оценки гетеропризнака-монопризнака.
Все выдвинутые 10 гипотез доказаны с уровнем значимости 95% (по p-value). На агломерационный эффект в рамках СТА наибольшее влияние оказывают скрытые переменные группы факторов эффекта урбанизации, затем эффекта системы расселения, эффекта локализации (но у него отрицательное влияние).
По результатам исследования построена карта «важность – производительность» (IPMA). По ней выявлено, что особенные перспективы для развития агломерационного эффекта имеются в конструктах системы расселения, институтов, предпринимательства (по отдельным отраслям).
Ограничением данного исследования является то, что предлагаемая модель актуальна только для части одного региона – Самарской области. Для иных регионов данная модель может выступить только в качестве заготовки, которую придется дорабатывать. Кроме того, накладывает свои риски характер располагаемых статистических данных (данные не за все годы известны, достройка пропущенных данных по некоторым показателям и т.п.).
Развить исследование возможно через получение более полной муниципальной статистики от органов статистического наблюдения, через рассмотрение региона как точки и построение модели для региона в таком восприятии, через построение моделей для иных регионов России.
[1] Методика оценки валового городского продукта городов и городских агломераций. Фонд «Институт Экономики Города». Москва. 2017 [Электронный ресурс]. URL: https://urbaneconomics.ru/sites/default/files/metodvgp.pdf (дата обращения: 11.10.2022).
Источники:
2. Brulhart M., Sbergami F. Agglomeration and growth: Cross-country evidence // Journal of Urban Economics. – 2009. – № 65. – p. 48–63.
3. Chin W. W. The partial least squares approach for structural equation modeling. / in Macoulides, G. A., ed. Modern methods for business research. - Mahwah, NJ: Lawrence Erlbaum Associates, 1998. – 295-336 p.
4. Ciccone A., Hall R. Productivity and the density of economic activity // The American Economic Review. – 1996. – № 86(1). – p. 54-70.
5. Cohen J. Statistical power analysis for the behavioral sciences. - Mahwah, NJ: Lawrence Erlbaum, 1988.
6. Fornell C., Larcker D. F. Evaluating structural equation models with unobservable variables and measurement error // Journal of Marketing Research. – 1981. – № 18. – p. 39-50.
7. Garson G.D. Partial Least Squares: Regression & Structural Equation Models. , 2016. – 262 p.
8. Hair Joseph F. Jr., Hult G. Tomas M., Ringle Christian M., Sarstedt Marko A primer on partial least squares structural equation modeling (PLS-SEM). - Thousand Oaks, CA: Sage Publications, 2014.
9. Henseler Jörg, Ringle Christian, Sarstedt Marko A New Criterion for Assessing Discriminant Validity in Variance-based Structural Equation Modeling // Journal of the Academy of Marketing Science. – 2015. – № 43. – p. 115-135. – doi: 10.1007/s11747-014-0403-8.
10. Henseler Jörg, Ringle Christian M., Sarstedt Marko Using partial least squares path modeling in international advertising research: Basic concepts and recent issues. / in Okzaki, S., ed. Handbook of partial least squares: Concepts, methods and applications in marketing and related fields. - Berlin: Springer, 2012. – 252-276 p.
11. Höck Michael, Ringle Christian M. Strategic networks in the software industry: An empirical analysis of the value continuum. - IFSAM VIIIth World Congress, Berlin, 2006.
12. Воробьев П. В., Давидсон Н. Б., Кисляк Н. В., Кузнецов П. Д. Разнообразие и концентрация отраслей в российских городах как факторы экономической эффективности // Вестник УрФУ. Серия: Экономика и управление. – 2014. – № 6. – c. 4-18.
13. Гончар К. Р., Ратникова Т. А. Оценка и объяснение городских агломерационных эффектов для обрабатывающей промышленности России // XIV Апрельская международная научная конференция по проблемам развития экономики и общества: отв. ред.: Е. Г. Ясин. / в 4-х книгах. Книга 3. - М.: Издательский дом НИУ ВШЭ. 2014. – c. 55-64.
14. Драпкин И. М., Мариев О. С., Семенова Е. О., Колягина А. И. Факторы пространственного размещения фирм в российской экономике: региональный аспект // Вестник УрФУ. Серия: Экономика и управление. – 2016. – № 15(5). – c. 717-733. – doi: 10.15826/vestnik.2016.15.5.036.
15. Зеленков Ю. А., Цветков В. А., Солнцев И. В. Сравнительная оценка эффективности развития спорта на региональном уровне на основе метода DEA // Экономика региона. – 2017. – № 4. – c. 1184-1198. – doi: 10.17059/2017-4-17.
16. Зубаревич, Н.В. Развитие крупных городов России: только ли размер имеет значение?. / Н. В. Зубаревич; под ред. А. П. Заостровцева, Л. Э. Лимонова / Экономика и география. - СПб.: Международный центр социально-экономических исследований «Леонтьевский центр», 2013. – 198-211 c.
17. Ковалева Т. Ю. Алгоритм идентификации и оценки кластеров в экономике региона // Вестник ПГУ. Серия: Экономика. – 2011. – № 4.
18. Куковеров М.В. Экономия от масштаба на розничном рынке электроэнергии России: об одной естественной и одной неестественной монополии // Пространственная экономика. – 2018. – № 4. – c. 39–66. – doi: 10.14530/se.2018.4.039-066.
19. Павлинова Е. И. Об оценке равномерности территориального развития промышленного производства России // Бизнес. Образование. Право. – 2019. – № 1(46). – c. 314-321. – doi: 10.25683/VOLBI.2019.46.129.
20. Павлов Ю.В. Баланс системы расселения региона: оценка по закону Ципфа и влияние на региональное развитие // Вопросы территориального развития. – 2020. – № 2. – doi: 10.15838/tdi.2020.2.52.1.
21. Пуляевская В. Л. Валовой муниципальный продукт в оценке уровня экономического развития Республики Саха (Якутия) // Вестник НГУЭУ. – 2015. – № 4. – c. 135-144.
22. Растворцева С.Н. Экономическая активность регионов России // Экономические и социальные перемены: факты, тенденции, прогноз. – 2018. – № 1. – c. 84-99. – doi: 10.15838/esc/2018.1.55.6.
23. Толмачев М. Н. Обобщающая оценка концентрации сельскохозяйственного производства // Вестник Новосибирского государственного университета. Серия: Социально-экономические науки. – 2011. – № 1. – c. 46-53.
24. Хмелева Г.А., Неделька Э. Эмпирическое исследование внешнеторговой деятельности Венгрии: «умные» инвестиции в инновации и транспортную инфраструктуру // Вопросы инновационной экономики. – 2021. – № 4. – c. 1987-1996. – doi: 10.18334/vinec.11.4.113984.
Страница обновлена: 08.07.2026 в 22:29:40
Download PDF | Downloads: 84 | Citations: 4
Assessing the impact of agglomeration effects on the economic development of Samara region's urban districts
Pavlov Y.V., Khmeleva G.A.Journal paper
Journal of Economics, Entrepreneurship and Law
Volume 12, Number 10 (October 2022)
Abstract:
The concentration of resources, enterprises, and population in cities creates conditions for the agglomeration effect. The article examines the influence of the agglomeration effect factors on the gross municipal product in the urban districts of the Samara region. Due to the presence of cross-influence of factors on each other, the usual regression single-factor or multi-factor model may not fully reflect socio-economic dependencies. To build the most accurate model of these dependencies, PLS is used with the construction of a model that reflects cause-and-effect relationships between blocks of conditional variables. The foreign computer program SmartPLS3 is used to build the model. The novelty of the study lies in the identification of cause-and-effect relationships in the formation of agglomeration effects. As a result of the study, priorities for the development of individual socio-economic blocks to accelerate the development of urban districts of the Samara region were identified.
Keywords: agglomeration effect, agglomeration effect factors, localization effect, urbanization effect, disaggregation, agglomeration
JEL-classification: R11, R12, R13
References:
Ahrend R. (2014). What Makes Cities More Productive? Evidence on the Role of Urban Governance from Five OECD Countries
Brulhart M., Sbergami F. (2009). Agglomeration and growth: Cross-country evidence Journal of Urban Economics. (65). 48–63.
Chin W. W. (1998). The partial least squares approach for structural equation modeling
Ciccone A., Hall R. (1996). Productivity and the density of economic activity The American Economic Review. (86(1)). 54-70.
Cohen J. (1988). Statistical power analysis for the behavioral sciences
Drapkin I. M., Mariev O. S., Semenova E. O., Kolyagina A. I. (2016). Faktory prostranstvennogo razmeshcheniya firm v rossiyskoy ekonomike: regionalnyy aspekt [Determinants of spatial location in the russian economy: regional aspect]. Vestnik UrFU. Seriya: Ekonomika i upravlenie. (15(5)). 717-733. (in Russian). doi: 10.15826/vestnik.2016.15.5.036.
Fornell C., Larcker D. F. (1981). Evaluating structural equation models with unobservable variables and measurement error Journal of Marketing Research. (18). 39-50.
Garson G.D. (2016). Partial Least Squares: Regression & Structural Equation Models
Gonchar K. R., Ratnikova T. A. (2014). Otsenka i obyasnenie gorodskikh aglomeratsionnyh effektov dlya obrabatyvayushchey promyshlennosti Rossii [Assessment and explanation of urban agglomeration effects for the Russian manufacturing industry] 14th April International Scientific Conference on Problems of Economic and Social Development. 55-64. (in Russian).
Hair Joseph F. Jr., Hult G. Tomas M., Ringle Christian M., Sarstedt Marko (2014). A primer on partial least squares structural equation modeling (PLS-SEM)
Henseler Jörg, Ringle Christian M., Sarstedt Marko (2012). Using partial least squares path modeling in international advertising research: Basic concepts and recent issues
Henseler Jörg, Ringle Christian, Sarstedt Marko (2015). A New Criterion for Assessing Discriminant Validity in Variance-based Structural Equation Modeling Journal of the Academy of Marketing Science. (43). 115-135. doi: 10.1007/s11747-014-0403-8.
Höck Michael, Ringle Christian M. (2006). Strategic networks in the software industry: An empirical analysis of the value continuum
Khmeleva G.A., Nedelka E. (2021). Empiricheskoe issledovanie vneshnetorgovoy deyatelnosti Vengrii: «umnye» investitsii v innovatsii i transportnuyu infrastrukturu [Empirical study of Hungary's foreign trade: smart investment in innovation and transport infrastructure]. Russian Journal of Innovation Economics. 11 (4). 1987-1996. (in Russian). doi: 10.18334/vinec.11.4.113984.
Kovaleva T. Yu. (2011). Algoritm identifikatsii i otsenki klasterov v ekonomike regiona [Algorithm for identification and evaluation of clusters in the economy of the region]. Perm University Herald. ECONOMY. (4). (in Russian).
Kukoverov M.V. (2018). Ekonomiya ot masshtaba na roznichnom rynke elektroenergii Rossii: ob odnoy estestvennoy i odnoy neestestvennoy monopolii [Economy of scale in russian retail electricity market: on one natural and one unnatural monopoly]. Spatial Economics. (4). 39–66. (in Russian). doi: 10.14530/se.2018.4.039-066.
Pavlinova E. I. (2019). Ob otsenke ravnomernosti territorialnogo razvitiya promyshlennogo proizvodstva Rossii [Assessment of the uniformity of territorial development of industrial production in Russia]. Business. Education. Law. (1(46)). 314-321. (in Russian). doi: 10.25683/VOLBI.2019.46.129.
Pavlov Yu.V. (2020). Balans sistemy rasseleniya regiona: otsenka po zakonu Tsipfa i vliyanie na regionalnoe razvitie [Regional settlement system balance: assessment under zipf’s law and impact on the regional development]. Territorial development issues. (2). (in Russian). doi: 10.15838/tdi.2020.2.52.1.
Pulyaevskaya V. L. (2015). Valovoy munitsipalnyy produkt v otsenke urovnya ekonomicheskogo razvitiya Respubliki Sakha (Yakutiya) [Gross municipal product assessing the level of economic development of the Republic of Sakha (Yakutia)]. Vestnik NSUEM. (4). 135-144. (in Russian).
Rastvortseva S.N. (2018). Ekonomicheskaya aktivnost regionov Rossii [Economic activity in Russian regions]. Economic and Social Changes: Facts, Trends, Forecast. (1). 84-99. (in Russian). doi: 10.15838/esc/2018.1.55.6.
Tolmachev M. N. (2011). Obobshchayushchaya otsenka kontsentratsii selskokhozyaystvennogo proizvodstva [General evaluation of the concentration of agricultural production]. Vestnik Novosibirskogo gosudarstvennogo universiteta. Seriya: Sotsialno-ekonomicheskie nauki. (1). 46-53. (in Russian).
Vorobev P. V., Davidson N. B., Kislyak N. V., Kuznetsov P. D. (2014). Raznoobrazie i kontsentratsiya otrasley v rossiyskikh gorodakh kak faktory ekonomicheskoy effektivnosti [Industrial diversity and concentration in the russian cities as factors of economic efficiency]. Vestnik UrFU. Seriya: Ekonomika i upravlenie. (6). 4-18. (in Russian).
Zelenkov Yu. A., Tsvetkov V. A., Solntsev I. V. (2017). Sravnitelnaya otsenka effektivnosti razvitiya sporta na regionalnom urovne na osnove metoda DEA [Comparative assessment the of effectiveness of sports development in the Russian regions on the basis of DEA method]. Economy of the region. (4). 1184-1198. (in Russian). doi: 10.17059/2017-4-17.
Zubarevich, N.V. (2013). Razvitie krupnyh gorodov Rossii: tolko li razmer imeet znachenie? [Development of large cities in Russia: is size the only thing that matters?] (in Russian).