Визуализация больших данных в экономических науках в условиях информационного общества
Платонов В.В.1![]()
1 Санкт-Петербургский государственный экономический университет, Россия, Санкт-Петербург
Скачать PDF | Загрузок: 78 | Цитирований: 19
Статья в журнале
Вопросы инновационной экономики (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 10, Номер 4 (Октябрь-декабрь 2020)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=44491689
Цитирований: 19
Аннотация:
Статья посвящена рассмотрению визуализации как метода постижения и коммуникации экономической информации, извлекаемой из больших данных в перспективе поиска новых направлений развития экономических наук и наук о бизнесе в условиях информационного общества, когда на первый план выдвинулась наука информатика. Уточнено понятие «визуализация информации» применительно к наукам о бизнесе. Рассмотрено место визуализации в коммуникациях между людьми, а также человеком и машиной. Особое внимание уделено абстракции путем визуализации информации, извлеченной из больших данных, для исследования сложных хозяйственных систем, а также презентации выводов для лиц, принимающих решения. Обсуждается проблема компенсации потери данных, при использовании программных средств извлечения информации и роль дисциплинарного знания экономических наук в ее решении. Выводы, содержащиеся в статье, проиллюстрированы на примере графов, как наиболее эффективной формы визуальной репрезентации сложных экономических систем. В том числе, рассмотрен процесс постижения экономической реальности путем перехода от трехмерного графа, изображающему реальный объект, к двумерному графу, отражающему идеальный конструкт.
Ключевые слова: большие данные, информационное общество, анализ информации, сложные хозяйственные системы
Финансирование:
Исследование выполнено при поддержке гранта РФФИ, проект 19-010-00257.
JEL-классификация: O31, O32, O33
Введение
К 2020 году, согласно тенденции, существовавшей до пандемии COVID-19, объем накопленных данных должен был возрасти до 44 триллионов гигабайт, что в десять раз больше по сравнению с 2015 годом. Каждые два года человечество накапливает объем данных, равный накопленному за всю предыдущую историю человечества [22] (Marr, 2015). Есть все основания предполагать, что переход в начале этого года в онлайн только усилил указанную тенденцию. В результате лавинообразного роста объемов и разнообразия данных формируется новый экономический ресурс – большие данные [3] (Karlik, Platonov, Tikhonova, Yakovleva, 2019). В обыденном сознании отличительной особенностью больших данных представляется их объем, но на самом деле важнейшей их характеристикой для постижения экономической реальности и принятия управленческих решений является их разнообразие, что, в частности, подтверждается опросами практиков [3, 9, 28] (Sejahtera, Wang, Indulska, Sadiq, 2018).
По разнообразию большие данные варьируются, например, от стоимостных по каждому продукту, реализованному конкретному клиенту, до данных, снимаемых с датчиков оборудования, и видеоданных, загруженных в YouTube, а затем сохраненных в «облаке» системой обслуживания клиентов той или иной компании. Потенциально из подобных данных можно получить информацию о важнейших аспектах функционирования сложных экономических систем, о чем раньше нельзя было даже мечтать. Но для этого надо выработать подходы для анализа больших данных и их использования при принятии управленческих решений. Эту сложнейшую задачу еще только предстоит решить. Большие данные могут быть структурированными в реляционных базах данных, но 95% их объема составляют неструктурированные данные. К счастью, развитие технологий искусственного интеллекта позволяет извлекать из больших данных без участия человека все больше разносторонней информации об экономических системах повышенной сложности.
В экономике и менеджменте всегда приходилось иметь дело с системами повышенной сложности, но степень сложности значительно возрастает в информационном обществе. Возникает так называемая проблема комплексности, сложности (complexity challenge), делающая малопригодными традиционные подходы к экономическому анализу. Может показаться, что большие данные создают еще одну новую проблему для экономического анализа. На самом деле они являются тем резервом, тем новым нематериальным ресурсом, использование которого способно решить проблему сложности, но для этого надо решить указанную проблему их использования в экономическом анализе. Вопрос только в наличии методов извлечения информации, ее использовании человеком в постижении комплексной реальности и презентации информации управленцам. Визуализация информации – один из важных аспектов решения этой проблемы. Целью данной статьи является постановка и конкретизация проблемы изучения сложных хозяйственных объектов для принятия управленческих решений на основе абстракции путем визуализации, а также обсуждение подходов к ее решению.
Визуализация в решении проблемы сложности в экономическом анализе
В условиях информационного общества растет значение науки информатики. Возможности и область приложения информатики возросли настолько, что впору ставить вопрос о том, что остается после этого расширения от предмета ряда других наук, в том числе экономики и менеджмента. Какие наиболее перспективные области, где следует искать место наукам о бизнесе, и закреплять их специализацию в условиях информационного общества? Ответ очевиден – там, где требуется глубокое дисциплинарное знание закономерностей функционирования комплексных хозяйственных объектов (сложных систем), владение методологией экономических исследований, умение и навыки использовать результаты для обоснования управленческих решений.
Достижение искусственным интеллектом мыслительных возможностей человека – долгосрочная перспектива: искусственный интеллект, пока, не может пройти тест Тьюринга, придуманный 70 лет назад [31] (Turing, 1950), чтобы определить, когда интеллект машины (компьютера) сравняется с человеческим интеллектом. Поэтому перспективная область приложения дисциплинарного знания экономических наук, в условиях широкого применения искусственного интеллекта, лежит между использованием информации, извлекаемой машиной, и конечной информацией, используемой при принятии управленческого решения. Экономические науки только выиграют от достижений информационно-коммуникационных технологий (ИКТ), которые будут направлены на достижение нового качества экономического анализа. Например, ранее не было информационной базы для всестороннего анализа нематериальных факторов эффективности; информационной базы, чтобы учесть разнородные элементы, запутанные взаимосвязи и эмерджентные свойства сложных (комплексных) хозяйственных систем.
Существует два фундаментальных подхода справиться с решением проблемы комплексности, задачей изучить и контролировать сложную хозяйственную систему. Первый подход – поглощение сложности, второй – сокращение сложности [11] (Boisot, Child, 1999). Поглощение сложности достигается путем все более полного сбора и обработки данных, где выдающуюся роль играют компьютерные технологии. В экономическом анализе эту задачу давно решали разработкой и внедрением количественных методов, а большие данные открывают большие возможности, использовать которые способны машинное обучение, нейронные сети и другие технологии искусственного интеллекта. Однако поглощение сложности имеет свои объективные границы [10] (Boisot, 1998). Выйти за пределы этих границ возможно с применением второго подхода – сокращения сложности. Если поглощение сложности наиболее ассоциируется с компьютерными технологиями обработки данных, то сокращение сложности в наибольшей степени ассоциируется с абстрактным мышлением. Правда с развитием искусственного интеллекта все в большей степени абстракция начинает осуществляться путем редукции с применением программных решений, в том числе позволяющих визуализировать данные и информацию. Сокращение сложности путем визуализации и создания зрительных образов осуществляется графическим представлением информации визуальными элементами, такими как графы, диаграммы, карты. Они позволяют упрощать сложные объекты и явления для их постижения (понимания) исследователями или аналитиками, а также передавать (презентовать) информацию [21, 29] (Aparicio, Costa, 2014; Ansari, Nasreen, 2020).
При поглощении сложности все новое знание содержится в данных и должно быть оттуда извлечено с использованием компьютерных технологий, например, машинного обучения. Это область информатики, а не специальных дисциплин, предметом которых являются объекты анализа. В этой области специальные дисциплины, включая экономические науки, могут играть роль только в рамках междисциплинарного взаимодействия с информатикой. Такая роль важна, но является дополнительной, вторичной. Во втором случае упрощение, выделение сути комплексной реальности достигается на основе знаний, накопленных человеком, и способностей, развитых людьми в ходе обучения и опыта практической деятельности. Это предмет приложения специальных дисциплин и, когда касается хозяйственной реальности, таких дисциплин, как экономика и менеджмент. Машины здесь также играют важнейшую роль, но они бесполезны без человека из-за потери значительной доли данных в ходе редукции программными средствами [26] (Rumpf, Ray, 2016).
В абстрактном мышлении наряду с символами человек оперирует образами. Представление информации в зрительных образах имеет особое значение в экономических исследованиях, так как графики и диаграмма соединяют воедино аналитическое, последовательное, логическое и целостное, образное мышление. С начала своего возникновения в XVIII веке абстракция путем визуализации базируется на двух группах методических решений. Первое: использование графических примитивов (точки, прямые и так далее) для представления объектов и отношений между ними. Второе: использование пространственных переменных (например, позиция или форма) [18] (Manovich, 2010).
Визуализация как метод экономических наук состоит из двух частей. Первая часть: постижение сложной хозяйственной реальности с использованием зрительных образов. Вторая часть: донесение выводов до целевой аудитории. Иными словами, речь идет о научном исследовании и презентации его результатов. В первом случае визуальные образы представляют проявление самого мышления (визуальное мышление [1] (Arnkheym, 1974)), во втором – они иллюстрируют выводы автора. В контексте искусственного интеллекта и извлечения информации из больших данных, первая часть визуализации является видом коммуникации между человеком и машиной (искусственным интеллектом). Вторая часть относится к коммуникации между людьми в ходе движения информации от экспертов к лицам, принимающим управленческие решения. Вторая часть не менее важна. В информационном обществе управленцы и эксперты обычно имеют дело со сложными хозяйственными системами, а значит, принимают решения в условиях когнитивной перегрузки, так как несмотря на возрастание объема и методов обработки данных, основные когнитивные возможности человека не растут теми же самыми темпами [15] (Kalakoski, Henelius, Oikarinen, Ukkonen, Puolamäki, 2019), а возможно, даже снижаются из-за исчезновения необходимости современным людям решать сложные проблемы материальной жизни подобно предыдущим поколениям. Например, наши возможности в принятии решений ограничены способностью удерживать и обрабатывать информацию в краткосрочной памяти [7, 15] (Baddeley, Hitch, 1974).
Содержание и направления визуализации экономической информации
Вопрос уточнения содержания термина «визуализация» для изучения хозяйственных объектов необходим, чтобы понимать, для чего используется визуализация в экономических исследованиях и что является ее объектом. В ряде случаев под визуализацией понимается постижение реальности в образах или передача информации в табличной, текстовой формах и даже в математических формулах. Это не вполне точно – визуализация используется для того, чтобы извлекать (постигать) и передавать информацию об экономической реальности именно в зрительных образах. Объектом визуализации при коммуникациях между людьми является только информация, а не данные, хотя очень часто используется словосочетание «визуализация данных» [13, 21] (Beer, Burrows, 2013; Aparicio, Costa, 2014).
Словосочетание «визуализация данных» корректно для технических наук, когда человек работает с первичными данными в рамках человеко-машинного взаимодействия, но принципиально ошибочно, когда речь идет о межличностных коммуникациях. Источник этой ошибки кроется в непонимании принципиально различного места в процессе постижения реальности, между понятиями «данные» и «информация». Информация извлекается из данных – сигналов и знаков и включает только полезные данные, которые отфильтрованы человеком на основе знаний, то есть, ранее накопленной информации [6] (Ackoff, 1989). Передача данных происходит между машинами, а также может происходить между машиной и человеком, который сам извлекает информацию из данных. В случае взаимодействия человека с машиной на уровне искусственного интеллекта объектом визуализации уже являются не данные, а извлеченная из них информация. До недавнего времени извлекать информацию из данных могли только люди. С возникновением искусственного интеллекта, извлекать информацию из данных начинают машины. Они играют роль первичного фильтра для выделения полезной информации из данных. Например, один из распространенных способов визуализации данных машинным обучением без участия человека – самоорганизующиеся карты (SOM), разработанные Т. Кохоненом [17] (Kohonen, 2001). Так, в электронной торговле с их помощью можно выделить группы клиентов в кластер с большим чеком, но малой частотой покупок, и кластер с малым размером чека, но высокой частотой покупок [20] (Luellen, 2019). Тем самым между машиной и человеком в современном обществе возникают не только потоки данных, но и потоки информации. В последнем случае человек получает как бы информационный «полуфабрикат», из которого он будет извлекать конечную информацию.
На рисунке 1 приведен пример использования искусственной нейронной сети SOM для извлечения информации из макроэкономических данных ряда европейских стран машинным обучением без учителя, то есть без исследователя, контролирующего эксперимент. SOM переводит данные в двумерную плоскость, и полученная информация позволяет человеку выявить путем визуализации взаимосвязи и закономерности сложной системы. Оптимальное число кластеров определяется достижением максимальной гомогенности внутри группы и гетерогенности между кластерами. Тоном на рисунке 1 показана разница в дистанции – более светлые тона показывают короткие дистанции, а темные – длинные [19] (López Iturriaga, Sanz, 2013). Из анализа изображений видно, что высокий дефицит бюджета (V3) ассоциируется с низкой нормой накопления (V5), низкой инфляцией (V16) и высокой безработицей (V20) [19]. Отметим, что цвет играет важную роль при визуализации информации, в особенности при межличностных коммуникациях. Значительное количество людей имеют особенности, и даже нарушения восприятия цвета и тона, которые необходимо учитывать, выбирая цветовую палитру. В особенности это важно при разработке конечных зрительных образов, предназначенных для лиц, принимающих решения. Это не второстепенный вопрос, а один из центральных аспектов визуализации сложной системы.
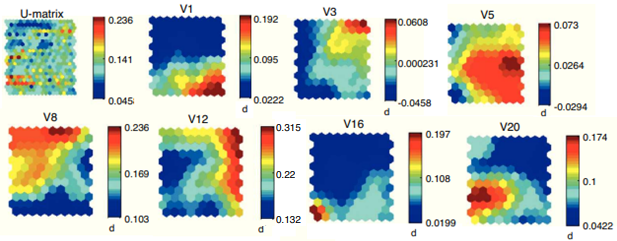
Рисунок 1. Машинное извлечение информации из данных: визуализация на основе самоорганизующихся карт
Источник: [19].
Этот пример иллюстрирует, как работу искусственного интеллекта, позволяющего извлекать первичную информацию из данных и визуализировать ее, так и необходимость дальнейшей обработки информации человеком на основе специальных экономических знаний.
Машинное обучение, нейронные сети и, в частности, SOM необязательно применять к большим данным, к чему и относится рассмотренный пример, но для повышения уровня значимости SOM требуется как можно более большая выборка. Большие данные дают такую выборку или даже популяцию, то есть включают всю совокупность изучаемых объектов.
Без первичного извлечения информации машиной на основе технологий искусственного интеллекта невозможно использовать большие данные – формирующийся у нас на глазах новый экономический ресурс. По счастливому совпадению или, что более вероятно, по логике развития ИКТ, появление больших данных совпадает с ростом возможностей искусственного интеллекта. Надо принимать во внимание, что без искусственного интеллекта извлечение информации из больших данных невозможно, но без человеческого интеллекта и глубокого дисциплинарного знания такая информация бессмысленна. Она является только полуфабрикатом. Окончательная роль в извлечении информации, постижении реальности для управленческих решений, остается за людьми. Здесь экономические науки должны найти свое место в эпоху господства информатики. С возрастанием подобно снежному кому объемов и разнообразия больших данных, машинного извлечения из них информации, роста значения машинных коммуникаций, с передачей информации по типу «машина – машина» и непосредственным использованием этой информации при принятии решений за экономическими науками должна быть закреплена подобная ниша.
Визуализация как способ справиться с комплексностью при постижении хозяйственных явлений и коммуникации полученных результатов
Известный авторитет в области презентации данных – Джин Желязны, советовал избегать 3d изображений при коммуникации выводов и результатов анализа [34] (Zelazny, 2016). Тем не менее при визуализации больших данных по хозяйственным системам и явлениям экономической жизни использование пространственных переменных имеет первостепенное значение. Противоречия здесь нет. Совет Джина Желязны касался презентации информации при коммуникациях «человек (аналитик) – человек (принимающий управленческое решение). Информация при таких коммуникациях представляет собой итоговый результат постижения сложного хозяйственного объекта или экономического явления. Иными словами, она – конечная абстракция, вывод. Поэтому она должна быть выражена наиболее наглядным визуальным образом, с использованием минимума графических средств. Подпись к визуальному образу должна сообщать итоговый результат – основной вывод.
В процессе движения к итоговому результату при постижении сложного хозяйственного объекта или экономического явления происходит переход от сложного образа к абстрактному. В случае больших данных исходный образ может представлять собой не визуализацию информации, а представление самих данных. В этом случае это скорее не конструкт – идеальный объект, а графическое представление реального объекта, подобное фотографии. Другой случай, когда исходный зрительный образ при человеко-машинном взаимодействии представляет собой визуализацию уже не данных, а извлеченной из них первичной информации. Это как бы «полуфабрикат более глубокой переработки» – результат применения искусственного интеллекта. Такой образ по-прежнему находится на минимальном уровне абстракции и со слабо выраженной концептуальной составляющей, то есть, он еще не законченный конструкт. Концептуальная составляющая будет возрастать как результат деятельности человеческого интеллекта. При этом визуализация с использованием пространственных переменных и трехмерное изображение имеют важное значение, если не основное, на промежуточных этапах постижения сложной реальности аналитиком, а роль графических примитивов возрастает при формировании и презентации выводов исследования. В случае научного исследования представленный в итоге зрительный образ должен быть недвусмысленно связан с концептуальной структурой, которая может быть изложена в текстовой форме. Неизбежная потеря информации при абстракции компенсируется использованием дисциплинарного знания в области экономики и менеджмента.
Визуальную иллюстрацию процесса постижения с возрастанием абстракции рассмотрим на примере графа, который занимает особое место среди форм визуализации сложных систем. Граф является тем визуальным инструментом, который в наибольшей степени соответствует сложной системе (рис. 2), показывая, как объекты и их качества, представленные узлами, так и отношения между ними, представленные дугами.

Рисунок 2. Визуальное представление больших данных с использованием графа
Источник: [16].
Интересна точка зрения Джима Каскаде о том, что графы потенциально способны достичь эффекта рычага, применительно к большим данным [16] (Kaskade, 2011) путем выбора их точки приложения. Эффект рычага – известная концепция в области финансов и экономики предприятия (финансовый рычаг, операционный рычаг, технологический рычаг). Общее для этих случаев состоит в том, что эффект обеспечивает приложение одного ресурса к другому, позволяющее достичь масштабирования результата. Для представления сложной системы в графе используются одновременно и графические примитивы, и позиция (рис. 2, 3, 4). Граф, представленный на рисунке 3, – дальнейший этап научной абстракции по сравнению с графом на рисунке 2. Из последовательной метаморфозы графов видно, как потеря данных, неизбежная при абстракции, путем редукции [26] (Rumpf, Ray, 2016) компенсируется возрастающей концептуализацией на основе дисциплинарного знания с использованием графических примитивов.
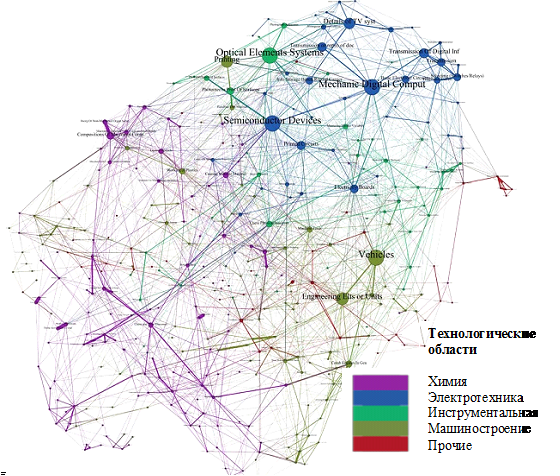
Рисунок 3. Глобальная карта технологической сложности
Источник [27].
Рассмотрим этот важнейший момент для визуализации информации подробнее. Представленный на рисунке 3 граф создан Шеном и соавторами в программе Gephi и построен на основе базы данных Corporate Invention Board, созданной во Франции в рамках консорциума между IFRIS и ESIEE [5]. Использованная база больших данных включает более 6 миллионов патентов, полученных с 1986 по 2005 год по всему миру большинством крупнейших исполнителей НИОКР [27] (Schoen, Villard, Laurens, Cointet, Heimeriks, Alkemade, 2012). Это случай визуализации структурированного массива больших данных как по количеству использованных при построении визуального образа данных (почти в шесть раз превосходящих максимальное количество строчек, допустимых в программе MS Excel), так и по охвату, который правомернее назвать не выборкой, а всей популяцией изучаемых объектов (в базе отражено 80% мировых частных инвестиций в НИОКР). Представленный граф является результатом абстракции, которую следует назвать «дисциплинарной».
При дисциплинарной абстракции она представляет собой процесс как редукции, так и обобщения. Как указывалось выше, при редукции в процессе обработки больших данных искусственным интеллектом неизбежна существенная потеря сигналов. Поэтому следует с осторожностью относиться к использованию аналитических инструментов обработки больших массивов данных [26]. Это обратная сторона абстракции путем редукции. Но человеку сложно воспринять из-за когнитивных ограничений и искажений восприятия даже то, что остается [32] (Tversky, Kahneman, 1981), ведь количество показанных на схеме (рис. 3) 389 узлов намного превышает возможности человеческого восприятия. Так, согласно одному из когнитивных лимитов, связанных с особенностями кратковременной памяти [7] (Baddeley, Hitch, 1974), человек может удерживать в кратковременной памяти не более 7 ± 2 элементов [23] (Miller, 1956), а сложную систему человек постигает, формируя в сознании когнитивную карту, в которую в среднем отбирается только 13–15 ключевых для него концепций (факторов) и важнейших отношений между ними [2] (Eliseeva, Platonov , Bergman, Yu, Luukka, 2015).
Наличие дисциплинарного знания, в нашем случае – в области экономики и менеджмента, позволяет изменить ситуацию к лучшему путем рассмотрения объекта как части целого – путем методологического холизма [4] (Pavlenko, 2014). Он реализуется наложением, а точнее – увязкой, результата абстракции, представленного зрительным образом, и дисциплинарного знания, представленного системой концепций. В терминах информатики системе концепций соответствует онтология изучаемой предметной области, которую и представляет дисциплинарное знание. Так, Шен и соавторы, в рассматриваемом примере [27], исходят из фундаментальных концепций, определяющих логику возникновения технологических новшеств: когнитивной дистанции и абсорбирующего потенциала [27, 24, 12] (Nooteboom, Van Haverbeke, Duysters, Gilsing, Van den Oord, 2007; Cohen, Levintal, 1990). Карта технологической сложности позволяет наложить патенты, полученные той или иной фирмой, на глобальный технологический ландшафт, причем цвет позволяет аналитику учесть технологическую область, размер – относительную важность узлов, расстояние на графе – технологическую дистанцию. Это все еще полуфабрикат, оставляющий наблюдателю возможность подключиться к процессу постижения реальности, но требующий значительных когнитивных усилий и дисциплинарных знаний, чтобы увязать его с указанными выше концепциями. Поэтому неслучайно он имеет трехмерную размерность изображения, которую не советуют применять для презентации результатов лицам, принимающим решения [34].
Ценность визуализации информации для конечного потребителя определяется той степенью, в которой она может легко, эффективно, точно и правильно рассказать ту историю, которая содержится в информации. Она определяется принципами постижения информации. Так, согласно принципам визуального постижения информации Гештальдской психологии, восприятие объектов как группы определяется: близостью – расположением их близко друг к другу; сходством, когда объекты имеют схожие атрибуты (например, цвет или форму); вложением, когда кажется, что объекты имеют границу вокруг себя (например, образованную линией или областью общего цвета); замкнутостью, когда открытые структуры воспринимаются как закрытые, завершенные и регулярные, если есть возможность их разумно интерпретировать как таковые; непрерывностью, когда объекты выровнены вместе или кажутся продолжением друг друга; связью, когда объекты связаны (например, линией) [25] (Rankin, 2016).
Граф на рисунке 4 визуально показывает важнейшую кооперационную сеть информационно-сетевой экономики.
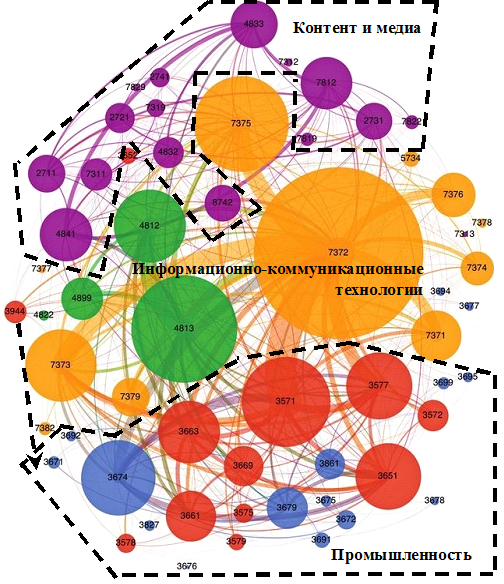
Рисунок 4. Межотраслевая кооперационная сеть по созданию и применению информационных и коммуникационных технологий
Источник: [8] (Basole, 2014) с дополнениями автора.
Кружками показаны рыночные сегменты и их объем, а дуги обозначают межфирменные связи между сегментами. Пунктирными линиями мы выделили три сферы, необходимые для создания и использования информационных и коммуникационных технологий. Этот двумерный граф представляет собой конечный результат визуального постижения реальности – тот уровень абстракции, когда результат визуализации вписан в систему стандартной отраслевой классификации и его можно однозначно интерпретировать в рамках концепций дисциплинарного знания. Поставщики информационных продуктов и услуг конечным потребителям – медийные компании и производители контента представляют наименьшую область по объему и количеству межфирменных связей. Сегменты, относящиеся к этой области, обведены на схеме пунктиром. Это может показаться неожиданным, но по характеру своей деятельности именно эта область, являющаяся видимой широкой публике, в обыденном сознании, предстает как главная в информационном обществе. Относительное значение области медиа и производства контента оказывается наименьшим в межотраслевой кооперационной сети по созданию и применению информационных и коммуникационных технологий. Как видно из графа, наибольшее количество межфирменных связей во всей сети сформировалось между предприятиями крупнейшего промышленного сегмента «Производство электронных компьютеров» (3571) и компаниями крупнейшего сегмента программного обеспечения «Производство стандартных пакетов программного обеспечения» (7372). Первостепенное значение межсекторной и даже межотраслевой кооперации в условиях информационно-сетевой экономики иллюстрирует следующий факт. Количество межфирменных связей между этими сегментами превосходит число связей между компаниями внутри промышленности и производства программного обеспечения.
Заключение
Центральная роль в извлечении информации из больших данных для постижения экономической реальности и принятия управленческих решений останется за человеческим интеллектом. Визуализация информации о сложных экономических системах и явлениях хозяйственной жизни останется за экономическими науками, учеными и экспертами. Это справедливо, по крайней мере, пока машиной не будет выполнен тест Тьюринга и не возникнет искусственный интеллект, сравнимый с человеческим. В связи с этим следует признать не вполне корректным представление, что так как информация будет извлекаться непосредственно искусственным интеллектом из больших данных [3, 28] (Karlik, Platonov, Tikhonova, Yakovleva, 2019; (Sejahtera, Wang, Indulska, Sadiq, 2018), использование любых экономических моделей и основанных на них методов экономического анализа окажется излишним. Идея полностью положиться на искусственный интеллект для анализа информации вместо тех людей, чей уровень интеллекта не позволил бы им пройти тест Тьюринга, и в тех случаях, когда используемые методы экономического анализа не соответствуют поставленным задачам, представляется обоснованной. Во всех других случаях для визуализации информации для принятия управленческих решений требуются специальные знания и навыки применения аналитических инструментов для использования информации, извлеченной искусственным интеллектом из больших данных. Для этого требуются знания, накопленные экономическими науками, и здесь лежит перспективная область их специализации в условиях информационного общества. Вырисовывается следующая триада относительно перспективы развития визуализации больших данных как экономического ресурса: визуализация данных останется областью господства информатики, обслуживающей искусственный интеллект; визуализация информации при «человеко-машинном» взаимодействии останется на стыке информатики и науки о бизнесе; экономика должна закрепить за собой «эксклюзивную область» постижения экономической реальности путем абстракции, в том числе путем визуализации информации.
Источники:
2. Елисеева И.И., Платонов В.В., Бергман, Ю-П., Луукка П. Когнитивное разнообразие и формирование доминантной логики инновационных компаний//Социология науки и технологий. – 2015. – №4. – С. 52-66.
3. Карлик А.Е., Платонов В.В., Тихонова М.В., Яковлева Е.А. Факторы успеха в использовании больших данных как нового экономического ресурса//МИР (Модернизация. Инновации. Развитие). – 2019. – Т. 10. – № 3. – С. 380-394. DOI: 10.18184/2079-4665.2019.10.3.380-394
4. Павленко Ю.Г. Методологический индивидуализм и холизм в экономике и социологии//Вестник Института экономики Российской Академии наук. – 2014. – № 3. – С. 34-44.
5. Федеральный институт промышленной собственности. Новости патентной информации. – 2010. – выпуск 1. [Электронный ресурс]. – Режим доступа: URL: https://new.fips.ru/about/vptb-otdelenie-vserossiyskaya-patentno-tekhnicheskaya-biblioteka/patent-information-news-1-2010.php (дата обращения 27.11.2020).
6. Ackoff R.L. From data to wisdom. Journal of Applied Systems Analysis. –1989. – № 16 – pp. 3-9
7. Baddeley A. D., Hitch G. Working Memory//The Psychology of Learning and Motivation. – 1974. – Vol. 8. – pp. 47–89. doi.org/10.1016/S0079-7421(08)60452-1
8. Basole R.C. Visual business ecosystem intelligence: lessons from the field. IEEE Computer Graphics and Applications 34(5):26-34. doi: 10.1109/MCG.2014.104.
9. Big Data Executive Survey 2016. An Update on the Adoption of Big Data in the Fortune 1000. Boston: New Vantage Partners LLC., 2016. 16 p. [Электронный ресурс]. – Режим доступа: URL: https:// newvantage.com/wp-content/uploads/2016/01/Big-Data-Executive-Survey-2016-Findings-FINAL.pdf (дата обращения 24.11.2020).
10. Boisot M. Knowledge assets: Securing competitive advantage in the information economy. – New York: Oxford University Press, 1998. – 254 pp.
11. Boisot M. Child J. Organizations as adaptive systems in complex environments: the case of China//Organization Science. – 1999. – No. 3(10). – pp. 1045-1063. DOI:10.1287/ORSC.10.3.237
12. Cohen W, Levintal D. Absorptive capacity—a new perspective on learning and innovation//Administrative Science Quarterly. – 1990. – No 1(35). pp. 128–152. DOI: 10.2307/2393553
13. Beer D., Burrows R. Popular Culture//Digital Archives and the New Social Life of Data. – 2013. [Электронный ресурс]. – Режим доступа: URL: https://doi.org/10.1177/0263276413476542 (дата обращения 29.11.2020).
14. How important is storytelling and visualization for your science? [Электронный ресурс]. – Режим доступа: URL: https://www.researchgate.net/post/How_important_is_storytelling_and_visualization_for_your_science (дата обращения 14.11.2020).
15. Kalakoski V., Henelius A., Oikarinen E., Ukkonen A., Puolamäki K. Cognitive ergonomics for data analysis. Experimental study of cognitive limitations in a data-based judgement task//Behaviour and Information Technology. – 2019. – Vol. 38. – No. 1. – pp. 1-10 DOI:10.1080/0144929X.2019.1657181
16. Kaskade J. Big Data and Graphs = Big Graph? November 19, 2011 [Электронный ресурс]. – Режим доступа: URL: https://jameskaskade.com/?p=2093 (дата обращения 24.11.2020).
17. Kohonen T. Self-Organizing Maps. – Berlin: Springer, 2001. – 501 pages.
18. Manovich L. What is visualisation?//Visualization studies. – 2010. – No.1 pp. 36-49
19. López Iturriaga F.J., Sanz I.P. Self-organizing maps as a tool to compare financial macroeconomic imbalances: The European, Spanish and German case//The Spanish Review of Financial Economics. – 2013. – Issue 2(11). – pp. 69-84. DOI: 10.1016/j.srfe.2013.07.001
20. Luellen E. An Updated Text Analytics Primer: Key Factors in a Text Analytics Strategy//Towards data science. – 2019. [Электронный ресурс]. – Режим доступа: URL: https://towardsdatascience.com/a-text-analytics-primer-key-factors-in-a-text-analytics-strategy-d24dc84a5576 (дата обращения 30.11.2020).
21. Aparicio M., Costa C.J. Data visualization//Communication Design Quarterly Review. – 2014. – No. 3 (1). – pp. 7–11.
22. Marr B. Big Data: 20 Mind-Boggling Facts Everyone Must Read//Forbes. 2015. [Электронный ресурс]. – Режим доступа: URL: https://www.forbes.com/sites/bernardmarr/2015/09/30/big-data-20-mind-boggling-facts-everyone-must-read/?sh=61c794af17b1 (дата обращения 24.11.2020)
23. Miller G. A. The magical number seven, plus or minus two: Some limits on our capacity for processing information//Psychological Review. – 1956 – No. 2 (63). – pp. 81–97. https://doi.org/10.1037/h0043158
24. Nooteboom B., Van Haverbeke W., Duysters G., Gilsing V., Van den Oord A. Optimal cognitive distance and absorptive capacity//Research Policy. – 2007. – Vol. 36. – No.7. – pp. 1016-1034. doi: 10.2139/ssrn.903745
25. Rankin J.G. Standards for Reporting Data to Educators: What Educational Leaders Should Know and Demand. – 2016. Abingdon-on-Thames: Routledge. – 150 pp.
26. Rumpf R.W., Ray W.C. Analysis of Large Data Sets / Emerging Trends in Applications and Infrastructures for Computational Biology, Bioinformatics, and Systems Biology. – Amsterdam: Elsevier, 2016. – pp. 327-332. https://doi.org/10.1016/B978-0-12-804203-8.00022-5
27. Schoen A., Villard L., Laurens P., Cointet J.-P., Heimeriks G., Alkemade F. The Network Structure of Technological Developments; Technological Distance as a Walk on the Technology Map/ Proceedings of 17th International Conference on Science and Technology Indicators. – 2012. – Montreal. – pp. 733-742.
28. Sejahtera F., Wang W., Indulska M., Sadiq S. Enablers and Inhibitors of Effective Use of Big Data: Insights from a Case Study / Proceedings of PACIS 2018 – 22nd Pacific Asia Conference on Information Systems. Ed. Tanabu M., Senoo D. Yokohama. 2018. [Электронный ресурс]. – Режим доступа: URL: https://aisel.aisnet.org/pacis2018/27(дата обращения 24.11.2020)
29. Ansari S.T., Nasreen A. Data Analysis and Visualization by extracting insights for Efficient Project Planning//International Journal of Computer Sciences and Engineering. – 2020. – No. 8(8). – pp. 34-38. https://doi.org/10.26438/ijcse/v8i8.3438
30. The Encyclopedia of Human-Computer Interaction, 2nd Ed. San Francisco: Interaction Design Foundation, 2016. [Электронный ресурс]. – Режим доступа: URL: https://www.interaction-design.org/literature/book/the-encyclopedia-of-human-computer-interaction-2nd-ed (дата обращения 19.11.2020)
31. Turing A. Computing Machinery and Intelligence//Mind. 1950. – No. 236(510). – pp. 433–460 https://doi.org/10.1093/mind/LIX.236.433.
32. Tversky A., Kahneman D. The Framing of Decisions and the Psychology of Choice//Science. – 1981. – No.211(4481). – pp. 453–458. doi: 10.1126/science.7455683
33. Shetty S. When, why and how to use Graph analytics for your big data. – 2017. [Электронный ресурс]. – Режим доступа: URL: https://www.packtpub.com/product/big-data-analytics-with-java/ 9781787288980
34. Zelazny G. Say It with Charts. Homewood. – Chicago: Dow Jones-Irwin, 1985. – 128 pp. Русск. издание: Говори на языке диаграмм. Пособие по визуальным коммуникациям. М.: Изд-во Манн, 2016. – 289 стр.
Страница обновлена: 20.07.2026 в 15:46:52
Download PDF | Downloads: 78 | Citations: 19
Big data visualization in economic sciences in the information society
Platonov V.V.Journal paper
Russian Journal of Innovation Economics
Volume 10, Number 4 (October-December 2020)
Abstract:
The article is devoted to visualization as a method of comprehending and communicating economic information extracted from big data in the perspective of searching for new directions in the development of economic and business sciences in the information society, when computer science has come to the fore. The concept of information visualization in relation to business sciences is clarified. The place of visualization in communication between people, as well as man and machine, is considered. Special attention is paid to abstraction by visualizing information extracted from big data for the study of complex economic systems, as well as presenting conclusions for decision makers. The problem of compensation for data loss when using software tools for information extraction and the role of disciplinary knowledge of economic sciences in its solution are discussed. The conclusions contained in the article are illustrated by the example of graphs as the most effective form of visual representation of complex economic systems. In particular, the process of comprehending economic reality by moving from a three-dimensional graph depicting a real object to a two-dimensional graph reflecting an ideal construct is considered.
Keywords: big data, information society, information analysis, complex business systems
Funding:
JEL-classification: O31, O32, O33
References:
Ackoff R.L (1989). From data to wisdom Journal of Applied Systems Analysis. (16). 3-9.
Ansari S.T., Nasreen A. (2020). Data Analysis and Visualization by extracting insights for Efficient Project Planning International Journal of Computer Sciences and Engineering. 8 (8). 34-38. doi: 10.26438/ijcse/v8i8.3438.
Aparicio M., Costa C.J. (2014). Data visualization Communication Design Quarterly Review. 3 (1). 7-11.
Arnkheym R. (1974). Iskusstvo i vizualnoe vospriyatie [Art and visual perception] M.: Progress. (in Russian).
Baddeley A. D., Hitch G. (1974). Working Memory Psychology of Learning and Motivation. 8 47-89. doi: 10.1016/S0079-7421(08)60452-1.
Basole R.C. (2014). Visual business ecosystem intelligence: lessons from the field IEEE Computer Graphics and Applications. 34 (5). 26-34. doi: 10.1109/MCG.2014.104.
Beer D., Burrows R. (2013). Popular Culture, Digital Archives and the New Social Life of Data Theory, Culture & Society. 30 (4). 47-71. doi: 10.1177/0263276413476542.
Big Data Executive Survey 2016. An Update on the Adoption of Big Data in the Fortune 1000New Vantage Partners LLC. Retrieved November 24, 2020, from https:// newvantage.com/wp-content/uploads/2016/01/Big-Data-Executive-Survey-2016-Findings-FINAL.pdf
Boisot M. (1998). Knowledge assets: Securing competitive advantage in the information economy New York: Oxford University Press.
Boisot M., Child J. (1999). Organizations as adaptive systems in complex environments: the case of China Organization Science. 10 (3). 237-252. doi: 10.1287/ORSC.10.3.237.
Cohen W., Levintal D. (1990). Absorptive capacity—a new perspective on learning and innovation Administrative Science Quarterly. 35 (1). 128-152. doi: 10.2307/2393553.
Eliseeva I.I., Platonov V.V., Bergman, Yu-P., Luukka P. (2015). Kognitivnoe raznoobrazie i formirovanie dominantnoy logiki innovatsionnyh kompaniy [Cognitive diversity and emerging of the dominant logic of innovative companies]. Sotsiologiya nauki i tekhnologiy. 6 (4). 52-65. (in Russian).
How important is storytelling and visualization for your science?Researchgate.net. Retrieved November 14, 2020, from https://www.researchgate.net/post/How_important_is_storytelling_and_visualization_for_your_science
Kalakoski V., Henelius A., Oikarinen E., Ukkonen A., Puolamäki K. (2019). Cognitive ergonomics for data analysis. Experimental study of cognitive limitations in a data-based judgement task Behaviour and Information Technology. 38 (1). 1-10. doi: 10.1080/0144929X.2019.1657181.
Karlik A.E., Platonov V.V., Tikhonova M.V., Yakovleva E.A. (2019). Faktory uspekha v ispolzovanii bolshikh dannyh kak novogo ekonomicheskogo resursa [Success factors in using big data as a new economic resource]. MIR (Modernization. Innovation. Research). 10 (3). 380-394. (in Russian). doi: 10.18184/2079-4665.2019.10.3.380-394.
Kaskade J. Big Data and Graphs = Big Graph?Jameskaskade.com. Retrieved November 24, 2020, from https://jameskaskade.com/?p=2093
Kohonen T. (2001). Self-Organizing Maps Berlin: Springer.
Luellen E. An Updated Text Analytics Primer: Key Factors in a Text Analytics StrategyTowards data science. Retrieved November 30, 2020, from https://towardsdatascience.com/a-text-analytics-primer-key-factors-in-a-text-analytics-strategy-d24dc84a5576
López Iturriaga F.J., Sanz I.P. (2013). Self-organizing maps as a tool to compare financial macroeconomic imbalances: The European, Spanish and German case The Spanish Review of Financial Economic. 2 (11). 69-84. doi: 10.1016/j.srfe.2013.07.001.
Manovich L. (2010). What is visualisation? Visualization studies. (1). 36-49.
Marr B. Big Data: 20 Mind-Boggling Facts Everyone Must ReadForbes. Retrieved November 24, 2020, from https://www.forbes.com/sites/bernardmarr/2015/09/30/big-data-20-mind-boggling-facts-everyone-must-read/?sh=61c794af17b1
Miller G.A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information Psychological Review. (2(63)). 81-97. doi: 10.1037/h0043158.
Nooteboom B., Van Haverbeke W., Duysters G., Gilsing V., Van den Oord A. (2007). Optimal cognitive distance and absorptive capacity Research Policy. 36 (7). 1016-1034. doi: 10.2139/ssrn.903745.
Pavlenko Yu.G. (2014). Metodologicheskiy individualizm i kholizm v ekonomike i sotsiologii [Methodological individualism and holism in economics and sociology]. Bulletin of the Institute of Economics of RAS. (3). 34-44. (in Russian).
Rankin J.G. (2016). Standards for Reporting Data to Educators: What Educational Leaders Should Know and Demand Abingdon-on-Thames: Routledge.
Rumpf R.W., Ray W.C. (2016). Emerging Trends in Applications and Infrastructures for Computational Biology, Bioinformatics, and Systems Biology Amsterdam: Elsevier.
Schoen A., Villard L., Laurens P., Cointet J.-P., Heimeriks G., Alkemade F. (2012). The Network Structure of Technological Developments; Technological Distance as a Walk on the Technology Map Science and Technology Indicators. 733-742.
Sejahtera F., Wang W., Indulska M., Sadiq S. (2018). Enablers and Inhibitors of Effective Use of Big Data: Insights from a Case Study 22nd Pacific Asia Conference on Information Systems.
Shetty S. When, why and how to use Graph analytics for your big dataPacktpub.com. Retrieved from https://www.packtpub.com/product/big-data-analytics-with-java/ 9781787288980
The Encyclopedia of Human-Computer Interaction, 2nd EdInteraction Design Foundation. Retrieved November 19, 2020, from https://www.interaction-design.org/literature/book/the-encyclopedia-of-human-computer-interaction-2nd-ed
Turing A. (1950). Computing Machinery and Intelligence Mind. 510 (236). 433-460. doi: 10.1093/mind/LIX.236.433.
Tversky A., Kahneman D. (1981). The Framing of Decisions and the Psychology of Choice Science. 211 (4481). 453-458. doi: 10.1126/science.7455683.
Zelazny G. (2016). It with Charts. Homewood. Chicago: Dow Jones-Irwin, 1985. – 128 pp [It with Charts. Homewood. – Chicago: Dow Jones-Irwin] M.: Mann, Ivanov i Ferber. (in Russian).