Предобработка и постобработка данных для прогнозирования доходов федерального бюджета Российской Федерации
Борисова О.В.1, Ященко А.И.1
1 Финансовый университет при Правительстве Российской Федерации, ,
Скачать PDF | Загрузок: 54
Статья в журнале
Экономика, предпринимательство и право (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 14, Номер 10 (Октябрь 2024)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=75096466
Аннотация:
Постоянно изменяющиеся макроэкономические условия стимулируют государственные структуры и компании совершенствовать систему прогнозирования. В результате возрастают требования к наборам данных, их обработке, качеству выбираемых моделей, что стимулирует исследования в данном направлении.
Показан процесс преобразования данных до и после прогнозирования. Выявлены основные процедуры, которые необходимо использовать для преобразования данных. Результаты исследования применялись в процессе прогнозирования доходов федерального бюджета РФ, что позволило получить качественную прогностическую модель. Применение предлагаемого авторами процесса позволит оперативно обрабатывать данные для обновления прогностической модели
Ключевые слова: предобработка данных, постобработка данных, доходы федерального бюджета, прогнозирование, анализ данных, финансирование
Финансирование:
Статья подготовлена по результатам исследований, выполненных за счет бюджетных средств по государственному заданию ФГОБУ ВО «Финансовый университет при Правительстве РФ»
JEL-классификация: J31, J32, J33, J38
Введение
Анализ экономической деятельности современных хозяйствующих субъектов традиционно предполагает комбинирование различных подходов к оценке явлений, тенденций и особенностей, характеризующих рассматриваемое состояние объектов и систем. Данное комбинирование обусловлено необходимостью прогнозирования будущих условий обеспечения функционирования, которые определяют конкретные целевые показатели работы домохозяйств, организаций и институциональных единиц [1].
Детерминируемый условиями неопределенности и нестандартизированности результат хозяйственной деятельности по-разному классифицируется и учитывается в рамках определяющих процессов и правил [2].
Процедуры анализа и оценки сведений при этом выступают в качестве инструментов осуществления прогнозных мероприятий, включающих определение источников, типов данных, ресурсов их извлечения и сопоставления [3]. Инструментарий получения конкретного оценочного заключения данных при этом нередко сводится к ручной предобработке данных, в том числе – в случаях машинного обучения [4], в том числе элементах искусственного интеллекта [5]. Хуан Ю., Милани М., Чианг Ф. (2018; [6]) развивают подход к очистке данных и указывают инструменты, способствующие возможностям конфиденциальной обработки дополнительных данных.
Другое направление исследования сводится к применению методов кластеризации данных при их предварительной обработке [7]. Энтони Э., Срикант Н. (2021; [8]) предлагают использовать адаптированную модель скользящего межквартильного диапазона для комплексного исследования сведений, аналогичную [9] и предлагают рассматривать несколько различных инструментов для анализа и оценки сведений на основе общего управления качества данных, требования к хранилищу сведений, подходам к определению качества данных в виде комплексных методологий. В результате, требуемые задачи предварительной обработки данных их последовательность выполнения и параметры зависят от многих факторов. К ним относят тип и источник данных, системный контекст, приложения, доступные ресурсы и тип алгоритма, потребляющего данные и др. Предварительная обработка данных при этом адаптируется к конкретной проблеме или приложению [3], а постобработка зависит от нее.
Необходимость учета ряда параметров в рамках прогнозных мероприятий формирует требование к установлению формализованного и описанного подхода к процедуре выработки управленческого решения. В рамках научного исследования формируется методическое описание, позволяющее нивелировать проблематику определения перспективного состояния бюджетной системы [10], [11]. Выработка описанных целевых мероприятий предобработки и постобработки данных представляется при этом актуальным направлением исследования, формирующем целевое решения для принятия прогнозного управленческого решения.
Цель исследования — разработать методический алгоритм процесса предобработки и постобработки данных, используемых для прогнозирования доходов федерального бюджета РФ. В работе рассмотрены основные проблемы, с которыми сталкиваются аналитики при прогнозировании показателей и процедуры преобразования.
Предобработка данных для построения прогнозной модели
Формирование базы данных для прогнозирования доходов Федерального бюджета РФ было начато авторами со сбора в открытых источниках первичных данных. В набор сведений вошло 35 годовых, 40 квартальных показателей и 30 месячных сведений, характеризующих состояние российской экономики. В качестве источников использованы данные, предоставляемые: Банком России, Министерством финансов РФ, Московской фондовой биржей и Федеральной службой государственной статистики.
В процессе первичного сбора сведений было выявлено несколько исходных проблем:
1. Значительное количество временных рядов, доступно с различных периодов (с 2011 г., 2012 г. или 2014 г.), что существенно ограничивает объем исследования, приводя к наличию пропущенных значений на определенных интервалах;
2. Наличие различной периодичности – кратности временных рядов: годовые, квартальные, месячные;
3. Изменение методик расчета показателей государственными органами, приводящее к уменьшению временного интервала рассматриваемых данных. В результате возникала необходимость пересчета отдельных групп показателей [1];
4. Дублирование данных различными ведомствами, отличающихся размером и содержанием, их корректировка и правка в последующие периоды.
Выявленный перечень проблем привел к необходимости использования ряда процедур предобработки данных для приведения их к виду, который целесообразно использовать при построении прогнозных моделей. Основные процедуры данной предобработки, их краткая характеристика и сущность представлены в табл.1.
Таблица 1
Процедуры предобработки и проверки данных при прогнозировании доходов федерального бюджета
|
№
|
Процедуры
предобработки данных
|
Сущность
процедуры
|
Использование
процедуры авторами в работе
|
|
1
|
Обработка
дубликатов
|
Предварительная
обработка данных, предполагающая работу с двумя или более повторяющимися
значениями, отражаемыми по определенным признакам или атрибутам.
Подразумевает виды разрешения: полное или частичное удаление дубликатов,
применение отличных идентификаторов, хеш-функций [12]
|
Осуществлялась в
процессе первичного подбора показателей
|
|
2
|
Выявление
противоречий
|
Очистка данных,
предполагающая исключение соответствия одному набору входных значений
различных наборов выходных атрибутов. Подразумевает виды разрешения:
исключение противоречивого значения или интегрирование обоих выходных
атрибутов [13]
|
Не было выявлено
|
|
3
|
Введение фиктивных
значений
|
Включение
дополнительных переменных по бинарной или иной характеристике, предполагающее
дополнение набора данных значениями качественного или заменяющего типов с
целью анализа дополнительного объема сведений. Подразумевает виды: бинарное
включение (0, 1), заменяющее включение (в виде заполнения пропусков) [14]
|
Не включались
|
|
4
|
Восстановление
данных
|
Установление
оптимального критерия при интерполяции, реставрации или иной работе с
данными, способствующее на основе требуемого порога среднестатистического
отклонения обеспечить замену, переработку или заполнение рядов данных.
Подразумевает виды: исключение объектов некомплектного типа или различное
заполнение прежних записей [15]
|
Не проводилось
|
|
5
|
Заполнение
пропусков
|
Восстановление
заданной структуры первичных данных, предполагающее выравнивание сведений
между различными группами наблюдений или видами показателей на требуемом
интервале. Подразумевает виды: взвешивание данных по выставленным
коэффициентам, заполнение по вспомогательным моделям, подбор по группе или
ближайшим известным данным и т.д. [16]
|
Применялось для
ежеквартальных и ежемесячных данных, ряды которых начинаются после 2011 г.
|
|
6
|
Сглаживание тренда
|
Локальное
усреднение рассматриваемых данных, предполагающее взаимное устранение их
несистематических компонент. Подразумевает виды: экспоненциальное
сглаживание, скользящее среднее, использование первых и вторых разностей,
логарифмирования и т.д. [17].
|
Осуществлялось для
части выборки при преобразовании данных и их приведения к стационарному виду
|
|
7
|
Подавление шума
|
Устранение данных
нерелевантного или случайного типов, полученных в процессе ошибок сбора,
измерения, внутренней изменчивости сведений и пр. Подразумевает виды:
преобразование Фурье, анализ основных компонентов, перекрестная проверка и
т.д. [18].
|
Не проводилось
|
|
8
|
Редактирование
аномальных значений
|
Корректировка
переменных, значения которых отклонены от ожидаемых, вследствие ошибок сбора,
наличия нестандартных событий, выбросов. Подразумевает виды: ручная обработка
(метод межквартильного размаха, z-оценка и проч.), нормализация
и стандартизация данных [19]
|
Не проводилось
|
В процессе сбора статистических данных о состоянии экономики РФ авторы столкнулись со значительным количеством дубликатов по макроэкономическим показателям (например, ВВП, ИПЦ и др.). Это было связано с регулярным уточнением прогнозных и фактических сведений. В результате в рассматриваемую в работе базу были включены итоговые скорректированные данные, учитываемые на конец соответствующего периода.
Наличие временных рядов, доступных с различных периодов привело к необходимости заполнения пропущенных значений. Авторами были восстановлены показатели:
– квартальные среднедушевые денежные доходы населения за 2011 – 2012 гг., – ранее отсутствовавшие;
– годовые сведения: рентабельность активов; рентабельность проданных товаров, продукции, работ, услуг; кредиторская задолженность, за 2023 г., – в связи со значительным лагом в публикации данных.
В виде самостоятельной процедуры сглаживание тренда не осуществлялось. Однако, сведения, включаемые в базу, прошли тест Дики-Фулера (DF) [2] на стационарность (табл.2) и большинство из них было преобразовано. Собранные экономические показатели были приведены к ценам 2011 г. по традиционной модели (1).
|
|
(1)
|
где, F – значение отчетного периода,
P – базисного периода (2011 г.),
Kn – коэффициент приведения, может быть рассчитан, как ![]() ,
где r – процентная ставка, или иной коэффициент для оценки [20].
,
где r – процентная ставка, или иной коэффициент для оценки [20].
Таблица 2
Результат теста Дики-Фулера для финансовых и макроэкономических данных (фрагмент таблицы)
|
№
|
Показатели
|
Исходные данные
|
Данные, приведенные к ценам 2011 г
|
Первые разности логарифма
| ||||||
|
Тест без константы
|
Тест с константой
|
Тест с константой
трендом
|
Тест без константы
|
Тест с константой
|
Тест с константой
трендом
|
Тест без константы
|
Тест с константой
|
Тест с константой
трендом
| ||
|
1
|
Доходы
федерального бюджета, ежегодные
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
–
|
–
|
|
2
|
ВВП,
ежегодный
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
|
3
|
Среднедушевые
денежные доходы населения, ежегодные
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
|
4
|
Сальдо
прибылей и убытков, ежегодные
|
+
|
+
|
+
|
+
|
+
|
+
|
–
|
–
|
–
|
|
5
|
Доходы
федерального бюджета, ежеквартальные
|
–
|
–
|
–
|
+
|
+
|
+
|
+
|
+
|
+
|
|
6
|
ВВП,
ежеквартальный
|
–
|
–
|
–
|
+
|
+
|
+
|
–
|
+
|
+
|
|
7
|
Доходы
федерального бюджета, ежемесячные
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
–
|
–
|
|
|
…
|
|
|
|
|
|
|
|
|
|
Ежемесячные показатели помимо приведения к ценам 2011 г., были переведены в первую разность логарифма. Пример стационарного и нестационарного тренда годовых доходов приведен на рис.1. В результате для исследования выбирались сглаженные ряды данных.
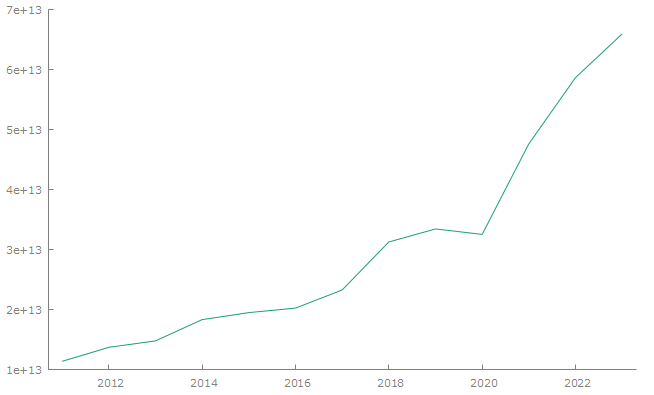
а) стационарный ряд |
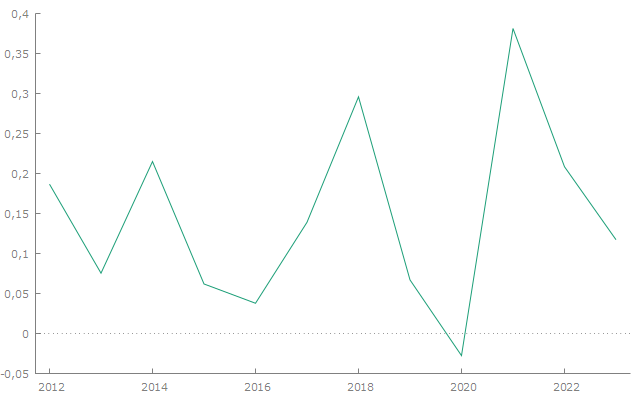
Б) нестационарный ряд |
Источник: разработано авторами на основе [21]
Временные ряды, являющиеся индексами, остались без изменения. Это позволило значительную часть годовых и квартальных показателей привести к стационарному виду.
Ежемесячные показатели по мимо приведения к ценам 2011 г., были переведены в первую разность логарифма. Пример стационарного и нестационарного тренда годовых доходов приведен на рис. 1. В результате для исследования выбирались сглаженные ряды данных.
Очистка годовых и квартальных данных на наличие шума и их обработка специальными процедурами с целью сглаживания не производилась, поскольку применяемые при прогнозе временные ряды не отличаются большой размерностью. Основная задача, поставленная авторами в исследовании, была связана с получением прогнозных значений, которые корректно отражают будущие доходы. При этом использование подобных процедур предполагает усреднение данных, не позволяющее получить требуемые искомые значения, в том числе – в условиях изменчивой экономической среды 2022 – 2024 гг.
Поскольку рассматриваемые данные имеют сезонность, перед приведением сведений к стационарному виду, она может устраняться с помощью модели TRAMO/SEATS [3] [22].
В ряде случаев показатели предварительно логарифмирвались или возводились в квадрат. Логарифмирование позволило определить внутренне-линейную модель для временного ряда, который изначально не был линейным. Данный этап позволил получить целевой вид у ряда показателей. Преобразования осуществлялись с использованием информационной системы GRETL по следующей модели (1), что позволяло их линеоризовать:
|
|
(1)
|
После логарифмирования данные преобразовывались в стационарный вид с применением метода первых разностей (чья эффективность доказана [23], [24]) (2):
|
|
(2)
|
![]() –
значение Y
показателя i на уровне
временной отметки t,
–
значение Y
показателя i на уровне
временной отметки t,
![]() –
значение Y показателя
i на уровне временной
отметки t–1.
–
значение Y показателя
i на уровне временной
отметки t–1.
Если после преобразований данные оставались не стационарными, то переменные возводились в квадрат, после чего определялась их первая разность. В большинстве случаев этот механизм позволил привести ряды к стационарному виду.
Подобная процедура позволяет подготовить данные к построению модели. Результаты данного построения были описаны в предыдущих исследованиях авторов ( [25], [26]).
После построения прогноза полученные результаты требуется интерпретировать. Без процедуры перевода в большинстве моделей сделать это не представляется возможным, поскольку, по оценкам авторов, значительная часть прогнозных моделей построена на преобразованных в стационарный вид данных. С этой целью исследователями была произведена постобработка рассмотренных данных.
Постобработка данных для интерпретации результатов прогнозной модели
Постобработка данных включает перевод полученных по модели прогнозов к первоначальному виду. Такой перевод необходим для получения данных в сопоставимых показателях, что позволяет на их основе принимать хозяйственные решения. Метод преобразования зависит от методики, используемой для перевода каждого показателя в стационарный вид и в цены 2011 г. (табл.3).
Таблица 3
Методы перевода показателей прогнозной модели для сравнения результатов
|
№
|
Вид
преобразования
|
Характеристика
метода перевода к первоначальному виду
|
Формула
|
|
1
|
Первая разность переменных
|
Перевод к
первоначальному виду после обработки данных не осуществляется.
Преобразованные сведения сопоставляются со сведениями за аналогичные периоды
|
где у – прогнозное значение, скорректированное с учетом предобработки данных; |
|
2
|
Вторая разность переменных
|
| |
|
3
|
Разность логарифмов переменных
|
Перевод к
первоначальному виду осуществляется с применением функции экспоненты
заданного числа (степени, в которую возводится основание экспоненты –
основания натурального логарифма). Преобразование разности переменных не
переводится в дальнейший вид
|
где e – число Эйлера, n – степень возведения [28] |
|
4
|
Квадрат переменных
|
Перевод к
первоначальному виду обеспечивается выделением квадрата из полученного
значения переменной соответствующего периода
|
|
|
5
|
Данные в ценах базисного периода
(2011г.)
|
Осуществляется на
основе приведения ценовых значений показателей прошлых периодов к отметкам
отчетного срока 2011 г.
|
где F – значение отчетного периода, P – базисного периода (2011 г.), |
В итоге процесс прогнозирования доходов и расходов, включая процедуры предобработки и постобработки данных может быть представлен в виде (рис.2).
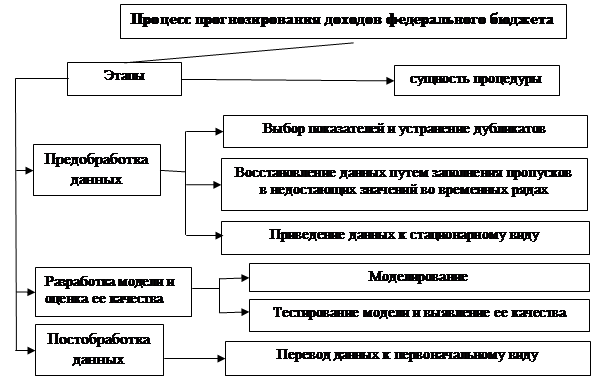
Рис. 2. Процесс прогнозирования доходов федерального бюджета.
Источник: разработано авторами
Осуществление подобного процесса (рис.2) позволяет корректно обработать имеющиеся сведения и повысить качество прогноза.
Результаты примирения предобработки и постобработки данных при прогнозировании доходов федерального бюджета
Результаты преобразования данных были апробированы на конкретном примере. Для этого были построены четыре однофакторные модели. Две модели по первоначальным данным и две по предобработанным.
Для тестирования использовались ежеквартальные данные по доходам федерального бюджета РФ с 2011 г. по 2023 г., в том числе – нефтегазовым и связанным с внутренним производством. Все временные ряды изначально были стационарны. Общий объём выборки – 50 периодов. Результаты расчетов представлены в табл.4.
Таблица 4
Результаты расчетов по моделям прогноза доходов федерального бюджета РФ
|
Наименование
показателя
|
Модели
| |||
|
1
|
2
|
3
|
4
| |
|
Регрессор
модели
|
Ненефтедоходы
|
Доходы, связанные с внутреннем производством, взятые с лагом 4
| ||
|
первоначальные данные
|
приведенные к ценам 2011 г.
|
первоначальные данные
|
приведенные к ценам 2011 г.
| |
|
Нецентрированный
R-квадрат
|
0,977
|
0,987
|
0,948
|
0,971
|
|
Центрированный
R-квадрат
|
0,982
|
0,984
|
0,961
|
0,966
|
|
F(1,
50)
|
2998,96
|
3340,76
|
–
|
–
|
|
F(1,
46)
|
–
|
–
|
1199,98
|
1448,44
|
|
Р-значение
(F)
|
2,66E-46
|
1,86E-47
|
1,33E-34
|
2,02E-36
|
|
Стат.
Дарбина-Уотсона
|
1,88
|
1,67
|
1,86
|
1,81
|
|
Средняя
ошибка (ME)
|
-38,996
|
-90,152
|
-192,05
|
244,08
|
|
Корень
из средней квадратичной ошибки (RMSE)
|
972,71
|
1582,4
|
1499,9
|
2376,5
|
|
Средняя
абсолютная ошибка (MAE)
|
792,8
|
1200,8
|
1228,8
|
1958
|
|
Средняя
процентная ошибка (MPE)
|
-2,3803
|
-2,5439
|
-6,38
|
5,68
|
|
Средняя
абсолютная процентная ошибка (MAPE)
|
11,602
|
11,533
|
17,40
|
18,05
|
|
U-cтатистика
Тейла (Theil's U)
|
0,15992
|
0,16213
|
0,24
|
0,25
|
|
Прогнозное
значение доходов федерального бюджета на 1 квартал 2024 г
|
9523,34
|
9318,95
|
9256,711
|
9493,331
|
В результате модели, разработанные по данным приведенным к ценам 2011 г., имели высокий коэффициент детерминации и более низкую MAPE. В то же время, RMSE, MAE, MPE у таких моделей был выше.
В связи с неоднозначностью полученных результатов были спрогнозированы доходы федерального бюджета на первый квартал 2024 г. Наилучшие результаты показала 3 модель: прогноз по этой модели на 1 квартал 2024 г. характеризуется минимальной ошибкой. Далее прогнозные результаты по моделям сравнивались с официальными годовыми прогнозами с 2011 г. по 2023 г. (табл.5).
Таблица 5
Сравнение результатов расчетов и официальных прогнозов доходов федерального бюджета РФ
|
Год
|
Фактические
доходы
|
Официальный прогноз
|
Модели
| ||||
|
1
|
2
|
3
|
4
| ||||
|
2011
|
11 367,65
|
8 617,80 [30]
|
10 478,70
|
10 440,90
|
0,00
|
0,00
| |
|
2012
|
12 855,54
|
10 627,80 [31]
|
11 991,50
|
11 903,16
|
11 215,90
|
10 935,63
| |
|
2013
|
13 019,94
|
12 395,40 [32]
|
12 058,10
|
11 981,04
|
11 793,00
|
11 517,38
| |
|
2014
|
14 496,88
|
13 485,50 [33]
|
13 409,80
|
12 751,68
|
12 961,60
|
12 079,70
| |
|
2015
|
13 659,24
|
14
923,90 [34]
|
13
558,30
|
12
676,17
|
12
898,50
|
11 756,32
| |
|
2016
|
13 460,04
|
13
958,00 [35]
|
13
858,20
|
13
826,42
|
12
390,80
|
12 102,76
| |
|
2017
|
15 088,91
|
13
488,00 [36]
|
14
916,70
|
15
327,77
|
14
513,50
|
14 882,20
| |
|
2018
|
19 454,37
|
15
258,00 [37]
|
18
292,80
|
18
529,79
|
18
399,70
|
18 725,45
| |
|
2019
|
20 188,80
|
19
969,00 [38]
|
20
325,70
|
20
786,74
|
20
274,40
|
20 788,01
| |
|
2020
|
18 719,09
|
20
379,40 [39]
|
20
341,40
|
20
324,83
|
19
940,50
|
20 377,04
| |
|
2021
|
25 286,38
|
18
765,10 [40]
|
25
527,20
|
24
745,37
|
24
595,10
|
23 836,67
| |
|
2022
|
27 824,39
|
25
021,90 [41]
|
27
762,40
|
26
136,21
|
28
507,80
|
26 543,19
| |
|
2023
|
29 124,05
|
26
130,30 [42]
|
30
402,60
|
29
649,16
|
30
296,40
|
29 074,92
| |
|
MAPE
|
2182,39
|
690,41
|
933,39
|
901,23
|
1159,44
| ||
Исследования показали, что полученные прогнозы годовых доходов имеют минимальные ошибки при использовании данных, не прошедших предобработку. У моделей, построенных по предобротным данным, MAPE возрастает почти на треть.
Анализ MAPE в динамике показывает, что они возрастают в 2014, 2018, 2020, 2023 г. по всем моделям за исключением четвертой. Связано это с условиями экономической нестабильности в указанные периоды и изменением тренда. Последняя четвертая модель хуже демонстрирует эту динамику, поскольку ее предсказательный уровень ниже.
В то же время по размеру MAPE авторские модели существенно лучше предсказывают динамику доходов федерального бюджета, чем модель, используемая для прогнозов на федеральном уровне.
Заключение
Проведенное исследование показало, что:
1. Прогнозирование доходов федерального бюджета является процессом, включающим три основных этапа: сбор и предобработку данных, непосредственно прогнозирование и постобработку данных;
2. В рамках исследования подробно рассмотрены первый и последний этап. В результате выявлено, что в научных исследованиях недостаточно внимания уделяется их раскрытию, что затрудняет воспроизведение и импликацию исследований на данных РФ;
3. Для каждого прогнозируемого показателя определен специфический набор процедур, который позволит привести его к необходимому виду для включения в прогнозную модель. Отчасти набор процедур будет определяется размерностью временного ряда;
4. Определена необходимость постобработки данных после получения результата. Она представляет алгоритм, в рамках которого взаимоувязан ряд процедур, поставленных в зависимость от предобработки данных. Его реализация позволяет получить результат моделирования доходов федерального бюджета, который может сравниваться с фактическими доходами бюджета РФ или с прогнозами Минфина и Минэкономразвития России.
5. Авторские расчёты, представленные в исследовании, показали, что при невысокой размерности временных рядов (50 периодов) наилучшие результаты прогнозирования получаются у моделей, данные в которых подвержены минимальным изменениям.
6. На больших выборках предобработка данных является обязательной с целью приведения временных рядов к стационарному виду. В этом случае для прогнозирования должны быть использованы данные, прошедшие предобработку, что снизит предсказательную силу модели, но позволит не меняться характеристикам временных рядов со временем. А следовательно, появится возможность подобрать модель для прогнозирования ежемесячных доходов федерального бюджета РФ.
[1] В рамках текущего исследования пересчет показателей не проводился
[2] Разновидность методики анализа временных рядов на стационарность. В базовом виде тест Дики-Фулера относится к тестам на единичные корни для случая образования стационарного ряда первыми разностями в формализованном виде: в случае первых разностей в стационарном виде
[3] Объединение моделей TRAMO (Time Series Regression with ARIMA Noise, Missing Observations, and Outliers – регрессия временных рядов с ARIMA, выбросами и пропущенными значениями) и Signal Extraction in ARIMA Time Series – извлечение сигнала из временных рядов ARIMA) способствует расширению модели ARIMA, предполагающая первичное обнаружение экстремальных возмущение данных, а затем их – линеаризацию
Источники:
2. Сысоева М.В., Диканев Т.В., Сысоев И.В. Выбор временных масштабов при построении эмпирической модели // Известия высших учебных заведений. Прикладная нелинейная динамика. – 2012. – № 2. – c. 54-62. – doi: 10.18500/0869-6632-2012-20-2-54-62.
3. Tawakuli A., Havers B., Gulisano V., Kaiser D., Engel T. Survey:Time-series data preprocessing: A survey and an empirical analysis // Journal of Engineering Research. – 2024. – № 1. – p. 38.
4. Krishnan S., Franklin M.J., Goldberg K., Wang J., Wu E. ActiveClean: An Interactive Data Cleaning Framework For Modern Machine Learning // Sigmod '16: Proceedings of the 2016 International Conference on Management of Data. 2016. – p. 2117 – 2120.
5. Krishnan S., Wang J., Franklin M.J., Goldberg K., Kraska T., Milo T., Wu E.. Sampleclean: Fast and reliable analytics on dirty data // IEEE Data Eng. Bull. – 2015. – № 38(3). – p. 59–75.
6. Huang Y., Milani M., Chiang F. Privacy-aware data cleaning-as-a-service // Information Systems. 2020. – p. 1-30.
7. Kirchner K., Zec J., Delibasic B. Facilitating data preprocessing by a generic framework: a proposal for clustering // Artificial Intelligence Review. – 2016. – № 3. – p. 271–297.
8. Ebin A., Sreekanth N., Sunil Kumar R.K., Nishanth T. Data Preprocessing Techniques for Handling Time Series data for Environmental Science Studies // International Journal of Engineering Trends and Technology. – 2021. – p. 196 – 207.
9. Batini C., Cappiello C., Francalanci C., Maurino A. Methodologies for data quality assessment and improvement // ACM Computing Surveys. – 2009. – № 41(3). – p. 1–52. – doi: 10.1145/1541880.1541883.
10. Осмоловская-Суслина А.Л., Борисова С.Р. Доходы региональных бюджетов в начале 2022 г.: основные тенденции и факторы риска // Финансовый журнал. – 2022. – № 6. – c. 25 – 43.
11. Федотов Д.Ю. Анализ прогнозирования налоговых доходов федерального бюджета России // Финансы и кредит. – 2017. – № 34(754). – c. 2016 – 2031.
12. Макаров А.В., Намиот Д.Е. Обзор методов очистки данных для машинного обучения // International Journal of Open Information Technologies. – 2023. – № 10. – c. 70 – 78.
13. Nwagwu H.C., Okereke G., Nwobodo C. Mining and visualising contradictory data // J Big Data 4. – 2017. – № 36. – p. 1 – 11.
14. Пильник Н.П., Поспелов И.Г., Станкевич И.П. Об использовании фиктивных переменных для решения проблемы сезонности в моделях общего экономического равновесия // Экономический журнал. – 2015. – № 2. – c. 249 – 270.
15. Сорокин А.А., Бородянский И.М., Дагаев А.В. Сравнительный анализ методов восстановления пропущенных данны // Известия ЮФУ. Технические науки. – 2020. – № 4(214). – c. 93 – 107.
16. Рыженкова К. В. Методы восстановления пропуска данных при проведении статистических исследований // Интеллект. Инновации. Инвестиции. – 2012. – № 3. – c. 127 – 133.
17. Петрушин В. Н., Рытиков Г. О. Формализация временного ряда методом двойного сглаживания // Cloud of Science. – 2014. – № 2. – c. 230 – 238.
18. Копырин А.С., Видищева Е.В. Технологии обработки и очистки данных, выявления и устранения шумов на временном ряду // Вестник Академии знаний. – 2020. – № 4 (39). – c. 220 – 228.
19. Серышева И.А. Фильтрация выбросов в задачах статической и динамической обработки данных в эталонах времени и частоты // Вестник ИрГТУ. – 2018. – № 10 (141). – c. 67 – 77.
20. Суворов Н.В., Балашова Е.Е. Модельный инструментарий прогнозно-аналитических исследований динамики межотраслевых связей отечественной экономики // Проблемы прогнозирования. – 2009. – № 6. – c. 16 – 33.
21. Федеральный бюджет РФ. Краткая информация об исполнении федерального бюджета. Министерство финансов Российской Федерации. [Электронный ресурс]. URL: https://minfin.gov.ru/ru/statistics/fedbud (дата обращения: 20.08.2024).
22. Бессонов В.А., Петроневич А.В. Сезонная корректировка как источник ложных сигналов // Экономический журнал высшей школы экономики. – 2013. – № 4. – c. 554 – 584.
23. Губанов В.А. Сравнение методов сезонной корректировки временных рядов // Научные труды: Институт народнохозяйственного прогнозирования РАН. – 2010. – № 8. – c. 149 – 170.
24. Староверова К.Ю., Буре В.М. Мера различия временных рядов, основанная на их характеристиках // Вестник СПбГУ. Серия 10. Прикладная математика. Информатика. Процессы управления. – 2017. – № 1. – c. 51 – 60.
25. Борисова О. В., Ященко А.И. Подход к прогнозированию макроиндикаторов в России // Менеджмент и бизнес-администрирование. – 2023. – № 3. – c. 75-83. – doi: 10.33983/2075-1826-2023-3-75-83.
26. Борисова О. В., Комиссарова А. В. Модели прогнозирования бюджетных доходов в России // Финансовая жизнь. – 2023. – № 3. – c. 53-58.
27. Энгл Р.Ф., Грэнджер К.У.Дж. Коинтеграция и коррекция ошибок:представление, оценивание и тестирование // Прикладная эконометрика. – 2015. – № 3(39). – c. 106 – 135.
28. Оруджев Э.Г-О, Гусейнова С.М-Г. Коинтеграционный анализ взаимовлияния ВВП Азербайджана, России, Беларуси и Казахстана // Известия СПбГЭУ. – 2020. – № 4 (124). – c. 31 – 40.
29. Мустафина Д.А., Буракова А.Е., Мустафин А.И., Александрова А.С. Обобщенная многомерная интерполяция методом наименьших квадратов // Вестник ПНИПУ. Электротехника, информационные технологии, системы управления. – 2018. – № 27. – c. 30 – 48.
30. Основные направления бюджетной политики на 2011 год и плановый период 2012 и 2013 годов. Информационная система «Гарант.РУ». [Электронный ресурс]. URL: https://www.garant.ru/products/ipo/prime/doc/12077757/?ysclid=lzwunw94m0129805277 (дата обращения: 02.09.2024).
31. Основные направления бюджетной политики на 2012 год и плановый период 2013 и 2014 годов. Информационная система «Гарант.РУ». [Электронный ресурс]. URL: https://www.garant.ru/products/ipo/prime/doc/12088755/?ysclid=lzwus38h7k668781433 (дата обращения: 02.09.2024).
32. Основные направления бюджетной политики на 2013 год и плановый период 2014 и 2015 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_133448/769a44d734244dd3fac95f0 (дата обращения: 02.09.2024).
33. Основные направления бюджетной политики на 2014 год и плановый период 2015 и 2016 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_149516/d20f3d089b1720 (дата обращения: 02.09.2024).
34. Основные направления бюджетной политики на 2015 год и плановый период 2016 и 2017 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_165592/82ee8db30b (дата обращения: 02.09.2024).
35. Проект основных направлений бюджетной политики на 2016 год и плановый период 2017 и 2018 годов. Министерство финансов РФ. [Электронный ресурс]. URL: https://minfin.gov.ru/ru/document/?id_4=64713&ysclid=lzwvhyl369119778143 (дата обращения: 02.09.2024).
36. Основные направления бюджетной политики на 2017 год и плановый период 2018 и 2019 годов. Министерство финансов РФ. [Электронный ресурс]. URL: https://minfin.gov.ru/common/upload/library/2019/10/main/ONBP_2017-2019.pdf? (дата обращения: 02.09.2024).
37. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2018 год и плановый период 2019 и 2020 годов. Министерство финансов РФ. [Электронный ресурс]. URL: https://minfin.gov.ru/ru/document/?id_4=119695&ysclid=lzwvpk6kky2480045 (дата обращения: 02.09.2024).
38. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2019 год и плановый период 2020 и 2021 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_308390/61fbf3c1dbd (дата обращения: 02.09.2024).
39. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2020 год и плановый период 2021 и 2022 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_334706/257381c23 (дата обращения: 02.09.2024).
40. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2021 год и плановый период 2022 и 2023 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_364178/0bd48 (дата обращения: 02.09.2024).
41. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2022 год и плановый период 2023 и 2024 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_396691/bbd5875737 (дата обращения: 02.09.2024).
42. Основные направления бюджетной, налоговой и таможенно-тарифной политики на 2023 год и плановый период 2024 и 2025 годов. Информационная система «КонсультантПлюс». [Электронный ресурс]. URL: https://www.consultant.ru/document/cons_doc_LAW_429950/bbd5875737c9c8f4955275 (дата обращения: 02.09.2024).
Страница обновлена: 21.07.2026 в 14:57:32
Download PDF | Downloads: 54
Data pre-processing and post-processing for forecasting the revenues of the federal budget of the Russian Federation
Borisova O.V., Yashchenko A.I.Journal paper
Journal of Economics, Entrepreneurship and Law
Volume 14, Number 10 (October 2024)
Abstract:
Ever-changing macroeconomic conditions are driving government agencies and businesses to improve their forecasting systems. As a result, the requirements for data sets, their processing and the quality of selected models are increasing, which stimulates research in this direction.
The purpose of the article was to clarify the process of pre- and post-processing of data used for forecasting the revenues of the federal budget of the Russian Federation. The main problems faced by analysts in forecasting indicators and transformation procedures are considered. The process of data transformation before and after forecasting is presented. The main methods of data transformation are identified. The results of the study were applied to the process of forecasting the revenues of the federal budget of the Russian Federation, which allowed to obtain a qualitative forecasting model. Application of the proposed procedure will allow for timely processing of data to update the forecasting model.
The researches was carried out at the expense of budgetary funds under the Government (Public) R&D Contract of the Financial University under the Government of the Russian Federation.
Keywords: data pre-processing, data post-processing, federal budget revenues, forecasting, data analysis
Funding:
JEL-classification: J31, J32, J33, J38
References:
Batini C., Cappiello C., Francalanci C., Maurino A. (2009). Methodologies for data quality assessment and improvement ACM Computing Surveys. (41(3)). 1–52. doi: 10.1145/1541880.1541883.
Bessonov V.A., Petronevich A.V. (2013). Sezonnaya korrektirovka kak istochnik lozhnyh signalov [Seasonal adjustment as a source of spurious signals]. Ekonomicheskiy zhurnal vysshey shkoly ekonomiki. (4). 554 – 584. (in Russian).
Borisova O. V., Komissarova A. V. (2023). Modeli prognozirovaniya byudzhetnyh dokhodov v Rossii [Models for forecasting budget revenues in Russia]. Financial life. (3). 53-58. (in Russian).
Borisova O. V., Yaschenko A.I. (2023). Podkhod k prognozirovaniyu makroindikatorov v Rossii [An approach to forecasting macro indicators in Russia]. Management and Business Administration. (3). 75-83. (in Russian). doi: 10.33983/2075-1826-2023-3-75-83.
Ebin A., Sreekanth N., Sunil Kumar R.K., Nishanth T. (2021). Data Preprocessing Techniques for Handling Time Series data for Environmental Science Studies International Journal of Engineering Trends and Technology. 69 196 – 207.
Engl R.F., Grendzher K.U.Dzh. (2015). Kointegratsiya i korrektsiya oshibok:predstavlenie, otsenivanie i testirovanie [Co-integration and error correction: representation, estimation, and testing]. Prikladnaya ekonometrika. (3(39)). 106 – 135. (in Russian).
Fedotov D.Yu. (2017). Analiz prognozirovaniya nalogovyh dokhodov federalnogo byudzheta Rossii [An analysis of tax revenues forecasting of the Russian federal budget]. Finance and credit. (34(754)). 2016 – 2031. (in Russian).
Gubanov V.A. (2010). Sravnenie metodov sezonnoy korrektirovki vremennyh ryadov [Comparison of time series seasonal adjustment methods]. Scientific works Institute for Economics and Forecasting RAS. (8). 149 – 170. (in Russian).
Huang Y., Milani M., Chiang F. (2020). Privacy-aware data cleaning-as-a-service Information Systems. 1-30.
Kirchner K., Zec J., Delibasic B. (2016). Facilitating data preprocessing by a generic framework: a proposal for clustering Artificial Intelligence Review. 45 (3). 271–297.
Kopyrin A.S., Vidischeva E.V. (2020). Tekhnologii obrabotki i ochistki dannyh, vyyavleniya i ustraneniya shumov na vremennom ryadu [Technologies for processing and cleaning data, detecting and eliminating noise in the time series]. Vestnik Akademii znaniy. (4 (39)). 220 – 228. (in Russian).
Krishnan S., Franklin M.J., Goldberg K., Wang J., Wu E. (2016). ActiveClean: An Interactive Data Cleaning Framework For Modern Machine Learning Sigmod '16. 2117 – 2120.
Krishnan S., Wang J., Franklin M.J., Goldberg K., Kraska T., Milo T., Wu E.. (2015). Sampleclean: Fast and reliable analytics on dirty data IEEE Data Eng. Bull. (38(3)). 59–75.
Makarov A.V., Namiot D.E. (2023). Obzor metodov ochistki dannyh dlya mashinnogo obucheniya [Overview of data cleaning methods for machine learning]. International Journal of Open Information Technologies. (10). 70 – 78. (in Russian).
Mustafina D.A., Burakova A.E., Mustafin A.I., Aleksandrova A.S. (2018). Obobshchennaya mnogomernaya interpolyatsiya metodom naimenshikh kvadratov [Generalized multivariate interpolation through the least-square method]. Vestnik PNIPU. Elektrotekhnika, informatsionnye tekhnologii, sistemy upravleniya. (27). 30 – 48. (in Russian).
Nwagwu H.C., Okereke G., Nwobodo C. (2017). Mining and visualising contradictory data J Big Data 4. (36). 1 – 11.
Orudzhev E.G-O, Guseynova S.M-G. (2020). Kointegratsionnyy analiz vzaimovliyaniya VVP Azerbaydzhana, Rossii, Belarusi i Kazakhstana [The cointegration analysis of the interrelation between the gdp of Azerbaijan, Russia, Belarus and Kazakhstan]. Bulletin of the Saint Petersburg State University of Economics. (4 (124)). 31 – 40. (in Russian).
Osmolovskaya-Suslina A.L., Borisova S.R. (2022). Dokhody regionalnyh byudzhetov v nachale 2022 g.: osnovnye tendentsii i faktory riska [Regional budget revenues in early 2022: key trends and risk factors]. The Journal of Finance. (6). 25 – 43. (in Russian).
Petrushin V. N., Rytikov G. O. (2014). Formalizatsiya vremennogo ryada metodom dvoynogo sglazhivaniya [Double smoothing in time series formalization]. Cloud of Science. (2). 230 – 238. (in Russian).
Pilnik N.P., Pospelov I.G., Stankevich I.P. (2015). Ob ispolzovanii fiktivnyh peremennyh dlya resheniya problemy sezonnosti v modelyakh obshchego ekonomicheskogo ravnovesiya [On the use of dummy variables to solve the problem of seasonality in general equilibrium models]. Economic Journal. (2). 249 – 270. (in Russian).
Ryzhenkova K. V. (2012). Metody vosstanovleniya propuska dannyh pri provedenii statisticheskikh issledovaniy [Data omission recovery methods in statistical research]. Intelligence. Innovation. Investments. (3). 127 – 133. (in Russian).
Serysheva I.A. (2018). Filtratsiya vybrosov v zadachakh staticheskoy i dinamicheskoy obrabotki dannyh v etalonakh vremeni i chastoty [Outlier filtration in problems of static and dynamic data processing in time and frequency standards]. Bulletin of the Irkutsk State Technical University. (10 (141)). 67 – 77. (in Russian).
Shashenko A.N., Maslennikov S.E., Erokhondina T.A. (2001). Privedenie nestatsionarnyh protsessov k statsionarnomu vidu pri analize proizvodstvenno-khozyaystvennoy deyatelnosti ugledobyvayushchikh predpriyatiy [Bringing non-stationary processes to a stationary form in the analysis of production and economic activities of coal mining enterprises]. Gornyy informatsionno-analiticheskiy byulleten. (11). 1-4. (in Russian).
Sorokin A.A., Borodyanskiy I.M., Dagaev A.V. (2020). Sravnitelnyy analiz metodov vosstanovleniya propushchennyh danny [Comparative analysis of missing data recovery methods]. IZVESTIYA SFedU. ENGINEERING SCIENCES. (4(214)). 93 – 107. (in Russian).
Staroverova K.Yu., Bure V.M. (2017). Mera razlichiya vremennyh ryadov, osnovannaya na ikh kharakteristikakh [Characteristics based dissimilarity measure for time series]. Vestnik SPbGU. Seriya 10. Prikladnaya matematika. Informatika. Protsessy upravleniya. (1). 51 – 60. (in Russian).
Suvorov N.V., Balashova E.E. (2009). Modelnyy instrumentariy prognozno-analiticheskikh issledovaniy dinamiki mezhotraslevyh svyazey otechestvennoy ekonomiki [A modeling toolkit for predictive ananlytical studies of the dynamics of interindustry relations in the domestic economy]. Problems of forecasting. (6). 16 – 33. (in Russian).
Sysoeva M.V., Dikanev T.V., Sysoev I.V. (2012). Vybor vremennyh masshtabov pri postroenii empiricheskoy modeli [Selecting time scales for empirical model construction]. Izvestiya vysshikh uchebnyh zavedeniy. Prikladnaya nelineynaya dinamika. (2). 54-62. (in Russian). doi: 10.18500/0869-6632-2012-20-2-54-62.
Tawakuli A., Havers B., Gulisano V., Kaiser D., Engel T. (2024). Survey:Time-series data preprocessing: A survey and an empirical analysis Journal of Engineering Research. (1). 38.