Экономика искусственного интеллекта: тенденции, комплаенс, глобальное влияние
Воловик А.М.1
1 Российская академия естественных наук, ,
Скачать PDF | Загрузок: 85
Статья в журнале
Экономическая безопасность (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 7, Номер 9 (Сентябрь 2024)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=74169618
Аннотация:
В работе исследованы состояние и особенности регулирования ИИ на глобальном и национальном уровнях. Проведён аналитический обзор разработок в области ИИ. Рассмотрены риски и этические аспекты нерегулируемой разработки ИИ. Определены глобальные перспективы регулирования ИИ.
По данным «Отчета о глобальном регулировании ИИ» проанализирована эффективность текущей политики в области ИИ в региональном разрезе, которая находится на низком уровне.
Проведён сравнительный анализ показателей «Инвестиции в ИИ» и «Разработка программного обеспечения ИИ» в США, Китае, России. Данный анализ позволил выявить высокий уровень значений у США и очень низкий у России.
По результатам исследования предложен алгоритм действий по регулированию ИИ на глобальном уровне, с учётом национальных потребностей.
Сделан вывод, что в целях адекватного глобального управления ИИ необходимо фундаментальное понимание общих тем и национальных различий
Ключевые слова: искусственный интеллект, технологии, риски, глобальное влияние, экономика, политика регулировании искусственного интеллекта, комплаенс (соответствие требованиям)
JEL-классификация: O31, O32, O33
Введение. В настоящее время модели машинного обучения (МО) отлично справляются с задачей использования огромной вычислительной мощности для структурирования неструктурированных данных, что приводит к появлению приложений на основе технологий искусственного интеллекта (ИИ), которые получили быстрое и широкое распространение во многих областях. Развитие ИИ оказывает влияние на финансово-экономическую систему и ее стабильность/безопасность, а также на макроэкономические результаты через изменения совокупного предложения (через производительность) и спроса (через инвестиции, потребление и заработную плату) [7; 16].
Появление больших языковых моделей (LLM) вывело генеративный ИИ в активный дискурс. LLM изменили способ взаимодействия людей с компьютерами – от кода и программных интерфейсов к обычному тексту и речи. Эта способность общаться на обычном языке, а также человеческие возможности генеративного ИИ в создании контента захватили массовое воображение. Новым является возможность привносить математический порядок в масштабе повседневных неструктурированных данных, будь то текст, изображения, видео или музыка. Современные разработки ИИ стали возможны благодаря следующим факторам [18]:
– накоплению огромных массивов данных;
– LLM, опирающихся на всю совокупность текстовой и аудиовизуальной информации, доступной в Интернете;
– огромной вычислительной мощности оборудования последнего поколения, например, квантовых компьютеров.
Перечисленные элементы преобразовывают модели ИИ в высокоточные машины прогнозирования, обладающие способностью обнаруживать закономерности в данных и заполнять пробелы. Поэтому потребность во всеобъемлющем регулировании ИИ никогда не была столь актуальной и необходимой.
Цель исследования содержится в выявлении состояния и особенностей регулирования ИИ на глобальном и национальном уровнях.
Задачи исследования:
– провести аналитический обзор разработок в области ИИ;
– рассмотреть риски и этические аспекты нерегулируемой разработки ИИ;
– выявить глобальные перспективы регулирования ИИ.
Практическая значимость работы заключается в том, что в ней комплексно исследована проблематика управления и применения ИИ на глобальном уровне, что является определяющим для развития национального и международно-правового регулирования в данной сфере.
Аналитический обзор разработок в области ИИ. ИИ – это широкий термин, относящийся к компьютерным системам, выполняющим задачи, требующие человеческого интеллекта. Технологические достижения в области машинного обучения (МО) в 1990-х гг. заложили основы современного поколения моделей ИИ. Машинное обучение – это собирательный термин, относящийся к методам, разработанным для обнаружения закономерностей в данных и использования их в прогнозировании или для помощи в принятии решений [20].
Развитие глубокого обучения в 2010-х гг. стало следующим этапом в активном проникновении ИИ в различные сферы экономики. Глубокое обучение использует нейронные сети, лежащие в основе приложений, таких как распознавание лиц и голосовые помощники. Основным строительным блоком нейронных сетей являются искусственные нейроны, принимающие несколько входных значений, и преобразующих их в выходные данные в виде набора чисел, которые можно с легкостью проанализировать [15]. Искусственные нейроны организованы таким образом, чтобы сформировать последовательность слоев, которые можно накладывать друг на друга: нейроны первого слоя принимают входные данные и выводят значение активации. Последующие слои принимают выходные данные предыдущего слоя в качестве входных данных, преобразуют их и выводят другое значение, и так далее. Глубина сети относится к количеству слоев, позволяющих нейронным сетям фиксировать все более сложные взаимосвязи в данных. Веса, определяющие прочность связей между различными нейронами и слоями, в совокупности называются параметрами, которые улучшаются итеративно во время обучения.
Ключевым преимуществом моделей глубокого обучения является их способность работать с неструктурированными данными [4]. Они достигают этого путем «встраивания» качественных, категориальных или визуальных данных, таких как слова, предложения или изображения, в массивы чисел (подход, примененный в масштабе моделью Word2Vec [1]). Эти массивы чисел, то есть векторы, интерпретируются как точки в векторном пространстве. Расстояние между векторами передает некоторую размерность сходства, позволяя производить алгебраические манипуляции с тем, что изначально является качественными данными. Например, вектор, связывающий встраивания слов «big» и «biggest» очень похож на вектор между «small» и «smallest». Word2Vec предсказывает слово на основе окружающих слов в предложении. Текстовый массив можно взять из открытого интернета через базу данных «Common Crawl» [2]. Концепцию внедрения можно в дальнейшем использовать для картирования пространства экономических идей, выявляя скрытые перспективы или методологические подходы отдельных экономистов/институтов. Пространство идей также может быть связано с конкретными политическими действиями, например, решения по денежно-кредитной политике [5].
В отличие от Word2Vec, LLM могут улавливать нюансы перевода нераспространенных языков, отвечать на неоднозначные вопросы. LLM основанные на модели «Transformer» [3] полагаются на механизмы «многоцелевого внимания» и «позиционного кодирования» для эффективной оценки контекста любого слова в документе. Контекст влияет на то, как слова с несколькими значениями отображаются в массивах чисел. Например, «бонд» может относиться к ценной бумаге с фиксированным доходом, связи или ссылке. В зависимости от контекста, вектор встраивания «бонда» геометрически ближе к таким словам, как «казначейство», «нетрадиционный» и «политика». Эти разработки позволили ИИ перейти от систем, решающих одну конкретную задачу, к более общим системам с широким спектром задач.
«LLM являются ярким примером приложений ИИ нового поколения из-за способности генерировать точные ответы» [9]. До появления LLM, модели МО обучались решению одной задачи (например, классификации изображений, анализа настроений или перевода с немецкого языка на английский). Для этого пользователю необходимо было закодировать, обучить и внедрить модель в производство после получения достаточного количества данных. LLM обладает способностями обучения без лишних сложностей. Более того, он демонстрирует значительную универсальность в диапазоне задач, которые он может выполнять. Таким образом, LLM нового поколения позволили людям, используя обычный язык, автоматизировать задачи, которые ранее выполнялись узкоспециализированными моделями.
Возможности новейших моделей ИИ подкреплены достижениями в области данных и вычислительной мощности. Растущая доступность данных играет ключевую роль в обучении и улучшении моделей. Чем больше данных используется для обучения модели, тем более эффективной она становится. Кроме того, модели МО с большим количеством параметров улучшают прогнозы, если обучаются с достаточным количеством данных. В отличие от общепринятого мнения о том, что «чрезмерная параметризация» ухудшает способность моделей к прогнозированию, более поздние данные свидетельствуют о том, что модели МО устойчивы к чрезмерной параметризации [19]. Как следствие, LLM с хорошо спроектированными механизмами обучения могут предоставлять более точные прогнозы, чем традиционные параметрические модели в различных сценариях, таких как компьютерное зрение, обработка естественного языка (NLP) и сигналов [17].
Со временем Word2Vec был заменен другими моделями, которые обеспечивают более осмысленное встраивание (GloVe [4], ELMo [5], BERT [6] и GPT [7]), использующих сложное концептуальное обучение с архитектурами нейронных сетей. Последние модели (BERT и GPT) основаны на архитектуре «Transformer» и называются языковыми моделями. Они используют весь текст в качестве контекста, множественные пути для передачи различных значений и нейронные сети с триллионами настраиваемых параметров. В связи с этим, эффективные модели, как правило, являются более масштабными моделями, которым требуется больше данных.
Очевидно, что существует значительная неопределенность относительно долгосрочных возможностей технологий ИИ. Так, текущие LLM могут не справляться с элементарными логическими рассуждениями и испытывать трудности с контрфактическими рассуждениями. Например, когда им предлагают решить логическую задачу, требующую рассуждений о знаниях других объектах/субъектах и о контрфактических рассуждениях, LLM демонстрируют характерную закономерность неудач. Однако LLM безупречно справляются, когда им предлагают оригинальную формулировку задачи, которую они, вероятно, видели во время обучения. При этом LLM буквально спотыкаются, когда та же самая задача предлагается с минимальными изменениями деталей, таких как имена и даты, что указывает на отсутствие истинного понимания базовой логики утверждений. В итоге, LLM не знают, чего они не знают. LLM также страдают от проблемы галлюцинаций: они могут представить фактически неверный ответ, как если бы он был правильным. Между тем, галлюцинации являются особенностью, а не ошибкой в этих моделях. LLM галлюцинируют, потому что их обучают предсказывать статистически правдоподобное слово на основе специфических входных данных. Следовательно, они не могут отличить то, что лингвистически вероятно, от того, что фактически верно.
Таким образом, оптимисты признают существующие ограничения, но подчеркивают потенциал LLM в контексте того, что они могут превзойти человеческие возможности в определенных областях. В частности, они утверждают, что такие термины, как «разум», «знание» и «обучение», справедливо применяются к таким моделям [3].
Скептики указывают на ограничения LLM в рассуждениях и планировании. Они утверждают, что основное ограничение LLM вытекает из их исключительной зависимости от языка как средства знания [2]. Поскольку LLM ограничены взаимодействием с миром, исключительно посредством языка, им не хватает неявного нелингвистического, общего понимания, которое может быть приобретено только через активное взаимодействие с реальным миром.
Сможет ли ИИ в конечном итоге выполнять задачи, требующие глубокого логического мышления, имеет значение для его долгосрочного экономического воздействия. Оценка того, на какие задачи повлияет (положительно или отрицательно) ИИ, зависит от конкретных когнитивных способностей, требуемых для этих задач [6]. Положительным аспектом в данном процессе выступает интеграция «многоцелевого внимания» и «позиционного кодирования», значительно повышающая производительность языковых моделей. Модели на основе «Transformer» демонстрируют адекватную интерпретацию контекста и управление сложными взаимосвязями в тексте. Результатом является точность и беглость в различных задачах обработки естественного языка. А возможности параллельных вычислений «Transformer», облегчаемые достижениями в технологии графических процессоров позволяют быстро обрабатывать огромные наборы данных и сложную лингвистическую структуру.
Риски и этические аспекты нерегулируемой разработки ИИ. Одно из основных этических соображений при нерегулируемой разработке ИИ касается процессов принятия решений. Алгоритмы ИИ могут демонстрировать предвзятость, дискриминацию или отсутствие прозрачности, если ими не управлять должным образом. Из этого следует, что непреднамеренное усиление существующих общественных предубеждений может подорвать доверие к системам ИИ. В связи с этим, рассмотрим основные риски и этические аспекты нерегулируемой разработки ИИ.
Последствия ИИ для конфиденциальности.
Неконтролируемое развитие технологий ИИ несет значительные риски для личной конфиденциальности. «Поскольку системы ИИ аккумулируют и анализируют огромные объемы персональных данных, существует вероятность несанкционированного доступа, неправомерного использования или утечки данных» [12]. Без надежных правил люди могут столкнуться с повышенным риском нарушения конфиденциальности, что может вызвать опасения по поводу слежки и эксплуатации данных.
Уязвимости безопасности.
Нерегулируемая разработка ИИ может привести к уязвимостям безопасности, которые могут использовать злоумышленники. Уязвимости безопасности могут генерировать враждебные атаки на модели МО для получения несанкционированного доступа и манипулирования системами ИИ. «Отсутствие строгих правил и стандартов в сфере ИИ могут подвергнуть критическую инфраструктуру и конфиденциальную информацию угрозам кибербезопасности» [14].
Отсутствие ответственности.
Без четких правил распределение ответственности за последствия действий ИИ становится сложной задачей. Одним из главных вызовов, является потеря контроля со стороны человека. «По мере того, как машины становятся все более автономными, существует риск того, что они могут принимать решения или совершать действия, не соответствующие человеческим ценностям и этике» [1]. Такое отсутствие контроля вызывает опасения относительно потенциальной возможности систем ИИ причинять вред, как преднамеренно, так и непреднамеренно.
Сокращение рабочих мест и социально-экономические последствия.
Широкое внедрение ИИ без адекватного регулирования вызывает опасения по поводу перемещения рабочих мест и его более широких социально-экономических последствий. «Автоматизация, вызванная развитием ИИ, может привести к потере рабочих мест в определенных секторах» [8]. Перемещение рабочих мест потенциально усугубляет существующее экономическое неравенство. И это требует принятия упреждающих мер для решения проблемы перемещения рабочей силы.
Этическое использование в автономных системах.
В контексте автономных систем, таких как беспилотные автомобили и дроны, развитие ИИ создаёт этические дилеммы. Решения, принимаемые ИИ в критических ситуациях, таких как аварии или чрезвычайные ситуации, требуют тщательного рассмотрения моральных принципов и общественных ценностей. «Отсутствие четких руководящих принципов может привести к неоптимальному этическому выбору в автономных процессах принятия решений» [21].
Отсутствие прозрачности и объяснимости.
Прозрачность и объяснимость являются критически важными аспектами ответственного ИИ. Нерегулируемая разработка ИИ может привести к непрозрачным алгоритмам, что затрудняет понимание обоснования решений, принимаемых на основе ИИ. Отсутствие прозрачности технологий ИИ может препятствовать общественному доверию к системам ИИ. Кроме того, это ограничивает возможность решать проблемы, связанные со справедливостью и предвзятостью.
Очевидно, что нерегулируемая разработка ИИ влечет за собой множество рисков и этических соображений, которые варьируются от предвзятого принятия решений до нарушения конфиденциальности и уязвимостей безопасности. Для того, чтобы оптимизировать риски, связанные с неконтролируемым ИИ, важно установить правила и руководящие принципы для разработки и развертывания подобных систем. Должны быть внедрены механизмы надзора и подотчетности, в целях гарантии того, что системы ИИ работают в приемлемых границах и соответствуют человеческим ценностям. В целом, крайне важно обеспечить, чтобы ИИ оставался под контролем человека.
Глобальные перспективы регулирования ИИ. Политика регулирования ИИ как на национальном, так и на глобальном уровнях все еще находится на стадии становления, и восприятие его текущей эффективности неоднозначно.
В США регулирование ИИ характеризуется секторальным подходом. Федеральные агентства, такие как Федеральная торговая комиссия (FTC) и Национальный институт стандартов и технологий (NIST), фокусируются на конкретных отраслях. Общего федерального регулирования ИИ не существует. Тем не менее, обсуждения как на федеральном, так и на государственном уровне продолжаются.
Азиатские страны, в частности Китай и Южная Корея, приняли политику, ориентированную на инновации, чтобы позиционировать себя как лидеров в разработке ИИ. Например, Китай выпустил руководящие принципы по содействию ответственной разработке ИИ и созданию надежной его экосистемы [22]. И Китай, и Южная Корея отдают приоритет конкурентоспособности, признавая при этом необходимость этических соображений.
В развивающихся странах и странах с формирующейся рыночной экономикой акцент на регулировании ИИ различается. Некоторые страны активно работают над руководящими принципами, другие всё ещё находятся на ранних стадиях понимания последствий ИИ. Их проблемы содержатся в том, чтобы сбалансировать преимущества внедрения ИИ с устранением потенциальных рисков, учитывая национальную специфику и адаптацию нормативных рамок к конкретным потребностям.
Учитывая глобальный характер ИИ, международное сотрудничество приобретает все большую значимость. Такие организации, как Организация экономического сотрудничества и развития (ОЭСР), Всемирная организация здравоохранения (ВОЗ), Большая двадцатка (G20 – The Group of Twenty) и многие другие, содействуют обсуждению международных принципов и стандартов ИИ [10; 11]. Цель состоит в том, чтобы создать гармонизированный подход к управлению ИИ, который выходит за рамки национальных границ.
Несмотря на усилия по международному сотрудничеству, гармонизация глобального регулирования ИИ сталкивается с трудностями. Различные культурные, правовые и этические точки зрения приводят к разногласиям в подходах к регулированию. Преодоление этих разрывов требует постоянного диалога, общих принципов и стремления к поиску взаимосвязанных интересов.
Согласно «Отчету о глобальном регулировании ИИ» [13], эффективность текущей политики в области ИИ в региональном разрезе находится на низком уровне (табл. 1).
Таблица 1. Эффективность текущей политики в области ИИ в решении вопросов разработки, внедрения и использования ИИ (по состоянию на I-е полугодие 2024 г.)
|
Критерий эффективности
|
Позиция
|
Отрасль
|
Регион
| |||||
|
Руководителей
|
Юристов
|
Финансовая
|
Торговля
|
Технологии
|
*
|
**
|
***
| |
|
Очень
эффективно
|
32%
|
26%
|
36%
|
26%
|
37%
|
31%
|
31%
|
28%
|
|
Умеренно
эффективно
|
32%
|
27%
|
25%
|
31%
|
39%
|
33%
|
33%
|
27%
|
|
Слабо
эффективно
|
23%
|
23%
|
21%
|
25%
|
19%
|
25%
|
21%
|
24%
|
|
Неэффективно
|
10%
|
22%
|
17%
|
13%
|
5%
|
9%
|
12%
|
18%
|
**Европа (в том числе Россия), Ближний Восток и Африка
***Северная Америка
Источник: [13].
Как видно из таблицы 1, эффективность текущей политики в области ИИ по исследуемым позициям, отраслям и регионам определена по следующим критериям (значения эффективности не превышают уровень 39%, при этом максимальный уровень значения неэффективности составляет 22%):
– очень эффективно – значения находятся в диапазоне 26-37%%;
– умеренно эффективно – значения находятся в диапазоне 25-39%%;
– слабо эффективно – значения находятся в диапазоне 19-25%%;
– неэффективно – значения находятся в диапазоне 5-22%%.
Следует отметить, что эффективность политики в области ИИ в конкретной юрисдикции будет зависеть от объёма инвестиций в ИИ и масштаба разработок программного обеспечения ИИ. На примере США, Китая и России проанализируем значения данных показателей за период 2021-2023 гг. (рис. 1; 2).
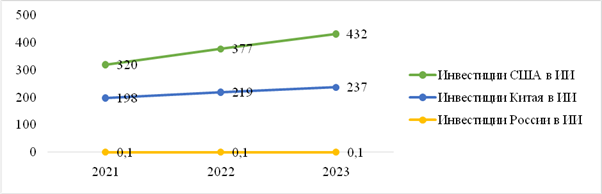
Рисунок 1. Инвестиции США, Китая, России в ИИ, млн. долл.
Источник: [22-24].
Как показано на графике (рис. 1), лидирующую позицию занимает США. За анализируемый период 2021-2023 гг. увеличение значения произошло на 112 млн. долл. с положительной тенденцией роста.
У Китая уровень значений по данному показателю меньше, чем у США, но также, за аналогичный период отмечен рост (+39 млн. долл.).
Инвестиции России в ИИ продемонстрировали стабильно низкий уровень значений (0,1 млн. долл.).
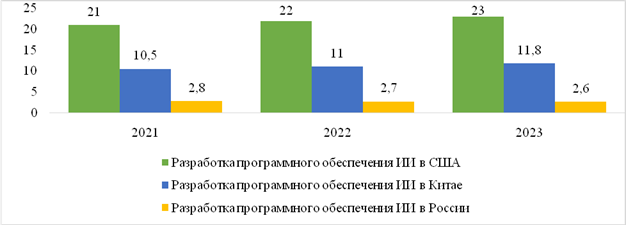
Рисунок 2. Разработка программного обеспечения ИИ в США, Китае, России,
% от совокупности всех проектов
Источник: [22-24].
Как видно из рисунка 2, по показателю «разработка программного обеспечения ИИ» США продемонстрировали более высокий уровень значений, чем у Китая и России, увеличение составило 2% от совокупности, реализуемых проектов, у Китая (+1,3%). У России за аналогичный период отмечена отрицательная тенденция (-0,2%).
Проведя аналитический обзор разработок в области ИИ, и рассмотрев основные риски и этические аспекты нерегулируемой разработки ИИ, автор предлагает алгоритм действий по регулированию ИИ на глобальном уровне, с учётом национальных потребностей (табл. 2).
Таблица 2. Алгоритм действий по регулированию ИИ
|
Действия
|
Результат
|
|
Установить
четкие руководящие принципы и правила ИИ
|
Ответственная
разработка ИИ
|
|
Обеспечить
участие всех заинтересованных сторон в принятии решений по разработке и
внедрению ИИ
|
Человеческий
надзор и контроль
|
|
Инвестировать
в исследования и разработку надежных алгоритмов и архитектур ИИ
|
Безопасный
и надежный ИИ
|
|
Работать
над установлением глобальных стандартов и нормативных рамок со всеми
заинтересованными сторонами
|
Сотрудничество
и кооперация
|
Реализация представленного алгоритма действий по регулированию ИИ позволит:
– реализовать этические вопросы;
– обеспечить защиту прав человека (конфиденциальность, безопасность);
– способствовать подотчетности и ответственности разработок систем ИИ;
– обеспечить правовые рамки ИИ (безопасность и надежность, стандарты и сертификация);
– предотвратить вред, причиняемый системами ИИ;
– обеспечить защиту прав потребителей;
– регламентировать процесс управления данными (использование данных, предотвращение эксплуатации данными);
– содействовать международному сотрудничеству (разработка глобальных стандартов ИИ);
– продвигать инновации и доверие в области ИИ;
– решить социально-экономические проблемы;
– обеспечить инклюзивность;
– содействовать адаптации к развивающимся технологиям.
Заключительные выводы
Быстрое развитие технологий ИИ создает как возможности, так и проблемы. Чтобы эффективно использовать потенциал ИИ, минимизируя при этом риски, необходимо обеспечить его ответственную разработку, имплементацию и адекватное регулирование. Для этого необходимо учитывать этические аспекты, содействовать образованию и повышению осведомленности, внедрять эффективные меры политики в области ИИ. Также следует минимизировать различия в подходах, создающие проблемы в разработке международных стандартов:
– регулирование на основе оценки риска: страны по-разному подходят к регулированию ИИ на основе риска. Некоторые фокусируются на высокорисковых приложениях ИИ, внедряя строгие правила для таких секторов, как здравоохранение и финансы. В то же время другие придерживаются более широкого подхода, охватывающего широкий спектр приложений;
– политика, ориентированная на инновации: существуют различия в том, как страны обеспечивают баланс между потребностью в инновациях и мерами регулирования. К примеру, Китай принимает политику, ориентированную на инновации, другие отдают приоритет нормативным рамкам для устранения потенциальных рисков;
– отраслевое и всеобъемлющее регулирование: отдельные страны, например, США, применяют секторальный подход. Их правила адаптированы к конкретным отраслям. Напротив, другие, например, Европейский союз, стремится к всеобъемлющему регулированию, охватывающему различные сектора и приложения ИИ;
– акцент на защите данных: Европейские страны, движимые GDPR [8], делают сильный акцент на защите данных. Однако другие регионы могут больше концентрироваться на более широких этических соображениях без конкретных правил защиты данных;
– участие правительства: степень участия правительства в регулировании ИИ различается по странам. Например, в Китае, действуют государственные инициативы, в то время как в других, к примеру, в США больше полагаются на саморегулирование отрасли с ограниченным вмешательством правительства;
– культурные и социальные нюансы: культурные и общественные факторы влияют на подходы к управлению ИИ. Разные регионы имеют уникальные взгляды на конфиденциальность, индивидуальные права и роль технологий в обществе. Это приводит к различным приоритетам регулирования.
Таким образом, в целях адекватного глобального управления ИИ необходимо фундаментальное понимание общих тем и национальных различий. Поскольку страны продолжают формировать свои нормативно-правовые базы, международное сотрудничество будет играть решающую роль в решении общих проблем и содействии ответственному развитию ИИ.
[1] Word2vec – общее название для совокупности моделей на основе искусственных нейронных сетей, предназначенных для получения векторных представлений слов на естественном языке. Используется для анализа семантики естественных языков, основанный на дистрибутивной семантике, машинном обучении и векторном представлении слов.
[2] Common Crawl поддерживает бесплатный открытый репозиторий данных веб-сканирования, который может использовать любой желающий.
[3] Архитектура transformer стала прорывом в обработке естественного языка (NLP), заложив основу для разработки продвинутых больших языковых моделей (LLM), таких как BERT (Bidirectional Encoder Representations from Transformers) и GPT (Generative Pre-trained Transformer).
[4] GloVe (от Global Vectors) – модель для распределённого представления слов.
[5] ELMo (Efficient Language Model) – это метод ИИ, используемый для понимания текста.
[6] BERT – это двунаправленная мультиязычная модель с transformer-архитектурой, предназначенная для решения конкретных NLP-задач.
[7] GPT (Generative pre-trained transformer) – это тип нейронных языковых моделей, впервые представленных компанией OpenAI.
[8] GDPR (General Data Protection Regulation) – это общий регламент о защите персональных данных всех физических лиц, которые находятся на территории Европейского союза.
Источники:
2. Алферьев Д. А. Технологии ИИ как метод прогнозной аналитики // Искусственные общества. – 2018. – № 4. – c. 1.
3. Барашкова А. Л., Воробьев И. В. Цифровая трансформация в науке: что ждут от технологий ИИ российские ученые? // Науковедческие исследования. – 2024. – № 1. – c. 33-45. – doi: 10.31249/scis/2024.01.02.
4. Ефремов В.С., Никитинс И. Совершенствование сценарного планирования инструментами машинного обучения // Информатизация в цифровой экономике. – 2024. – № 3. – doi: 10.18334/ide.5.3.121501.
5. Исмаилов К.М. Финансовые инновации в банковском секторе // Экономическая безопасность. – 2024. – № 6. – c. 1411-1428. – doi: 10.18334/ecsec.7.6.121198.
6. Караваева И.В., Лев М.Ю. Приоритеты государственного регулирования экономической безопасности России в условиях новых глобальных вызовов // Экономическая безопасность. – 2023. – № 2. – c. 453-466. – doi: 10.18334/ecsec.6.2.117953.
7. Караваева И.В., Лев М.Ю. Экономическая безопасность: технологический суверенитет в системе экономической безопасности в современной России // Экономическая безопасность. – 2023. – № 3. – c. 905-924. – doi: 10.18334/ecsec.6.3.118475.
8. Кохтюлина И. Н. Типология глобальных рисков и угроз технологий ИИ. / Международная безопасность в эпоху искусственного интеллекта. В двух томах. - Москва: ООО Издательство «Аспект Пресс», 2024. – 115-131 c.
9. Лев М.Ю., Болонин А.И., Туруев И.Б., Лещенко Ю.Г. Концепция искусственного интеллекта в деятельности центральных банков: институциональные возможности // Экономическая безопасность. – 2024. – № 4. – c. 781-808. – doi: 10.18334/ecsec.7.4.120831.
10. Лев М.Ю., Лещенко Ю.Г., Медведева М.Б. Регулирование искусственного интеллекта международными организациями как фактор обеспечения технологической безопасности в национальных юрисдикциях // Экономическая безопасность. – 2024. – № 8. – c. 1999-2026. – doi: 10.18334/ecsec.7.8.121608.
11. Лещенко Ю.Г. Институциональные ориентиры группы 20 (G-20) в аспекте российской экономики и интересах российского предпринимательства // Российское предпринимательство. – 2017. – № 17. – c. 2417-2450. – doi: 10.18334/rp.18.17.38255.
12. Маджекова М., Агаджанова А. Искусственный интеллект и экономика: возможности и вызовы // Eo ipso. – 2023. – № 10. – c. 57-59.
13. Отчет о глобальном регулировании ИИ/Global AI Regulation Report, BRG. [Электронный ресурс]. URL: https://ai.gov.ru/knowledgebase/investitsionnaya-aktivnost/2024_otchet_o_globalynom (дата обращения: 09.09.2024).
14. Скоробогатова И.И., Воронин А.А., Злобин С.М. Нормативно-правовые аспекты регулирования применения искусственного интеллекта // Искусственный интеллект. – 2023. – № 3(3). – c. 43-49.
15. Чэнь Ц. Основные технологии функционирования искусственного интеллекта // Инновации и инвестиции. – 2024. – № 3. – c. 286-288.
16. Agrawal A. J. Gans and A Goldfarb(2019): «Exploring the impact of artificial intelligence: prediction versus judgment» // Information Economics and Policy. – 2019. – p. 1-6.
17. Belkin, M, D Hsu, S Ma and S Mandal (2019): «Reconciling modern machine learning practice and the classical bias-variance trade-off», Proceedings of the National Academy of Sciences, vol 116, no 32, pp 15849–54
18. Felten, E, M Raj and R Seamans (2021): «Occupational, industry and geographic exposure to artificial intelligence: a novel data set and its potential uses», Strategic Management Journal, vol 42, no 12, pp 2195–217
19. Hitaj, D, G Pagnotta, B Hitaj, L Mancini and F Perez-Cruz (2022): «MaleficNet: hiding malware into deep neural networks using spread-spectrum channel coding», in V Atluri, R Di Pietro, C Jensen and W Meng (eds), Computer security – ESORICS 2022, Springer Cham, 23 September
20. Murphy K. Machine learning: a probabilistic perspective, MIT Press, 24 August. [Электронный ресурс]. URL: https://www.cs.ubc.ca/~murphyk/MLbook/pml-toc-1may12.pdf (дата обращения: 09.09.2024).
21. Noy, S and W Zhang (2023): «Experimental evidence on the productivity effects of generative artificial intelligence», Science, vol 381, no 6654, pp 187–92
22. OECD.AI. AI in China. [Электронный ресурс]. URL: https://oecd.ai/en/dashboards/countries/China (дата обращения: 09.09.2024).
23. OECD.AI. AI in the United States. [Электронный ресурс]. URL: https://oecd.ai/en/dashboards/countries/UnitedStates (дата обращения: 09.09.2024).
24. OECD.AI. National AI policies & strategies. [Электронный ресурс]. URL: https://oecd.ai/en/dashboards/overview (дата обращения: 09.09.2024).
Страница обновлена: 16.07.2026 в 11:20:08
Download PDF | Downloads: 85
Artificial intelligence economics: trends, compliance and global impact
Volovik A.M.Journal paper
Economic security
Volume 7, Number 9 (September 2024)
Abstract:
The article examines the status and characteristics of AI regulation at the global and national levels. An analytical review of AI R&D is conducted. The risks and ethical aspects of unregulated AI development are considered. Global prospects for AI regulation are defined.
According to the Report on Global AI Regulation, the effectiveness of the current AI policy in the regional context is analyzed. The conclusion about the low level of the current AI policy in the regional context is drawn.
A comparative analysis of the indicators of investment in AI and AI software development in the USA, China and Russia is conducted. This analysis revealed a high level of values in the USA and a very low level in Russia.
Based on the results of the study, an algorithm of actions for regulating AI at the global level, taking into account national needs, is proposed.
It is concluded that an adequate global regulation of AI requires a fundamental understanding of common issues and national differences.
Keywords: artificial intelligence, technology, risk, global impact, economics, artificial intelligence regulation policy, compliance, meeting requirements
JEL-classification: O31, O32, O33
References:
Ablameyko M. S. (2023). Eticheskie i pravovye aspekty primeneniya tekhnologiy iskusstvennogo intellekta s uchetom mezhdunarodnogo opyta [Ethical and legal aspects of application of artificial intelligence technologies taking into account international experience]. Pravo.by. (5(85)). 66-74. (in Russian).
Agrawal A. J. (2019). Gans and A Goldfarb(2019): «Exploring the impact of artificial intelligence: prediction versus judgment» «Exploring the impact of artificial intelligence: prediction versus judgment», Information Economics and Policy. 47 1-6.
Alferev D. A. (2018). Tekhnologii II kak metod prognoznoy analitiki [Ai technologies as a method of predictive analytics]. Iskusstvennye obschestva. (4). 1. (in Russian).
Barashkova A. L., Vorobev I. V. (2024). Tsifrovaya transformatsiya v nauke: chto zhdut ot tekhnologiy II rossiyskie uchenye? [Digital transformation creation in science: what do russian scientists expect from technology?]. Naukovedcheskie issledovaniya. (1). 33-45. (in Russian). doi: 10.31249/scis/2024.01.02.
Chen Ts. (2024). Osnovnye tekhnologii funktsionirovaniya iskusstvennogo intellekta [Basic technologies for the functioning of artificial intelligence]. Innovation and Investment. (3). 286-288. (in Russian).
Efremov V.S., Nikitins I. (2024). Sovershenstvovanie stsenarnogo planirovaniya instrumentami mashinnogo obucheniya [Improving scenario planning with machine learning tools]. Informatization in the Digital Economy. 5 (3). (in Russian). doi: 10.18334/ide.5.3.121501.
Ismailov K.M. (2024). Finansovye innovatsii v bankovskom sektore [Financial innovation in banking]. Economic security. 7 (6). 1411-1428. (in Russian). doi: 10.18334/ecsec.7.6.121198.
Karavaeva I.V., Lev M.Yu. (2023). Ekonomicheskaya bezopasnost: tekhnologicheskiy suverenitet v sisteme ekonomicheskoy bezopasnosti v sovremennoy Rossii [Economic security: technological sovereignty in the economic security system in modern Russia]. Economic security. 6 (3). 905-924. (in Russian). doi: 10.18334/ecsec.6.3.118475.
Karavaeva I.V., Lev M.Yu. (2023). Prioritety gosudarstvennogo regulirovaniya ekonomicheskoy bezopasnosti Rossii v usloviyakh novyh globalnyh vyzovov [Priorities of state regulation of Russia's economic security amidst new global challenges]. Economic security. 6 (2). 453-466. (in Russian). doi: 10.18334/ecsec.6.2.117953.
Kokhtyulina I. N. (2024). Tipologiya globalnyh riskov i ugroz tekhnologiy II [Typology of global risks and threats of AI technologies] (in Russian).
Leschenko Yu.G. (2017). Institutsionalnye orientiry gruppy 20 (G-20) v aspekte rossiyskoy ekonomiki i interesakh rossiyskogo predprinimatelstva [Institutional guidelines for the Group 20 (G-20) in the aspect of the Russian economy and the interests of Russian entrepreneurship]. Russian Journal of Entrepreneurship. 18 (17). 2417-2450. (in Russian). doi: 10.18334/rp.18.17.38255.
Lev M.Yu., Bolonin A.I., Turuev I.B., Leschenko Yu.G. (2024). Kontseptsiya iskusstvennogo intellekta v deyatelnosti tsentralnyh bankov: institutsionalnye vozmozhnosti [The concept of artificial intelligence in the activities of central banks: institutional opportunities]. Economic security. 7 (4). 781-808. (in Russian). doi: 10.18334/ecsec.7.4.120831.
Lev M.Yu., Leschenko Yu.G., Medvedeva M.B. (2024). Regulirovanie iskusstvennogo intellekta mezhdunarodnymi organizatsiyami kak faktor obespecheniya tekhnologicheskoy bezopasnosti v natsionalnyh yurisdiktsiyakh [Regulation of artificial intelligence by international organizations as a factor in ensuring technological security in national jurisdictions]. Economic security. 7 (8). 1999-2026. (in Russian). doi: 10.18334/ecsec.7.8.121608.
Madzhekova M., Agadzhanova A. (2023). Iskusstvennyy intellekt i ekonomika: vozmozhnosti i vyzovy [Artificial intelligence and economy: opportunities and challenges]. Eo ipso. (10). 57-59. (in Russian).
Murphy K. Machine learning: a probabilistic perspective, MIT Press, 24 August. Retrieved September 09, 2024, from https://www.cs.ubc.ca/~murphyk/MLbook/pml-toc-1may12.pdf
OECD.AI. AI in China. Retrieved September 09, 2024, from https://oecd.ai/en/dashboards/countries/China
OECD.AI. AI in the United States. Retrieved September 09, 2024, from https://oecd.ai/en/dashboards/countries/UnitedStates
OECD.AI. National AI policies & strategies. Retrieved September 09, 2024, from https://oecd.ai/en/dashboards/overview
Skorobogatova I.I., Voronin A.A., Zlobin S.M. (2023). Normativno-pravovye aspekty regulirovaniya primeneniya iskusstvennogo intellekta [Regulatory and legal aspects of regulation applications of artificial intelligence]. Iskusstvennyy intellekt. (3(3)). 43-49. (in Russian).