«Искусственный интеллект» глазами студентов и преподавателей: асимметрия восприятия и пути ее преодоления
Зимовец А.В.1 ![]() , Кошман В.В.1
, Кошман В.В.1 ![]() , Маринова И.В.1
, Маринова И.В.1 ![]()
1 Таганрогский институт управления и экономики, Таганрог, Россия
Скачать PDF | Загрузок: 11
Статья в журнале
Вопросы инновационной экономики (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 16, Номер 2 (Апрель-июнь 2026)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=91795988
Аннотация:
Стремительное развитие и последующая экспансия генеративных нейросетевых технологий в высшее образование создает парадоксальную ситуацию: с одной стороны, большие языковые модели стали повседневным инструментом для подавляющего большинства студентов, с другой – их применение остается стихийным, нерегламентированным и вызывает неприятие у значительной части преподавателей. Цель настоящего исследования заключается в выявлении и анализе ключевых проявлений асимметрии восприятия этих технологий основными участниками образовательного процесса. На основе проведенного авторами исследования анкетирования (февраль-март 2026 г.) было установлено, что данная асимметрия носит системный многомерный характер и проявляется на функциональном, ценностном и институциональном уровнях. Выявлено, что студенты воспринимают искусственный интеллект как способ оптимизации учебной рутины, преподаватели же, воспринимают его как угрозу академической добросовестности. Ключевым барьером для конструктивной интеграции технологий «искусственного интеллекта» в образовательный процесс выступает дефицит четких институциональных механизмов, регламентирующих его использование в образовательном процессе, при том что обе группы анкетируемых, в целом поддержали идею обучения цифровой грамотности.
По результатам исследования, авторами обоснована необходимость перехода от запретительных стратегий использования нейросетевых технологий в образовательном процессе и необходимости перехода к его регламентации и трансформации оценочных средств
Ключевые слова: «искусственный интеллект» в образовании, нейросетевые технологии, большие языковые модели, асимметрия восприятия, академическая честность, цифровая трансформация образования, институциональное регулирование
JEL-классификация: I20, I23, O33, C80, K24
1. Введение
Актуальность исследования. Стремительное проникновение технологий так называемого «искусственного интеллекта» во все сферы общественной жизни, серьёзным образом трансформировало и сферу образования. Генеративные нейросетевые ассистенты (такие как ChatGPT, YandexGPT, GigaChat, DeepSeek и т.д.) – став сегодня ежедневно используемым инструментом, кардинально изменили учебную и научную деятельность обучающихся. Масштаб распространения нейросетевых технологий впечатляет: по наблюдениям авторов, не менее 70-80% обучающихся вузов регулярно применяют большие языковые модели для поиска информации при выполнении заданий и подготовки к семинарам и экзаменам, в т.ч. при написании контрольных и курсовых работ, а так же дипломов и диссертаций. Среди преподавателей доля активных пользователей «искусственного интеллекта» пока еще ниже, но их доля тоже растёт.
К сожалению, такое проникновение современных технологий в научную и учебную деятельность представляет собой серьезную проблему: в образовательной среде формируется выраженная асимметрия восприятия технологий «искусственного интеллекта» обучающимися и педагогами. Преподаватели, преимущественно, рассматривают нейросети инструмент снижающий когнитивную активность обучающихся, представляющий к тому же серьёзную угрозу академической честности и порядочности. Студенты же, наоборот, воспринимают нейросети как удобный вспомогательный инструмент, позволяющий оптимизировать выполнение рутинных задач, однако при этом нередко демонстрируют отсутствие критического восприятия к генерируемому контенту и снижение способностей к самостоятельному анализу.
Указанная асимметрия проявляется на нескольких уровнях: функциональном (преподаватели фокусируются на рисках, студенты – на преимуществах), когнитивном (разная оценка влияния ИИ на мыслительные процессы) и институциональном (отсутствуют единые нормы и правила применения нейросетевых технологий). В результате возникает парадоксальная ситуация: с одной стороны, технологии «искусственного интеллекта» де-факто уже стали неотъемлемой частью образовательной среды, а с другой – их использование носит стихийный, нерегламентированный характер, что создаёт риски как для качества образования, так и для формирования профессиональных знаний и навыков будущих специалистов.
В соответствие с вышесказанными, авторами при проведении исследования была поставлена цель выявить и проанализировать ключевые проявления асимметрии восприятия нейросетевых технологий преподавателями и студентами высших учебных заведений.
Теоретическую основу исследования составили работы, раскрывающие различные грани цифровой трансформации образования и экономики. В частности, исследование опирается на анализ динамики и структуры использования цифровых технологий, проведённый А. В. Зимовец и О. А. Синиченко [3]; на обоснование необходимости новых подходов к кадровому менеджменту и коррекции образовательной системы в условиях цифровизации, представленное Е. В. Дробот, И. Н. Макаровым, Д. С. Казаровой и др. [9]; на моделирование кризиса труда с учётом технологических сдвигов, выполненное Т. В. Петренко [11]; на анализ эффективности цифровых SaaS-сервисов, предложенный М. Е. Путивцевым [12]; на исследование роли электронных учебно-методических комплексов М. А. Штанько и Т. А. Забировой [16]; а также на труды И. А. Янкиной, посвящённые оценке конкурентоспособности вуза в цифровую эпоху и роли образования в процессе цифровизации [18, 19]. Указанные научные публикации заложили методологическую базу для выявления и анализа асимметрии восприятия нейросетевых технологий в высшей школе.
При проведении исследования, авторами была выдвинута гипотеза о том, что асимметрия восприятия технологий «искусственного интеллекта» преподавателями и студентами носит системный, многомерный характер, проявляясь одновременно на трёх уровнях: функциональном, когнитивном и институциональном. При этом ключевым барьером на пути конструктивной интеграции «искусственного интеллекта» в образовательный процесс выступает не столько само сопротивление технологиям, сколько дефицит институциональных механизмов, обеспечивающих баланс между инновационным потенциалом нейросетей и необходимостью сохранения фундаментальных образовательных ценностей – академической честности, критического мышления и самостоятельности познавательной деятельности.
2. О сути «искусственного интеллекта»
Анализ перспектив и рисков внедрения нейросетевых технологий в образовательный процесс требует строгой терминологической определённости. В средствах массовой информации понятия «искусственный интеллект», «нейронные сети» и «машинное обучение» нередко используются как взаимозаменяемые, что порождает концептуальную путаницу и затрудняет содержательный анализ. Между тем указанные выше термины образуют чёткую иерархическую структуру, отражающую архитектуру современных интеллектуальных систем.
Под термином «искусственный интеллект», представляющим собой наиболее широкое понятие из указанных выше, в России понимается «комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые с результатами интеллектуальной деятельности человека или превосходящие их» [1]. «Машинное обучение» является подобластью «искусственного интеллекта», и его суть заключается в том, чтобы обучить систему самостоятельно находить закономерности в данных, не прибегая к жёсткому программированию правил [5]. И если классический «искусственный интеллект» может опираться на заранее заданные экспертные правила, то системы машинного обучения извлекают знания из получаемого ими «опыта» (т.е. из обработанных ими массивов данных).
В свою очередь, «нейронные сети» представляют собой лишь один из методов машинного обучения, архитектура которого частично копирует строение биологических нейронных сетей. Искусственный нейрон представляет собой математическую функцию, которая принимает входные сигналы, обрабатывает их и передаёт результат следующим нейронам. Слоистая структура таких сетей позволяет моделировать сложные нелинейные зависимости [10].
Наконец, «большие языковые модели» представляют собой тип нейросетей глубокого обучения, специализированных на понимании и генерации текста на естественном языке. Большие языковые модели представляют собой нейросети с миллиардами параметров, обученные на огромных массивах текстовых данных. Именно к этому классу относятся широко известные системы, с которыми взаимодействуют студенты – GPT, YandexGPT, GigaChat, DeepSeek и др.
Таким образом, иерархию понятий можно отобразить в виде схемы, представленной на рисунке 1. на котором каждый последующий уровень представляет собой более специализированную реализацию предыдущего.
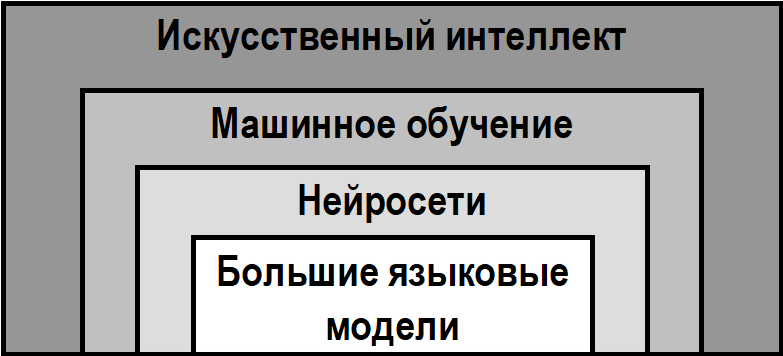
Рис.1. – Иерархия современных интеллектуальных систем (Источник: составлено авторами)
Достаточно важным для целей проведенного авторами исследования явилось сопоставление возможностей «искусственного интеллекта» с характеристиками естественного (человеческого) интеллекта. В кибернетике для обозначения последнего используется термин «естественный автомат», под которым понимается нервная система, а также самовоспроизводящиеся и самоисправляющиеся биологические системы в эволюционном и адаптивном аспекте [15]. Сравнительный анализ двух типов интеллекта, отображенная в таблице 1 позволяет выявить как фундаментальные различия в их организации, так и ограничения, присущие современным системам «искусственного интеллекта», что критически важно для понимания границ их применимости в образовании.
Таблица 1. – «Сравнительная характеристика естественного и искусственного интеллекта» (Источник: составлено авторами по: [14])
|
Параметр сравнения
|
Естественный интеллект (человек)
|
Искусственный интеллект (LLM)
|
|
Энергопотребление
|
Порядка
12-20 Вт (мощность тусклой лампочки)
|
Мегаватты
на уровне дата-центра; один запрос требует в 10-50 раз больше энергии, чем
поиск в Google
|
|
Структурные
элементы
|
Порядка
86-128 млрд нейронов; 100–500 трлн синапсов
|
GPT-4:
около1,8 трлн параметров;
Llama 3: 100 млрд параметров |
|
Объём
обучающих данных
|
Ребёнок
овладевает языком на основе порядка 100 млн слов
|
Порядка
триллионов токенов (эквивалент десятков тысяч лет непрерывного чтения
человеком)
|
|
Активный
словарь
|
10-50
тыс. слов (активный); пассивный – до 100 тыс.
|
Сотни
тысяч токенов в контекстном окне (GPT-4: до 128 тыс.)
|
|
Скорость
обработки
|
Порядка
100-200 мс на простую когнитивную операцию; параллельная архитектура
|
Миллисекунды
на генерацию ответа; последовательно-параллельная архитектура
|
|
Способность
к обобщению
|
Высокая;
способность к переносу знаний в принципиально новый контекст; интуиция
|
Ограничена
распределением обучающих данных; склонность к «галлюцинациям» за пределами
известного
|
|
Память
|
Ассоциативная,
реконструктивная, подвержена искажениям
|
Точное
воспроизведение в пределах контекстного окна; за его пределами –
вероятностная реконструкция
|
|
Креативность
|
Подлинная
новизна, инсайт, способность к парадоксальному мышлению
|
Комбинаторная
рекомбинация известных паттернов
|
|
Эмоциональный
интеллект
|
Врождённая
способность к эмпатии, распознаванию и модуляции эмоций
|
Имитация
эмоциональных реакций на основе статистических закономерностей текста
|
|
Непрерывное
обучение
|
Способность
к обучению в течение всей жизни без катастрофического забывания
|
Требует
дискретных циклов дообучения; подвержен катастрофическому забыванию
|
|
Режим
работы
|
Преимущественно
параллельная обработка сигналов
|
Преимущественно
последовательная (трансформерная архитектура с параллельными вычислениями)
обработка сигналов
|
|
Объяснимость
решений
|
Ограниченная;
многие когнитивные процессы неосознаваемы
|
Полная
прозрачность вычислительного графа, но смысловая непрозрачность («чёрный
ящик»)
|
Обозначенные выше различия имеют прямое отношение к проблематике внедрения технологий «искусственного интеллекта» в образование. Понимание того, что нейросеть – не «мыслящий субъект», а сложный инструмент, функционирующий по принципам, кардинально отличающимся от человеческого мышления, является весьма объективной и важной предпосылкой для формирования у студентов критического отношения к генерируемому большими языковыми моделями контенту и осознанного, рационального использования инструментов «искусственного интеллекта» в образовательном процессе.
3. Развитие нейросетевых технологий от перцептрона к мультимодальным агентам
История развития технологий, приведших к созданию современных больших языковых моделей, представляет собой последовательную смену парадигм – от первых теоретических построений до систем, способных генерировать тексты, аналогичные человеческим. В эволюции больших языковых моделей принято выделять несколько этапов, каждый из которых характеризуется появлением принципиально-новых технологий работы с данными.
Теоретический фундамент нейросетевого подхода был заложен в 1943 году, когда американские нейрофизиологи Уоррен Мак-Каллок и Уолтер Питтс опубликовали работу «Логическое исчисление идей, относящихся к нервной активности» [22], в которой впервые была представлена математическая модель искусственного нейрона как простейшего вычислительного элемента, способного находиться в одном из двух состояний и реагировать на входные сигналы по бинарному принципу. Эта модель, в дальнейшем получившая название «формальный нейрон Мак-Каллока–Питтса», до сих пор остаётся базовым строительным блоком всех искусственных нейронных сетей. Исследователи показали, что сети из таких элементов способны выполнять любые вычислимые логические функции, что стало первым строгим доказательством принципиальной возможности моделирования мыслительных процессов с помощью вычислительных устройств.
В 1949 году канадский нейропсихолог Дональд Хебб сформулировал первый принцип обучения нейронных сетей, известный как «правило Хебба». Согласно этому правилу, синаптическая связь между двумя нейронами усиливается, если они часто активируются одновременно. Хебб выразил эту закономерность лаконичной фразой: «Neurons that fire together, wire together» («взаимодействующие клетки – объединяются») [20]. Хотя правило Хебба описывало биологические нейронные сети, оно оказало огромное влияние и на разработку алгоритмов обучения искусственных нейросетей, став концептуальной основой для последующих моделей ассоциативной памяти и неконтролируемого обучения.
В 1950 году Алан Тьюринг опубликовал программную статью «Вычислительные машины и разум» [24], в которой сформулировал знаменитый вопрос: «Могут ли машины мыслить?». Для ответа на него Тьюринг предложил эмпирический критерий, получивший в последующем название «тест Тьюринга». Суть теста заключается в том, что если в ходе текстового диалога, человек не может отличить машину от другого человека, то такую машину следует признать мыслящей. Этот концептуальный эксперимент на десятилетия вперёд определил направление развития искусственного интеллекта, задав чёткий, хотя и дискуссионный, критерий оценки его успешности.
Ключевым событием, оформившим искусственный интеллект как самостоятельную научную дисциплину, стал Дартмутский семинар 1956 года, организованный Джоном Маккарти. Именно там Маккарти впервые ввёл в научный оборот термин «искусственный интеллект» [4].
В 1957 году американский психолог Фрэнк Розенблатт разработал первую практически реализуемую искусственную нейронную сеть – перцептрон, а в 1958 году создал его аппаратную реализацию в виде первого в мире нейрокомпьютера «Марк-1» [23]. Перцептрон представлял собой однослойную нейронную сеть, способную обучаться распознаванию простых зрительных образов. Устройство моделировало работу сетчатки глаза и могло, например, различать буквы алфавита, хотя и было чувствительно к вариациям их написания. Розенблатт с большим энтузиазмом предсказывал, что его изобретение в будущем сможет «научиться ходить, говорить, читать и писать». Работы Розенблатта вызвали огромный резонанс в научном сообществе и стимулировали широкий интерес к нейросетевому подходу.
Чуть позже, период эйфории по поводу развития нейронных сетей сменился скептицизмом, особенно после публикации в 1969 году книги Марвина Минского и Сеймура Пейперта «Перцептроны» [8]. Авторы математически доказали, что однослойный перцептрон неспособен решать задачи, требующие нелинейной разделимости классов, включая, казалось бы, тривиальную функцию «исключающее ИЛИ» (XOR). Критика Минского, пользовавшегося огромным научным авторитетом, привела к резкому сокращению финансирования нейросетевых исследований и наступлению так называемой «зимы искусственного интеллекта», продлившейся более десятилетия.
Серьезное возрождение интереса к нейросетям началось в 1982 году, когда американский физик Джон Хопфилд предложил модель рекуррентной нейронной сети с обратными связями, способной функционировать как ассоциативная память [21]. Сеть Хопфилда демонстрировала способность восстанавливать полный образ по его фрагменту или искажённой версии, что открывало новые перспективы для решения задач распознавания и кластеризации.
Ключевым технологическим драйвером, определившим переход к современной эре «искусственного интеллекта», стало появление графических процессоров с массивной параллельной архитектурой, идеально подходящей для вычислений, лежащих в основе нейросетевых алгоритмов. В сочетании с накоплением огромных массивов «больших данных», это создало материальную базу для практической реализации идей глубокого обучения, сформулированных ещё в 1980-х годах.
Началом «революции глубокого обучения», после которой нейросетевые технологии начали стремительно проникать во все сферы – от медицинской диагностики до автономного вождения, стала победа в 2012 году команда под руководством Алекса Крижевского и Джеффри Хинтона в конкурсе компьютерного зрения ImageNet, которые использовали глубокую свёрточную нейронную сеть AlexNet, снизившую ошибку распознавания изображений почти вдвое по сравнению с традиционными методами компьютерного зрения. А следующий качественный скачок в развитии «искусственного интеллекта» произошёл в 2017 году, когда исследователи Google опубликовали статью «Attention Is All You Need»? [17] представив архитектуру «трансформера», который в отличие от предшествовавших рекуррентных нейронных сетей, обрабатывавших текст последовательно, использовал механизм внимания, позволяющий параллельно анализировать взаимосвязи между всеми элементами входной последовательности. Именно эта архитектура легла в основу генеративных предобученных трансформеров (GPT) и всех современных больших языковых моделей.
Наконец, в ноябре 2022 года компания OpenAI представила ChatGPT – диалогового агента на основе архитектуры GPT, способного генерировать связные и осмысленные тексты, отвечать на сложные вопросы, писать программный код и решать творческие задачи. Масштаб общественного резонанса превзошёл все ожидания: ChatGPT стал самым быстрорастущим потребительским приложением в истории, набрав 100 миллионов пользователей всего за два месяца. Вслед за OpenAI собственные большие языковые модели представили практически все ведущие технологические компании мира.
Сегодня ландшафт генеративных систем непрерывно расширяется. Наряду с американскими моделями (GPT-4, Claude, Gemini) активно развиваются китайские разработки (DeepSeek, Qwen) и российские решения – YandexGPT, GigaChat и другие. Темпы прогресса впечатляют: если первые перцептроны 1950-х годов с трудом различали несколько десятков образов, то современные мультимодальные системы способны анализировать и генерировать не только текст, но и изображения, видео, аудио и программный код, приближаясь по своим возможностям к универсальным когнитивным инструментам человека.
4. «Искусственный интеллект» в современном образовательном процессе
Сегодня образовательный процесс, под влиянием стремительного распространения генеративных нейросетевых систем, переживает беспрецедентную трансформацию. То, что ещё несколько лет назад воспринималось как экспериментальная технология [6], сегодня стало повседневным инструментом академической деятельности: по данным эмпирических исследований 2025 года, более 90 % студентов активно используют ChatGPT и аналогичные сервисы в учебных целях [7]. Однако инструментарий современного студента не исчерпывается одним лишь ChatGPT – он включает в себя целую экосистему специализированных и универсальных решений, построенных на технологиях «искусственного интеллекта», каждое из которых обладает уникальными возможностями и ограничениями.
Пожалуй, наиболее первостепенное значение в образовательном процессе современного студенчества занимают большие языковые модели общего назначения. ChatGPT от OpenAI остаётся наиболее узнаваемым представителем этого класса, однако в российском образовательном контексте всё более значимую роль играют отечественные и доступные без ограничений альтернативы. YandexGPT – нейросеть семейства GPT от компании «Яндекс» – отличается глубокой адаптацией к русскому языку и культурному контексту, и способна обрабатывать до нескольких десятков тысяч слов одновременно, генерировать тексты различных жанров, анализировать документы, выделять ключевые идеи и т.д. В рамках пилотного проекта Яндекса и НИУ ВШЭ студенты успешно применяли YandexGPT при написании курсовых и дипломных работ для сбора и обобщения информации, проверки текстов на ошибки и оформления [13]. Не менее интересен по своему функционалу китайский проект DeepSeek – китайская мультимодальная нейросеть, ставшая доступной в России с 2025 года, и предполагающая на бесплатной основе и без установленных лимитов как функции построения логических рассуждений и генерации генерация кода, так и функции поиска актуальной информации в Интернете со ссылками на источники.
Для углублённой исследовательской работы сегодняшним студентам доступны инструменты, выходящие за рамки обычных чат-ботов. Так, например, Perplexity AI – поисковая система построенная на базе больших языковых моделей, специально оптимизирована для академического поиска: функция Pro Search синтезирует информацию из десятков источников, включая научные статьи, журналы и базы данных, а режим Academic фокусирует поиск исключительно на рецензируемых публикациях.
Отдельный сегмент инструментального ландшафта современного студента образуют нейросетевые сервисы для создания презентаций. Так, например, Gamma AI генерирует презентации, документы и веб-страницы по текстовому описанию за секунды, предлагая структурированный план и визуальное оформление слайдов. Presentsimple и Slider AI – российские генераторы презентаций, создающие текстовые слайды, диаграммы и 3D-модели на русском языке. MagicSlides интегрируется непосредственно в Google Slides, позволяя генерировать полноценные презентации за минуту. Важно подчеркнуть: все перечисленные сервисы требуют критической проверки сгенерированного контента – нейросети могут подбирать неподходящие изображения, допускать фактические ошибки и путаться в логической структуре материала.
Следует отметить, что нейросетевые технологии трансформируют не только студенческую, но и преподавательскую деятельность, освобождая педагогов от рутинных операций и открывая новые возможности для индивидуализации обучения. «Искусственный интеллект» освобождает педагога от проверки стандартных домашних заданий, позволяя сосредоточиться на индивидуальной работе с учащимися. Так, в частности, совсем недавно компания «Яндекс» запустила линейку специализированных помощников на базе «искусственного интеллекта» YandexGPT для преподавателей. В рамкаха названного проекта, инструмент «Нейроквизы» позволяет создавать проверочные тесты за несколько минут: достаточно загрузить учебные материалы, и нейросеть сгенерирует вопросы и варианты ответов, включая верные и неверные. «Нейродетектор» анализирует текст и определяет степень его уникальности – написан ли он человеком или сгенерирован нейросетью, подсвечивая фрагменты, которые с высокой вероятностью созданы «искусственным интеллектом», а такие решения, как Gradescope, позволяют преподавателям вузов быстро оценивать тысячи студенческих работ, получая детальную аналитику по типичным ошибкам в группе.
Однако стоит отметить, что при всех впечатляющих возможностях нейросетевых инструментов их применение сопряжено с фундаментальным ограничением – феноменом галлюцинаций «искусственного интеллекта» – ситуаций, при которых система генерирует информацию, которая кажется правдоподобной, но на самом деле является ложной или не имеет под собой реальных оснований. Экспериментальные данные показывают, что процент ошибок «искусственного интеллекта» в сложных вопросах может достигать 40-50 %. Некритичное восприятие обучающимися генерируемого с помощью «искусственного интеллекта» контента создаёт риски, выходящие далеко за пределы академической неуспеваемости: формируется «иллюзия знания», когда быстрая генерация ответов создаёт ощущение компетентности, не гарантируя достоверности информации. Именно поэтому ключевой задачей современного образования становится не запрет нейросетей, а формирование у студентов навыков проверки получаемой информации и цифровой гигиены – способности сомневаться, искать подтверждения в авторитетных источниках, сопоставлять данные из разных систем.
5. Анализ использования технологий «искусственного интеллекта» в образовательном процессе: асимметрия восприятия преподавателей и студентов
Представленные выше теоретические положения и обзор инструментов обуславливают необходимость эмпирической верификации выдвинутой гипотезы об асимметрии восприятия технологии «искусственного интеллекта» обучающимися и преподавателями. Для получения сопоставимых данных в феврале-марте 2026 года, авторами исследования было проведено параллельное анкетирование двух референтных групп: 188 студентов различных уровней подготовки (бакалавриат, магистратура, аспирантура, а также учащиеся колледжей) и различных вузов юга России и 62-х преподавателей высших учебных заведений. Анкеты содержали как совпадающие по смысловому наполнению, так и специфические для каждой группы вопросы, что позволило выявить точки максимального расхождения в позициях интервьюируемых групп. Ниже представлен сравнительный анализ полученных результатов, структурированный по ключевым параметрам проявления асимметрии.
![]() Итак, данные анкетирования фиксируют существенный разрыв в
интенсивности применения нейросетей (рис.2.).
Итак, данные анкетирования фиксируют существенный разрыв в
интенсивности применения нейросетей (рис.2.).
Рис.2. – Ответы инревьюируемых на вопрос «Как часто вы используете нейросети в своей профессиональной / учебной деятельности?» (источник: составлено авторами по результатам анкетирования)
Среди студентов 26,6 % обращаются за помощью к «искусственному интеллекту» «по несколько раз в день», ещё 44,7 % – «2-3 раза в неделю». Таким образом, регулярными пользователями являются более 71 % обучающихся, тогда как никогда не использовали технологии «искусственного интеллекта» лишь 8,5 % интервьюируемых. В группе преподавателей картина принципиально иная: ежедневно нейросети применяют лишь 21 %, несколько раз в неделю – 35,5 %, а 14,5 % не используют их совсем. Даже с поправкой на разный характер профессиональной деятельности очевидно, что для подавляющего большинства студентов технологии «искусственного интеллекта» уже является привычным рабочим инструментом, встроенным в повседневные академические практики, тогда как среди преподавателей сохраняется значительная доля «цифровых скептиков».
Ещё более показательна асимметрия в целевых установках (рис.3.).
![]()
Рис.3. – Ответы инревьюируемых на вопрос «Для каких задач вы чаще всего применяете «искусственный интеллект»? (множественный ответ)» (источник: составлено авторами по результатам анкетирования)
Студенческий рейтинг возглавляет «поиск и анализ данных» (42,6 %), за которым следует «написание эссе, рефератов, курсовых, дипломов» (30,9 %). Иными словами, «искусственный интеллект» используется прежде всего как средство оптимизации учебной рутины. Преподаватели же чаще всего применяют нейросети для «генерации заданий и примеров», «составления тестов и экзаменационных заданий» и «написания научных статей / обзоров литературы». Примечательно, что 12 преподавателей указали целью «проверку студенческих работ на нейросетевой стиль» – функция, не имеющая аналога в студенческой анкете и явно отражающая контролирующую, а не созидательную мотивацию. Эта функциональная асимметрия – «`искусственный интеллект` для выполнения задания» и ««`искусственный интеллект` для проверки выполненного» – закладывает фундамент для взаимного недоверия и разнонаправленных ожиданий среди интервьюируемых групп.
Следует отметить, что наиболее контрастные результаты получены в блоке, затрагивающем этические аспекты и оценку рисков (рис.4.).
![]()
Рис.4. – Ответы преподавателей на вопрос «Как вы оцениваете риск «академического мошенничества» в вашем вузе прямо сейчас?» (источник: составлено авторами по результатам анкетирования)
Судя по ответам, преподаватели демонстрируют высокий уровень тревожности из-за развития нейросетевых технологий: на вопрос о риске академического мошенничества по шкале от 1 до 5 средневзвешенная оценка составила 3,6 балла, при этом 46,8 % респондентов поставили оценку «4» или «5», а лишь 1 преподаватель счёл проблему отсутствующей. Категоричное неприятие генерации студенческих работ без доработки (рис.5.) выразили 69,4 % педагогов (43 из 62), тогда как ни один не согласился с тезисом «это инструмент как калькулятор».
![]()
Рис.5. – Ответы преподавателей на вопрос «Считаете ли вы этичным для студента сдавать курсовую / реферат, полностью написанные нейросетью без доработки?» (источник: составлено авторами по результатам анкетирования)
Студенческое же мнение диаметрально противоположно (рис.6.).
![]()
Рис.6. – Ответы студентов на вопрос «Испытываете ли вы чувство вины или страх, когда сдаете работу, сделанную с помощью «искусственного интеллекта»?» (источник: составлено авторами по результатам анкетирования)
73,4 % не испытывают чувства вины при сдаче работ, выполненных с помощью «искусственного интеллекта», расценивая нейросеть как «обычный инструмент». Данный разрыв – между преподавательской установкой на контроль и студенческой на инструментальность – формируют основную ценностную ось асимметрии: педагоги воспринимают «искусственного интеллекта» как угрозу академической честности, в то время как студенты воспринимают его средство адаптации к растущей учебной нагрузке.
Примечательно, что по вопросу о желательности специального обучения обе группы демонстрируют конвергенцию (рис.7 и 8.) – 87,1 % преподавателей видят пользу в формировании у студентов навыков промптинга, называя это «новой цифровой грамотностью», а 66 % студентов хотели бы, чтобы вуз ввёл спецкурс «Эффективное использование ИИ».
![]()
![]() Рис.7.
– Ответы преподавателей на вопрос «Видите ли вы пользу в том, чтобы научить
студентов правильно формулировать запросы (промптинг) для «искусственного
интеллекта»?» (источник: составлено авторами по результатам анкетирования)
Рис.7.
– Ответы преподавателей на вопрос «Видите ли вы пользу в том, чтобы научить
студентов правильно формулировать запросы (промптинг) для «искусственного
интеллекта»?» (источник: составлено авторами по результатам анкетирования)
Рис.8. – Ответы студентов на вопрос «Хотели бы вы, чтобы в вузе велся спецкурс «Эффективное использование «искусственного интеллекта»?» (источник: составлено авторами по результатам анкетирования)
Однако за этим внешним согласием скрывается различие в мотивах: студенты ожидают от такого курса «преимущества в работе» (именно этот вариант ответа выбрали 66% респондентов), тогда как преподавательский запрос продиктован скорее стремлением снизить риски некорректного использования современных технологий.
Расхождение обнаруживается и в отношении к формальным институциональным рамкам (рис.9. и рис.10.).
![]()
![]() Рис.9.
– Ответы преподавателей на вопрос «Видите ли вы пользу в том, чтобы научить
студентов правильно формулировать запросы (промптинг) для «искусственного
интеллекта»?» (источник: составлено авторами по результатам анкетирования)
Рис.9.
– Ответы преподавателей на вопрос «Видите ли вы пользу в том, чтобы научить
студентов правильно формулировать запросы (промптинг) для «искусственного
интеллекта»?» (источник: составлено авторами по результатам анкетирования)
Рис.10. – Ответы студентов на вопрос «Хотели бы вы, чтобы в вузе велся спецкурс «Эффективное использование «искусственного интеллекта»«?» (источник: составлено авторами по результатам анкетирования)
Среди преподавателей 38,7 % считают, что вуз нуждается в специальном локальном акте об использовании «искусственного интеллекта», тогда как 51,6 % полагают достаточными общие правила этики. Студенты же, отвечая на близкий по смыслу вопрос о введении «отчёта о проделанной работе с «искусственным интеллектом»«, в 53,2 % случаев поддерживают такую практику как «честную», и лишь 21,3 % воспринимают её как лишнюю бюрократию. Иными словами, студенты в целом лояльнее к прозрачным «правилам игры», нежели к тотальным запретам, тогда как преподаватели колеблются между формальным регулированием и этическим самоограничением.
Для адекватной интерпретации выявленных асимметрий необходимо поместить их в более широкий контекст. На рисунке 11 представлено соотношение теоретически возможного и фактически наблюдаемого уровней вовлечённости больших языковых моделей в решение прикладных задач по профессиональным категориям.
![]()
Рис.11. – Перспективы использования нейросетевых технологий в различных сферах деятельности (источник: составлено авторами по данным ARK Invest [2])
Для сферы «Образование и библиотечное дело» теоретический максимум автоматизации составляет 0,61, тогда как текущий уровень – лишь 0,20. Разрыв в 0,41 пункта – один из самых значительных среди всех представленных категорий – свидетельствует о масштабном недоиспользовании потенциала «искусственного интеллекта» именно в образовательной среде, что коррелирует с полученными авторами данными: преподаватели демонстрируют умеренную вовлечённость и высокий уровень опасений, что тормозит диффузию технологий в образовательный процесс.
Ещё более выразительны данные отображенные на рисунке 12, иллюстрирующие экспоненциальный рост объёмов текста, генерируемого «искусственным интеллектом»: если на протяжении столетий совокупный объём написанных человечеством слов увеличивался постепенно, достигнув к 2000 году примерно 4 трлн слов, то с 2020 года кривая генерации «искусственного интеллекта» уходит в почти вертикальный взлёт: 50 трлн слов в 2020 году, прогнозные 120 трлн к 2030 году.
![]()
Рис.12. – Темпы генерации текстов человечеством и «искусственным интеллектом» (источник: составлено авторами по данным ARK Invest [2])
Человеческая текстовая «продукция» на этом фоне стагнирует на уровне 11-15 трлн слов. Отображенные на графике данные имеют прямое отношение к образовательной асимметрии: студенты, взрослеющие в мире, в котором большая часть текстового контента производится машинами, неизбежно формируют инструментальное отношение к «искусственному интеллекту» как к естественному элементу информационной среды. Преподаватели же, чей профессиональный опыт сформировался в «доэкспоненциальную» эпоху, склонны негативно оценивать новые реалии, рассматривая их сквозь призму традиционных академических норм.
Совокупность приведённых данных позволяет утверждать, что асимметрия восприятия технологий «искусственного интеллекта» не является ситуативным феноменом, но имеет системную природу. Во-первых, она порождена фундаментальным различием ролей: студент выступает в образовательном процессе как исполнитель, для которого «искусственный интеллект» является средством оптимизации затрат времени; преподаватель – как контролёр, для которого экспансия «искусственного интеллекта» означает разрушение привычных механизмов верификации знаний. Во-вторых, сказывается поколенческий цифровой разрыв: 91,5 % студентов являются активными пользователями нейросетей, тогда как 14,5 % преподавателей не используют их вовсе. В-третьих, ключевую роль играет институциональный вакуум: отсутствие согласованных норм и регламентов заставляет преподавателей занимать осторожную позицию, а студентов – действовать в «серой зоне», скрывая использование «искусственного интеллекта». Преодоление этой тройной асимметрии – функциональной, ценностной и институциональной – составляет главный вызов цифровой трансформации высшего образования.
6. Заключение
Проведённое исследование подтвердило выдвинутую авторами гипотезу: асимметрия восприятия нейросетевых технологий преподавателями и студентами носит системный, многомерный характер, проявляясь одновременно на функциональном, ценностном и институциональном уровнях. Эмпирические данные, полученные в ходе анкетирования 188 студентов и 62 преподавателей, в сочетании с аналитикой глобальных трендов позволяют сформулировать ряд принципиальных выводов и практических рекомендаций.
Во-первых, тотальный запрет или игнорирование технологий «искусственного интеллекта» в образовательной среде более не являются реалистичной стратегией. Когда 91,5 % студентов выступают активными пользователями нейросетей, а 64,9 % декларируют готовность продолжать их использование даже под угрозой санкций со стороны преподавателей, любые запретительные меры лишь вытесняют практику в «серую зону», усугубляя взаимное недоверие между участниками образовательного процесса. Экспоненциальный рост объёмов генерируемого «искусственным интеллектом» контента, который, согласно прогнозам к 2030 году достигнет 120 триллионов слов, делает необратимой трансформацию всей информационной среды, в которой существует современное образование. Сопротивление этому процессу контрпродуктивно – необходим переход от реактивного неприятия к проактивной регламентации.
Во-вторых, ключевым инструментом преодоления выявленной асимметрии должна стать разработка вузами локальных нормативных актов, регулирующих использование «искусственного интеллекта» в учебной и научной деятельности. Такие акты, востребованность которых подтверждается мнением 38,7 % преподавателей и косвенно – готовностью 53,2 % студентов к прозрачной фиксации своего взаимодействия с нейросетями, должны определять:
- допустимые форматы применения «искусственного интеллекта» в различных видах работ;
- требования к обязательному декларированию факта использования генеративных систем;
- критерии разграничения вспомогательного использования «искусственного интеллекта» и академического мошенничества.
Легализация, с чёткими правилами использования «искусственного интеллекта» в образовательной деятельности снизит уровень тревожности преподавателей и одновременно создаст для студентов стимулы к ответственному взаимодействию с этой технологией.
В-третьих, образовательные программы всех направлений подготовки должны быть дополнены модулями, формирующими компетенции эффективного и критического взаимодействия с «искусственным интеллектом». Речь идёт не просто об обучении промпт-инжинирингу, но прежде всего – о развитии навыков верификации источников и критического анализа сгенерированного контента. Без специального обучения эти риски будут лишь нарастать. Цель такого курса – воспитать специалиста, который использует «искусственный интеллект» для оптимизации рутинных операций, но сохраняет субъектность, не превращаясь в пассивный придаток генеративной системы, бездумно транслирующий её выводы.
В-четвертых, уже сегодня необходима трансформация фондов оценочных средств. Когда 54,8 % преподавателей лучшей защитой от списывания путем использования «искусственного интеллекта» считают устный экзамен по билетам, а 37,1 % – решение кейсов в аудитории без гаджетов, это сигнализирует о назревшей потребности в переходе от репродуктивных форм контроля (рефераты, типовые эссе) к компетентностно-ориентированным заданиям: проектным работам с публичной защитой, решению реальных кейсов, устным собеседованиям. Такой подход не отрицает использования «искусственного интеллекта» на этапе подготовки, но делает невозможной полную подмену студенческой работы машинной генерацией.
Наконец, в-пятых, преодоление асимметрии восприятия невозможно без системного повышения квалификации преподавателей. Программы, по изучению возможностей «искусственного интеллекта», должны стать массовыми и охватывать не только технические аспекты работы с нейросетями, но и методику их интеграции в преподавание конкретных дисциплин. Преподаватель, владеющий инструментами работы с «искусственным интеллектом» на уровне своих студентов, перестаёт воспринимать технологию как угрозу и обретает способность выстраивать образовательный процесс, адекватный цифровой эпохе.
Таким образом, основной путь развития высшего образования в условиях экспансии «искусственного интеллекта» лежит не в плоскости установления запретов и сопротивления, а в плоскости осознанной, регламентированной и методически обеспеченной интеграции нейросетевых технологий в образовательный процесс, при которой рутинные операции делегируются машине, а критическое мышление и творческий поиск остаются прерогативой человека.
Источники:
2. Белоус М. ИИтоги марта 2026 г.: мартышкин труд?. Источник: информационный портал «3DNews». [Электронный ресурс]. URL: https://3dnews.ru/1139376/iitogi-marta-2026 (дата обращения: 07.04.2026).
3. Зимовец А. В., Синиченко О. А. Анализ динамики и структуры использования цифровых технологий // Статистика – главный информационный ресурс современного общества: Сборник статей по материалам Всероссийской научно-практической конференции, Пермь, 16–17 октября 2023 года. – Пермь: Пермский государственный национальный исследовательский университет. Пермь, 2024. – c. 138-145.
4. Искусственный интеллект. Источник: Большая российская энциклопедия. [Электронный ресурс]. URL: https://bigenc.ru/c/iskusstvennyi-intellekt-ac9fb0 (дата обращения: 22.04.2026).
5. Малафеевская В. С. Генезис подходов к определению понятия искусственный интеллект // Весці БДПУ. Серыя 2. Гісторыя. Філасофія. Паліталогія. Сацыялогія. Эканоміка. Культуралогія. – 2024. – № 1. – c. 72-78.
6. Маринова И. В., Зимовец А. В. К вопросу организации учебного процесса в условиях цифровизации образования // Вестник Таганрогского института управления и экономики. – 2022. – № 1. – c. 98-101.
7. Микелевич Е. Б. Психолого-педагогические и этические аспекты использования ChatGPT в высшем образовании // Банковская система: устойчивость и перспективы развития: сборник научных статей XVI Международной научно-практической конференции по вопросам финансовой и банковской экономики, Полесский государственный университет, г. Пинск, Республика Беларусь, 24 октября 2025 года / [редкол.: В. И. Дунай, И. А. Пригодич, Т. А. Ржевская; Полесский государственный университет [ и др.]– Пинск: ПолесГУ. Пинск, 2025. – c. 134-137.
8. Минский М., Пейперт С. Персептроны = Perceptrons. - М.: Мир, 1971. – 261 c.
9. Дробот Е.В., Макаров И.Н., Казарова Д.С., Володина А.И., Гердина Н.Н. Необходимость новых подходов к кадровому менеджменту и коррекции образовательной системы в условиях цифровизации экономики // Лидерство и менеджмент. – 2024. – № 2. – c. 729-740. – doi: 10.18334/lim.11.2.120896.
10. Паршин А. А., Жашкова Т. В. Принцип обработки информации в искусственной нейронной сети // Тенденции развития науки и образования. – 2023. – № 98-10. – c. 99-102. – doi: 10.18411/trnio-06-2023-551.
11. Петренко Т. В., Зимовец А. В. Моделирование кризиса труда. - Таганрог: Таганрогский институт управления и экономики, 2023. – 158 c.
12. Путивцев М.Е., Зимовец А.В. Анализ и определение основных показателей эффективности SaaS предприятия // Информатизация в цифровой экономике. – 2024. – № 1. – c. 151-166. – doi: 10.18334/ide.5.1.120566.
13. Проба ИИ-пера: как создавались первые «нейродипломы». Источник: IQ Media – онлайн издание НИУ ВШЭ. [Электронный ресурс]. URL: https://iq-media.ru/life/proba-ii-pera-kak-sozdavalis-pervye-neyrodiplomy (дата обращения: 26.09.2024).
14. Мацкуляк И. Д., Мацкуляк Д. И., Нагдалиев Н. З. Сравнение искусственного и естественного интеллектов // Шаг в будущее: искусственный интеллект и цифровая экономика. Технологическое лидерство: взгляд за горизонт: материалы IV Международного научного форума / Министерство науки и высшего образования Российской Федерации, Государственный университет управления; под общей редакцией П. В. Терелянского. – Москва: Гос. ун-т упр. Москва, 2021. – c. 3.
15. Фон Нейман Дж. Теория самовоспроизводящихся автоматов. - М.: Мир, 1971.
16. Штанько М. А., Забирова Т. А. Роль электронного учебно-методического комплекса в образовательном процессе высшей школы // Социально-гуманитарные научные дискуссии в России и за рубежом: Сборник научных статей. – Москва: ООО ПЕРО. Москва, 2025. – c. 177-180.
17. Эшиш Васвани, Ноам Шазир, Ники Пармар, Якоб Ушкорейт, Ллион Джонс, Эйдан Гомес, Лукаш Кайзер, Полосухин И. Transformer: A Novel Neural Network Architecture for Language Understanding. [Электронный ресурс]. URL: https://research.google/blog/transformer-a-novel-neural-network-architecture-for-language-understanding/ (дата обращения: 31.08.2017).
18. Янкина И. А. Оценка конкурентоспособности учреждения высшего образования: инновационные подходы и цифровой статус // Вестник Таганрогского института управления и экономики. – 2024. – № 1. – c. 38-46.
19. Янкина И. А. Роль образования в эпоху цифровизации // Актуальные проблемы гуманитарных и общественных наук: сборник статей VIII Всероссийской научно-практической конференции, Пенза, 13–14 сентября 2022 года. – Пенза: Пензенский государственный аграрный университет. Пенза, 2022. – c. 179-182.
20. Hebb D.O. The Organization of Behavior. - New York: Wiley & Sons, 1949.
21. Hopfield J.J. Neural networks and physical systems with emergent collective computational // Proceedings of National Academy of Sciences. – 1982. – № 8. – p. 2554—2558.
22. McCalloch W.S., Pitts W. A logical calculus of the ideas immanent in nervous activity // Bull. Math. Biophys. – 1943. – p. 115-133.
23. Rosenblatt F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. In, Psychological Review, Vol. 65, No. 6, pp. 386-408, November, 1958. Lancaster, PA and Washington, DC: American Psychological Association, 1958
24. Turing A. Computing machinery and intelligence. / Mind: журнал. - Oxford: Oxford University Press, 1950. – 433-460 p.
Страница обновлена: 24.07.2026 в 18:54:28
Download PDF | Downloads: 11
Artificial intelligence through the eyes of students and educators: perceptual asymmetry and pathways to overcoming it
Zimovets A.V., Koshman V.V., Marinova I.V.Journal paper
Russian Journal of Innovation Economics
Volume 16, Number 2 (April-June 2026)
Abstract:
The rapid development and subsequent expansion of generative neural network technologies into higher education creates a paradoxical situation: on the one hand, large language models have become an everyday tool for the vast majority of students, on the other hand, their application remains spontaneous, unregulated and causes rejection by a significant part of academic staff. The article aims to identify and analyze the key manifestations of the asymmetry in the perception of these technologies by the main participants in the educational process. Based on the survey conducted in February-March 2026, it was found that this asymmetry has a systemic multidimensional character and manifests itself at the functional, value and institutional levels. It has been revealed that students perceive artificial intelligence as a way to optimize their academic routine, while academic staff perceives it as a threat to academic integrity. A key barrier to the constructive integration of "artificial intelligence" technologies into the educational process is the lack of clear institutional mechanisms regulating its application in the educational process, despite the fact that both groups of respondents generally supported the idea of teaching digital literacy.
According to the results of the study, the authors substantiate the need to move away from prohibitive strategies for using neural network technologies in the educational process and the need to move to its regulation and transformation of assessment tools.
Keywords: "artificial intelligence" in education, neural network technologies, large language models, perception asymmetry, academic honesty, education digital transformation, institutional regulation
JEL-classification: I20, I23, O33, C80, K24
References:
Drobot E.V., Makarov I.N., Kazarova D.S., Volodina A.I., Gerdina N.N. (2024). The need for new approaches to personnel management and correction of the educational system amidst digitalization. Leadership and Management. 11 (2). 729-740. doi: 10.18334/lim.11.2.120896.
Fon Neyman Dzh. (1971). Theory of self-replicating automata
Hebb D.O. (1949). The Organization of Behavior
Hopfield J.J. (1982). Neural networks and physical systems with emergent collective computational Proceedings of National Academy of Sciences. 79 (8). 2554—2558.
Malafeevskaya V. S. (2024). Genesis of Approaches to Defining the Concept of Artificial Intelligence. Vestsі BDPU. Seryya 2. Gіstoryya. Fіlasofіya. Palіtalogіya. Satsyyalogіya. Ekanomіka. Kulturalogіya. (1). 72-78.
Marinova I. V., Zimovets A. V. (2022). On the issue of organizing the educational process in the context of digitalization of education. Bulletin of Taganrog Institute of Management and Economics. (1). 98-101.
Matskulyak I. D., Matskulyak D. I., Nagdaliev N. Z. (2021). Comparison of artificial and natural intelligence Step into the future: artificial intelligence and the digital economy. Technological leadership: Looking beyond the horizon. 3.
McCalloch W.S., Pitts W. (1943). A logical calculus of the ideas immanent in nervous activity Bull. Math. Biophys. 5 115-133.
Mikelevich E. B. (2025). Psychological, pedagogical and ethical aspects of using ChatGPT in higher education Banking system: sustainability and development prospects. 134-137.
Minskiy M., Peypert S. (1971). Perceptrons
Parshin A. A., Zhashkova T. V. (2023). The principle of information processing in an artificial neural network. Trends in the development of science and education. (98-10). 99-102. doi: 10.18411/trnio-06-2023-551.
Petrenko T. V., Zimovets A. V. (2023). Modeling the labor crisis
Putivtsev M.E., Zimovets A.V. (2024). Analysis and determination of the main performance indicators of the SaaS company. Informatization in the Digital Economy. 5 (1). 151-166. doi: 10.18334/ide.5.1.120566.
Rosenblatt F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. In, Psychological Review, Vol. 65, No. 6, pp. 386-408, November, 1958. Lancaster, PA and Washington, DC: American Psychological Association, 1958
Shtanko M. A., Zabirova T. A. (2025). The role of the electronic educational and methodical complex in the educational process of higher education Social and humanitarian scientific discussions in Russia and abroad. 177-180.
Turing A. (1950). Computing machinery and intelligence
Yankina I. A. (2022). The role of education in the age of digitalization Current problems of the humanities and social sciences. 179-182.
Yankina I. A. (2024). Assessment of the Competitiveness of the Institute of Higher Education: Innovation Approaches and Digital Status. Bulletin of Taganrog Institute of Management and Economics. (1). 38-46.
Zimovets A. V., Sinichenko O. A. (2024). Analysis of the dynamics and structure of the use of digital technologies Statistics as the main information resource of modern society. 138-145.