Сегментация потребителей на основе TF-IDF кластеризации текстов в социальных сетях
Артюнин А.Д.1 ![]()
1 Санкт-Петербургский государственный экономический университет, Санкт-Петербург, Россия
Скачать PDF | Загрузок: 10
Статья в журнале
Маркетинг и маркетинговые исследования (РИНЦ, ВАК)
опубликовать статью
Том 31, Номер 2 (Апрель-июнь 2026)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=91570513
Аннотация:
В статье представлена авторская методика психографической сегментации потребителей на основе кластеризации текстовых данных, публикуемых пользователями в социальной сети ВКонтакте. С использованием инструментов анализа естественного языка (TF-IDF, лемматизация, машинное обучение) проведено пилотное исследование поведения участников официального сообщества бренда «Москвич». В результате выявлены устойчивые кластеры потребителей — от групп с преобладанием поздравительных и эмоциональных тематик до сегментов с коммерческой и клубной активностью. Обсуждаются перспективы применения подхода для повышения эффективности маркетинговых коммуникаций, а также ограничения текущего исследования, связанные с необходимостью дальнейшего расширения и детализации выборки
Ключевые слова: сегментация потребителей, NLP, TF-IDF, анализ текстов, большие данные, маркетинг
JEL-классификация: M30, M31, C38, C55, C88
Введение. В условиях стремительного развития современной экономики и постоянно нарастающей конкуренции на рынке задача глубоко понимать своего потребителя становится краеугольным камнем для успешного функционирования бизнеса. Сегментация потребителей — это не только базовая категория стратегического маркетинга и фундаментальное условие принятия управленческих решений, лежащее в основе построения эффективных бизнес-стратегий [10], но и практическая деятельность, с которой сталкиваются рядовые сотрудники коммерческих компаний (например, продавцы или торговые представители). Несмотря на то, что термин «сегментация» вошёл в экономическую литературу лишь в середине XX века [14, 35], сама идея выделения групп с уникальными предпочтениями и потребностями гораздо древнее и восходит к ранней истории торговли и производства. На протяжении веков ремесленники и купцы, а позднее и промышленные предприниматели, неизменно сталкивались с необходимостью учитывать социальные, культурные, географические и прочие отличия своих клиентов. Сегодня, в цифровую эпоху, внимание к индивидуальности потребителя и его глубинным мотивациям выходит на новый уровень, требуя от бизнеса тонкого анализа и внедрения передовых инструментов сегментации, - часто с опорой на машинное обучение и анализ больших данных.
1. Эволюция идеи сегментации: от сословных различий к маркетинговым стратегиям и ИИ (искусственному интеллекту). Исторические истоки сегментации потребителей уходят в эпоху доиндустриальной экономики [34], когда товары производились для конкретных социальных слоёв: дворянство, купечество, крестьянство и т.д. Ярко выраженная общественная стратификация диктовала производителям и торговцам необходимость адаптироваться под запросы и традиции каждого социального «класса», формируя тем самым зачатки современной концепции «сегментации потребителей». Важными аспектами выбора и оценки своего покупателя становились не только экономические и производственные возможности, но и личные связи, статус ремесленника, осведомленность о моде в конкретном регионе, знание праздничных традиций и индивидуальных психических особенностей заказчиков [3, 6, 8].
С наступлением Промышленной Революции и бурным развитием фабричного производства, рынок товаров стал массовым, а производители — более ориентированными на универсальные стандарты. Однако постепенно вместе с этим возникла потребность в учете всё более сложных, не только утилитарных, но и глубинных запросов групп покупателей. Классические экономисты XVIII–XIX веков, такие как Адам Смит [13], Жан Батист Сей [11], Торстейн Веблен [1] и Вильфредо Парето [9], формируют теоретические основания для понимания того, что поведение потребителей — явление дифференцированное, а ценность товаров субъективна и может быть связана не только с полезностью или стоимостью, но и с социальным статусом, образом жизни, личными ценностями и амбициями. На этом фундаменте строится современная маркетинговая сегментация: выделяются демографические, географические, поведенческие и психографические признаки покупателей [1], по которым бизнес стремится структурировать свои рынки.
В XX веке, с переходом бизнеса к диверсификации продуктового портфеля, усложняется и сегментация. Классический пример — автомобильная индустрия: переход от однотипного предложения (Ford Model T) к дифференцированному ассортименту по цене, дизайну, опциям (автомобили General Motors в 1920-е годы) [12, 15]. Великая депрессия, развитие FMCG (Fast Moving Consumer Goods – пер. с англ. «товары повседневного спроса») и конкуренция между производителями заставили бизнес не только выделять целевые сегменты, с точки зрения уровня доходов, возраста и пола, но и глубже исследовать именно психографические параметры своих клиентов: стиль жизни, ценности, отношение к новизне, мотивацию к покупке, статусные ожидания и т.п.
И до сих пор, особенно с развитием цифровой экономики, в последние десятилетия важнейшее стратегическое значение приобретает именно психографическая сегментация. Именно она позволяет бизнесу не просто выделять внешне схожие группы, но выстраивать персонализированные коммуникации, предлагать уникальные ценностные предложения, строить долгосрочные отношения и формировать лояльность, - спускаясь до каждого отдельного клиента (т.н. гиперсегментация («hyper segmentation» [20]).
Сегодня в условиях цифровизации, многообразия каналов коммуникации и усложнения потребительских мотиваций традиционные методы психографической сегментации (опросы, интервью, фокус-группы, панельные исследования и т.п.) часто уступают место новым аналитическим подходам: использованию больших данных (Big Data), искусственного интеллекта и машинного обучения [33].
Анализ 1000 самых актуальных публикаций (рис. 1) научной базы данных «The Lens» [32] по запросу «customer segmentation» при помощи наукометрической системы VOSviewer (на конец 2025 года) позволяет говорить о глубокой связи в современных научных статьях таких технических терминов как «clustering», «machine learning» и пр. и «customer segmentation».
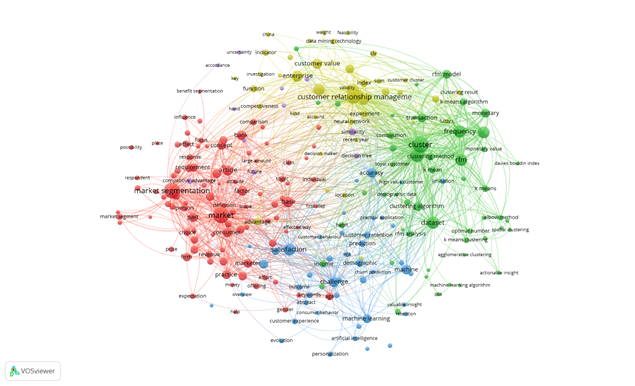
Рис. 1 – Диаграмма связей (составлено автором)
На рисунке 1 показаны связи между ключевыми терминами научных публикаций по теме "customer segmentation". Исследовательское пространство может быть разделено на несколько тематических кластеров.
Красный кластер (слева) концентрируется вокруг терминов "market segmentation", "consumer", "requirement", "practice", "advantage". Это классические вопросы маркетинга и рыночного позиционирования, в которых обсуждается сегментация клиентов с точки зрения рынка, требований потребителей и преимуществ для компаний.
Зеленый кластер (справа) связан с аналитическими методами и методами кластеризации: "cluster", "rfm", "frequency", "monetary", "clustering algorithm", "k means algorithm" и т.д. Здесь видно, что значительная часть работ посвящена использованию методов анализа данных и кластеризации (особенно популярных алгоритмов, вроде k-means), а также применению RFM (пер. с англ: Recency – давность; Frequency – частота; Monetary – сумма затрат) модели для сегментирования клиентов.
Жёлтый кластер (сверху) объединяет темы "customer relationship management", "customer value" и "enterprise". Здесь акцент смещён на управление взаимоотношениями с клиентами и создание ценности, что связано с корпоративными задачами и построением долгосрочных отношений.
Синий кластер (внизу) – сам по себе небольшой, но очень существенный. Он связан с терминами "machine learning", "artificial intelligence", "prediction", "accuracy". Кластер отражает современный тренд на использование ИИ и машинного обучения для сегментации потребителей. Видно, что темы искусственного интеллекта интегрируются с анализом данных, точностью прогнозов и поиском новых решений для более тонкого и динамичного сегментирования.
Таким образом:
- Традиционный маркетинговый подход (красный кластер) к сегментации всё ещё актуален, однако значительно дополняется (и иногда вытесняется) современными аналитическими методами (зелёный кластер).
- Использование ИИ и машинного обучения (синий кластер) становится всё более важным, интегрируя в себе задачи прогнозирования, автоматизации и оптимизации сегментации.
- Управление стоимостью клиента и отношениями (жёлтый кластер) остаётся значимым направлением, где данные и ИИ также широко используются.
В целом, развитие ИИ и анализа данных в сегментации клиентов идёт по пути интеграции с классическими маркетинговыми подходами, расширяя инструментарий и углубляя понимание поведения клиентов.
Таким образом, у современного бизнеса возникает острая необходимость в изучении инновационных методов и подходов, способных раскрывать глубинные психографические характеристики потребителей, структурировать их и использовать для создания успешных маркетинговых стратегий. Доказывая значимость психографической сегментации, современная научная мысль и практика подводят к необходимости комплексного анализа и поиску новых методологических решений в данной области, определяемых, в первую очередь, бурным развитием ИИ и компьютерных технологий.
2. Разработка новой авторской методологии: сегментация пользователей социальных сетей на основе TF-IDF кластеризации текстовых данных. В условиях стремительного роста количества данных т.н. «цифрового следа» [5], оставляемых пользователями в социальных сетях, возрастает потребность в эффективных инструментах анализа и сегментации потребительских аудиторий на основе их информационного поведения. Практика бизнеса всё чаще обращается к методам автоматизированной обработки естественного языка (NLP) [22, 23] и машинного обучения, позволяющим выявлять глубинные структуры интересов, ценностей и типов активности пользователей. Такой подход реализован, например, рекомендательными системами IT-гигантов или маркетплейсов и обеспечивает возможность формирования содержательной сегментации не только по анкетным, но и по поведенческим признакам, непосредственно отражающим реальные информационные потребности как групп пользователей, так и одного конкретного пользователя.
В настоящей работе предлагается экспериментальный подход к сегментированию потребителей, исходящий из анализа текстового контента их публикаций в социальных сетях (в дальнейшем пилотном исследовании речь идёт о публикациях на «стене пользователя» ВКонтакте). Ключевая идея данного экспериментального подхода состоит в том, чтобы использовать массив пользовательских публикаций (включая оригинальные записи и репосты) как отражение индивидуальных интересов и позиций в цифровом пространстве.
Через процедуры предобработки и векторизации текстов [4] публикаций (NLP-методы) каждый пользователь оказывается представлен математически как многомерный вектор, отражающий структуру текстовых данных на его «стене». Кластеризация этих векторов позволяет выделять однородные группы пользователей в соответствии с тем контентом, который отражает их психографические особенности.
Предложенный экспериментальный подход реализуется на программном уровне при помощи Python и включает следующие основные этапы:
1. Сбор и агрегация данных. Данные собирается посредством автоматизированного обращения к официальному API (Application Programming Interface — пер. с англ.: программный интерфейс приложения) социальной сети (например, ВКонтакте). Для каждого пользователя открытого сообщества с помощью библиотеки requests реализуется автоматический сбор данных, позволяющий получить совокупность публичных публикаций (включая оригинальные посты и репосты) за выбранный период времени (в пилотном исследовании отбирались публикации за последний год). На этапе сбора обеспечивается обработка исключительных ситуаций (ошибки соединения, превышение лимитов запросов) с помощью конструкции try-except и логирования промежуточных результатов в txt файлы (os, logging). Сначала программа получает список подписчиков заданного сообщества, затем по данному списку получает публикации каждого участника сообщества.
2. Предобработка и нормализация текстового контента. Получаемые датасеты публикаций на практике часто оказываются «замусоренными» различными включениями, которые не представляют интереса для анализа: пустые публикации (без текста); публикации, содержащие только числа или только рекламные ссылки; слишком короткий текст (менее 10 символов); обилие бессмысленных слов и т.д. Очищенные и подготовленные данные агрегируются для каждого пользователя в единый «документ», который далее подвергается векторизации и кластерному анализу. Для повышения качества сравнения и уменьшения лексической вариативности «токенов» применяется лемматизация (морфологический анализ слов, их приведение к базовой форме) с использованием библиотеки pymystem3 (проект Яндекса для русского языка) [17]. Этап очистки также позволяет удалить лишние символы, ссылки и технические элементы даже из предварительно отобранных публикаций пользователя (например, знаки препинания).
3. Математическая модель TF-IDF (Term Frequency–Inverse Document Frequency). Для векторизации лемматизированных и готовых к дальнейшему анализу документов используется классический метод TF-IDF (Term Frequency–Inverse Document Frequency – пер. с англ: частота термина в документе – обратная частота документа в корпусе) [2], алгоритм которого вычисляет важность слова в контексте индивидуального «документа» (совокупности публикаций конкретного пользователя) и всего «корпуса» (всей базы пользователей, - в нашем случае). TF-IDF для каждой леммы вычисляется по стандартной формуле.
Пусть t — отдельное слово (лемма, токен), d — документ (тексты одного пользователя в нашем случае), D — коллекция всех документов (корпус из документов всех пользователей). Тогда сначала вычисляется частота термина в документе (TF, term frequency):
![]()
Далее рассчитывается обратная частота термина (IDF, inverse document frequency):
![]()
И, наконец, итоговая формула TF-IDF:
![]() .
.
Такая векторизация реализована в библиотеке scikit-learn посредством класса TfidfVectorizer, который автоматически преобразует лемматизированные тексты пользователей в матрицу признаков.
4. Кластеризация пользователей (K-Means) Векторные представления «документов» пользователей, полученные с помощью TF-IDF, подвергаются кластерному анализу с использованием метода k-средних (K-Means) и библиотеки scikit-learn. Алгоритм инициализирует k центров-кластеров и повторно распределяет пользователей по этим центрам, минимизируя внутрикластерное расстояние. Определение оптимального числа кластеров производится при помощи «метода локтя» и оценки качества кластеризации «методом силуэтов» (silhouette method), а также опирается на общую логику маркетингового анализа и целей сегментации.
5. Построение сегментных профилей и интерпретация результатов. Чтобы охарактеризовать каждый полученный кластер и увидеть смысловые отличия, для каждого выделенного кластера строится агрегированный “мешок слов” с помощью частотного анализа токенов (отбираются самые часто употребляемые слова), а также производится внутрикластерное вычисление TF-IDF, позволяющее определить самые влиятельные токены кластера с точки зрения смысла. Сравнительный анализ частот и TF-IDF токенов позволяет выделять специфические лингвистические особенности аудитории в каждом кластере. Возможна интерпретация результатов при помощи LLM (Large Language Model – пер. с англ.: большие языковые модели).
6. Иерархическая кластеризация данных. На данном этапе происходит получение новых кластеров внутри найденных кластеров путём TF-IDF векторизации и кластеризации пользователей внутри ранее найденных крупных кластеров. Далее необходимо визуализировать и описать кластеры второго, третьего и т.д. уровней.
В таблице 1 отражен список Python-библиотек, которые использованы далее в исследовании, призванном продемонстрировать работу подхода.
Талица 1. Совокупность библиотек, использованных в исследовании
|
Библиотека
|
Функция/Назначение
|
|
pandas [25]
|
Чтение/запись
Excel-файлов, обработка таблиц, группировка, фильтрация
|
|
scikit-learn [26]
|
Кластеризация
(KMeans), векторизация текстов (TfidfVectorizer), оценка качества
кластеризации (silhouette_score)
|
|
pymystem3 [17]
|
Лемматизация
(приведение слов к словарной форме для русского языка)
|
|
nltk [18]
|
Токенизация,
удаление стоп-слов, обработка естественного языка
|
|
requests [31]
|
Парсинг и
отправка HTTP-запросов к VK API
|
|
os [29]
|
Работа с
файлами, проверка наличия файлов, логика хранения прогресса
|
|
logging [28]
|
Ведение логов
событий и ошибок программы
|
|
collections [27]
|
Частотный анализ
(Counter), создание мешка слов
|
|
re [30]
|
Очистка текста,
регулярные выражения для фильтрации
|
|
tqdm [19]
|
Визуализация
прогресса обработки данных (progress bar)
|
|
matplotlib [24]
|
Визуализация
графиков: "локоть", силуэт-скор и др.
|
|
numpy [21]
|
Работа с
массивами, быстрые численные операции (например, сортировка)
|
Содержание постов пользователей в первоначальном датасете было очень разным (подавляющее число постов, как оказалось, не содержало текстовых данных: например, только фотографии, видеоролики, аудиозаписи и т.п. – эти данные не входят в лингвистический анализ), поэтому после удаления «пустых» публикаций (не имеющих текста) размет датасета уменьшился до 160 481 публикации. Из этих публикаций для итогового анализа в автоматическом режиме компьютером было отобрано 69 191 публикаций, содержащих осмысленный текст, пригодный для лингвистического анализа. Для этого компьютер удалял из итогового датасета:
- короткие посты (до 10 символов) и посты, имеющие менее 2 слов;
- посты со спамом, хештегами;
- отсутствием латинских или кириллических букв;
- рекламные или бессмысленные публикации, имеющие в своём составе только ссылку вида "http...".
Всего разных подписчиков исследуемого сообщества, имеющих на «стене» те самые 69 191 осмысленных публикаций и вошедших в итоговый анализ, оказалось всего 2 161 человек.
Далее полученная база данных была подвергнута алгоритму векторизации и каждый из 2 161 человек был представлен в качестве многомерного вектора, в котором для каждого слова-токена была посчитана метрика TF-IDF. Данная матрица была подвергнута алгоритму кластеризации K-Means с предварительным построением графиков «локтя» и «силуэта» для определения оптимального числа кластеров.
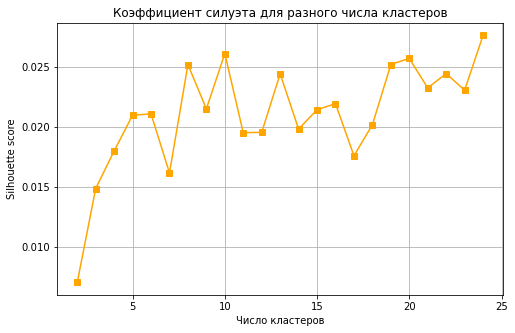
Рис.2 – Диаграмма «silhouette method» для матрицы (составлено автором)
Исходя из графика силуэтов и целей анализа было принято решение остановиться на 7 кластерах для удобства интерпретации результатов и удобства деления потребителей на крупные значительные группы.
В результате кластеризации было получено 7 кластеров, для каждого из которых вычислен «мешок слов» и TF-IDF для каждого токена. 100 самых частых токенов из «мешка слов» и 100 самых значительных с точки зрения TF-IDF токенов (в порядке уменьшения TF-IDF) по каждому кластеру были отданы с соответствующим промптом на вход одной из самых совершенных на сегодняшний день LLM - ChatGPT 4.1 [16]. На выходе LLM смогла помочь с характеристикой каждого кластера, и итоговая характеристика кластеров выглядит следующим образом:
- 1 Кластер. Содержит 206 человек и в основном представлен поздравительной лексикой: дни рождения, именины. Слово "день" сочетается с "рождение", "именины", "праздник" и леммами "поздравлять", "пусть", "желать", "счастье", "здоровье", "любовь", "удача". Часто встречаются местоимения и обращение к человеку ("ты", "твой", "мой", "наш", "вы" и пр.), что говорит о личностной, адресной коммуникации: поздравляют конкретных людей, семьи, друзей, коллег. Тональность - позитивная, преобладают добрые пожелания, благодарность и теплота. Включение лемм "международный", "всемирный" намекает на поздравления в дни международных праздников. В данном кластере пользователи делятся радостными новостями, поздравляют друг друга и высказывают пожелания благополучия.
- 2 Кластер. Содержит 302 человека и представлен общими разговорными темами (требуется дальнейшая кластеризация). В этом кластере отражается широкий спектр тем — от обсуждения событий года и дня, личной жизни, эмоций, до более философских рассуждений ("жизнь", "любовь", "самый", "человек", "город", "работа"). Этот кластер отражает "полотно жизни": обсуждение проблем, успехов, новостей, реакции на происходящее, релевантные вопросы и жизненные ситуации, советы, обращения, общие рассуждения и знакомства. Тональность смешанная: посты могут быть как нейтральными, так и эмоциональными (есть слова "спасибо", "просто", "хотеть", встречаются упоминания о детях, друзьях, подарках, праздниках).
- 3 Кластер. Содержит 93 человека и выделяется специфическими леммами-предметами ("платье", "костюм", "ткань"), а также терминами, связанными со зрелищными и культурными событиями ("спектакль", "комедия", "концерт", "мюзикл", "опера", "шоу", "цирк", "премьера"). Также в небольшом количестве представлены слова, связанные с брендами, ритейлом и интернет-активностью.
- 4 Кластер содержит 213 человек, и в центре внимания участников кластера находятся клубы, коллективы, тематические сообщества по интересам — например, "семена", "агрофирма", "петуния". Важную роль играют слова, выражающие участие, сотрудничество ("проект", "участвовать", "конкурс", "приз", "подарок", "отчет", "отзыв"). Много географических упоминаний ("москва", "екатеринбург", "череповец"), что может говорить о локальной активности сообществ. Тональность мягкая и коллективная: благодарность ("спасибо", "благодарить"), обсуждение итогов, совместные победы, поддержка друг друга. Здесь люди объединяются по интересам, делятся успехами и советами.
- 5 Кластер. E-commerce, публикации магазинов, инфо-поводы, сервисы и реклама. Здесь превалирует "машинная" лексика, связанная с интернет-магазинами и платформами: "цена", "размер", "ткань", "новинка", "акция", "товар", "шмотки", "заказ", "балл", "проект", "app", "рубль", "www", "com", "vk", "ru", "mos". Часто встречаются технические и сервисные термины: "track", "ref", "share", "referrer", "голосование", "оценивать", "новинка", "наличие", "место". Тональность нейтральная, информирующая — описываются характеристики товаров, условия скидок, поступления новинок, акции, голосования, правила участия в проектах. Данный кластер — отражение рекламных публикаций для продажи товаров, продвижения сервисов интернет-магазинов, описания условий покупок, акций, новинок, запусков новых продуктов. Содержит 755 человек, - довольно много, поэтому требуется дальнейшая кластеризация.
- 6 Кластер. Кластер содержит 47 человек и связан с брендом «Ozon». В кластере заметна доминанта OZON, крупного маркетплейса, а также слова, связанные с проведением и итогами конкурсов, корпоративных акций: "ozonхочумиллион", "елка", "балл", "приложение", "поздравлять", "итогигода", "новогодний", "выигрывать". "елкаозонбанк"). Преобладает позитивная, игровая, праздничная тональность — посты посвящены участию в розыгрышах, промо-акциях, приложениях, итогам года, конкурсам с подарками и баллами.
- 7 Кластер. Крупный кластер (545 человек), требующий дальнейшей детализации. Этот кластер ориентирован на описание жизни, бытовых событий, впечатлений, эмоций и ежедневных дел. Главные слова: "день", "год", "лето", "утро", "город", "работа", "красота", "волосы", "кожа", "фото", "парк", "прогулка", "мир", "любить", "сегодня", "просто", "хороший". Содержание здесь близко к лайфстайл-блогам: люди делятся фотографиями, своими буднями, впечатлениями от прогулок, событиями семейной и рабочей жизни, описаниями внешности/ухода ("волос", "кожа"), местами ("город", "парк"), эмоциями ("любимый", "радость", "хороший", "добрый"). Часто присутствуют нейтральные и позитивные сентименты — благодарность, пожелания, легкие рассуждения о жизни. Посты включают зарисовки о себе, природе, буднях, прогулках, встречах и личных увлечениях, нередко иллюстрируются фотографиями.
Затем операция кластеризации TF-IDF векторов была применена для участников первичных кластеров, что позволило детализировать кластеризацию и создать многоуровневую (иерархическую) кластеризацию пользователей (таблица 2).
Таблица 2. – Иерархическая кластеризация участников сообщества бренда «Москвич» по превалирующей лексике в публикациях на «стене» пользователя ВКонтакте
|
Первичный кластер
|
Чел.
|
Второй, третий и т.д. уровни кластеризации
|
Чел.
| ||||
|
1. Поздравления,
праздничная активность, пожелания и теплые слова
|
206
|
1.1.
Поздравления с днём рождения, семейные поздравления
|
102
| ||||
|
1.2.
Помимо поздравлений семейных, много отмечают официальные праздники (день
победы, новый год, 8 марта)
|
104
| ||||||
|
2.
Общение, размышления, жизненные ситуации, универсальные темы
|
302
|
2.1.
"Встреча между хлебом" - флешмоб
|
6
| ||||
|
2.2.
Универсальные разговорные посты, рефлексия, повседневная коммуникация
|
138
| ||||||
|
2.3.
Коммуникация событий, публикации о жизни, культурные активности, городской
контент
|
70
| ||||||
|
2.4.
Клубы, бренды, лайфстайл, еда и красота, товарно-экспертные обсуждения
|
36
| ||||||
|
2.5.
Семейная тематика, эмоциональный контент
|
52
| ||||||
|
3.
"Хочу на": мода, покупки, культурные мероприятия
|
93
|
3.1.
Платья, мода, одежда
|
71
| ||||
|
3.2.
Культурные мероприятия
|
22
| ||||||
|
4.
Клубная жизнь, сообщества по интересам, совместные проекты и активности
|
213
|
4.1.
Любители природы, садоводства и путешествий
|
104
| ||||
|
4.2.
Любители говорить "спасибо" (благодарят бренды, места для
путешествий и т.д., иногда других людей)
|
74
| ||||||
|
4.3.
Еда, товары и услуги (разнородный коммерческий кластер)
|
22
| ||||||
|
4.4.
Обсуждают елки и новый год
|
7
| ||||||
|
4.5.
Новокузнецк (локальный бизнес и повседневность)
|
6
| ||||||
|
5.
Е-коммерс, публикации магазинов, инфо-поводы, сервисы и реклама
|
755
|
5.1.
Национальный/региональный чат, разговорный и локальный контент (башкирская и
татарская лексика)
|
58
| ||||
|
5.2.
Продажи, новинки и обсуждение городских инициатив
|
599
|
5.2.1.
Радио, медиа, медиасобытия
|
350
|
5.2.1.1.
Медиа, трансляции и виртуальное общение
|
258
| ||
|
5.2.1.2.
Радио, ТВ, события и локальный досуг
|
50
| ||||||
|
5.2.1.3.
Новости регионов, выборы и тематические мероприятия
|
11
| ||||||
|
5.2.1.4.
Интервью, политика, криминалистика, публицистика
|
14
| ||||||
|
5.2.1.5.
Вязание, кулинария, - татарское сообщество
|
17
| ||||||
|
5.2.2.
Фотография, арт и студийные работы
|
32
| ||||||
|
5.2.3.
Местные акции и семейные события в Татарстане
|
7
| ||||||
|
5.2.4.
Продажи, новинки и городской сервис
|
195
| ||||||
|
5.2.5.
Кластер ненагруженных текстов со словом "красота"
|
15
| ||||||
|
5.3.
Музыка, сервисы и промо-платформы
|
42
| ||||||
|
5.4.
Личный блог, еда, рецепты, эмоции и фото-события
|
18
| ||||||
|
5.5.
ВКонтакте, приложения и активность сообщества
|
38
| ||||||
|
6.
Брендированные акции и конкурсы, OZON
|
47
|
6.
Брендированные акции и конкурсы, OZON
|
47
| ||||
|
7.
Повседневность, лайфстайл, личные заметки
|
545
|
7.1.
Праздничные поздравления и события
|
20
| ||||
|
7.2.
Бьюти-индустрия: уход за собой, наращивание ресниц и бровей
|
61
| ||||||
|
7.3.
Сторителлинг, стихи и философские тексты
|
120
| ||||||
|
7.4.
Желающие доброго утра и других благих пожеланий
|
25
| ||||||
|
7.5.
Город, отдых, семья и красивые места
|
319
|
7.5.1.
Новости, повседневная жизнь, локальный ногтевой сервис
|
110
| ||||
|
7.5.2.
Путешествия, музеи, города, семейные истории
|
40
| ||||||
|
7.5.3.
Семья: творчество, фотоотчёты, эмоции
|
45
| ||||||
|
7.5.4.
Фотоистории, выездные фото, спорт и дети
|
47
| ||||||
|
7.5.5.
Кластер публикаций о культурном и активном отдыхе, прогулках и мероприятиях
(преимущественно в Москве)
|
77
| ||||||
4. Обсуждение результатов исследования. Результаты проведённого пилотного исследования на примере подписчиков официального сообщества автомобильного бренда «Москвич» во ВКонтакте демонстрируют высокий уровень дифференциации аудитории по содержанию пользовательских публикаций. Применение метода кластеризации TF-IDF позволило выявить как крупные, так и более специализированные группы потребителей, объединённых схожей лексикой и интересами. Существенную часть выявленных кластеров составили группы, связанные с лайфстайлом, рефлексией, выражением эмоций и личным опытом, а также сегменты, ориентированные на коммерческую активность, маркетинговые проекты и участие в онлайн-инициативах.
Структура кластеров показала, что психографическая сегментация, реализованная на основе анализа текстового контента, в перспективе способна дополнять другие методы анализа данных, полнее раскрывая интересы и паттерны поведения пользователей социальных сетей.
Многоуровневая кластеризация также продемонстрировала наличие микросообществ, объединённых по интересам или, например, региональному признаку. Это подтверждает оправданность применения новых методик сегментирования с использованием лингвистического анализа.
Несмотря на значимость полученных результатов, исследование обладает рядом ограничений, которые необходимо учитывать при интерпретации выводов и планировании дальнейших исследований:
- Во-первых, проанализированная выборка составила 2 161 пользователя, что относительно невелико по сравнению с общим количеством подписчиков сообщества «Москвич» (более 32 тысяч). Это могло повлиять на представительность кластеров и полноту отражения всей структуры интересов аудитории бренда.
- Во-вторых, лингвистический анализ охватывал только текстовые публикации, тогда как значительная часть пользовательского контента в соцсетях представлена фотографиями, видео и аудиоматериалами, отличающимися по структуре и смысловому наполнению.
- В-третьих, применяемые методы автоматической обработки текста, включая процедуру очистки и лемматизацию, могут терять часть лингвистических нюансов, особенно в случаях использования сленга, неформальных выражений, региональных языковых особенностей и многозначных слов.
- В-четвёртых, алгоритмы векторизации и кластеризации TF-IDF и KMeans предполагают определённую жёсткость деления пользователей, что может приводить к потере межгрупповых пересечений и не учитывать "размытые" границы между сегментами, естественно характерные для социальных сетей.
Осознание этих ограничений позволяет рассматривать результаты исследования как отправную точку для дальнейших улучшений, в том числе расширения выборки, внедрения мультиканального анализа, дополнения моделей мультимодальными данными и использования более гибких алгоритмов кластеризации.
Таким образом, несмотря на отдельные методологические и технические ограничения, исследование подтверждает высокую перспективность и актуальность предложенного психографического подхода к сегментации цифровых аудиторий.
5. Заключение. Проведённое исследование продемонстрировало эффективность применения методов TF-IDF векторизации и кластеризации текстового контента для сегментации пользователей социальных сетей по психографическим (и поведенческим) признакам. Разработанная авторская методика позволила структурировать не только крупные сегменты аудитории, но и выявить внутренние микрокластеры, дающие более глубокое понимание потребительских мотиваций и интересов.
Применение данной методики может быть рекомендовано как перспективное направление для компаний, желающих оптимизировать маркетинговые коммуникации в цифровых каналах, а также для исследователей в области анализа больших данных и поведения пользователей в социальных медиа.
В дальнейшем планируется расширение выборки, проведение исследований над другими сегментами аудитории и апробация дополнительных моделей машинного обучения и NLP для более точной сегментации и интерпретации результатов.
Источники:
2. Ивахин Д. Е., Андиева Е. Ю. Автоматический анализ текста для выявления профессиональных навыков: гибридный подход на основе TF-IDF и нейросетевых эмбеддингов // Вестник науки. – 2025. – № 4. – c. 685-692.
3. Кириллова Е. Н. Ремесленная мастерская в пространстве средневекового города (по «Книге ремесел» Парижа) // Известия Уральского федерального университета. Сер. 2: Гуманитарные науки. – 2019. – № 4. – c. 29-38. – doi: 10.15826/izv2.2019.21.4.065.
4. Кравченко Ю.А., Мансур А.М., Мохаммад Ж. Х. Векторизация текста с использованием методов интеллектуального анализа данных // Известия ЮФУ. Технические науки. – 2021. – № 2.
5. Крайнов А. Л. Цифровая идентичность как условие бытия человека в цифровом обществе // Известия Саратовского университета. Новая серия. Серия: Философия. Психология. Педагогика. – 2024. – № 2. – c. 137-141.
6. Кузеванова А. Л. Торговля в средневековой Руси: динамика ценностных принципов (социологический анализ) // Среднерусский вестник общественных наук. – 2010. – № 4. – c. 60-65. – url: https://cyberleninka.ru/article/n/torgovlya-v-srednevekovoy-rusi-dinamika-tsennostnyh-printsipov-sotsiologicheskiy-analiz.
7. Москвич: официальное сообщество завода. [Электронный ресурс]. URL: https://vk.com/zavodmoskvich (дата обращения: 20.11.2025).
8. Муравьева Л. А. Российское торговое предпринимательство (1725–1761 гг.) // Финансы и кредит. – 2008. – № 36. – c. 64-73. – url: https://cyberleninka.ru/article/n/rossiyskoe-torgovoe-predprinimatelstvo-1725-1761-gg.
9. Парето В. Учебник политической экономии. / В. Парето; пер. с фр. А. А. Зотов, В. Л. Силаева; предисл. В. С. Автономова. - М.: РИОР; ИНФРА-М, 2016. – 471 c.
10. Ратманский А. В., Романович В. К. Сегментирование рынка как важный инструмент разработки маркетинговой стратегии // Экономические системы. – 2025. – № 2. – c. 149-157. – url: https://cyberleninka.ru/article/n/segmentirovanie-rynka-kak-vazhnyy-instrument-razrabotki-marketingovoy-strategii.
11. Сэй Ж.-Б. Трактат по политической экономии. [Электронный ресурс]. URL: https://lc.elima.ru/lib/?id=89 (дата обращения: 14.11.2025).
12. Слоун А. П. Мои годы в General Motors. - М.: Эксмо, 2021. – 640 c.
13. Смит А. Исследование о природе и причинах богатства народов. / А. Смит; пер. с англ. П. Н. Клюкина. - М.: Эксмо, 2023. – 1056 c.
14. Старовойтова Я.Ю., Фёдоров М.В. Эволюция и концепции сегментации рынка // Journal of New Economy. – 2010. – № 3. – c. 17-23. – url: https://cyberleninka.ru/article/n/evolyutsiya-i-kontseptsii-segmentatsii-rynka.
15. Форд Г. Моя жизнь, мои достижения. - М.: Эксмо, 2022. – 267 c.
16..ChatGPT (версия 4.1): веб-сервис для обработки естественного языка. [Электронный ресурс]. URL: https://chat.openai.com/ (дата обращения: 06.12.2025).
17. Сегалович И., Титов В. MyStem: программа для морфологического анализа текста на русском языке. Яндекс. [Электронный ресурс]. URL: https://yandex.ru/dev/mystem/ (дата обращения: 18.11.2025).
18. Bird S., Loper E., Klein E. NLTK: Natural Language Toolkit. [Электронный ресурс]. URL: https://www.nltk.org/ (дата обращения: 02.12.2025).
19. C. da Costa-Luis da Costa-Luis C. tqdm: a fast, extensible progress bar for Python and CLI. [Электронный ресурс]. URL: https://tqdm.github.io/ (дата обращения: 09.11.2025).
20. Florido-Benítez L. Generative artificial intelligence: a proactive and creative tool to achieve hyper-segmentation and hyper-personalization in the tourism industry // International Journal of Tourism Cities. – 2024. – № 1. – p. 83-103.
21. Harris C. R. NumPy: the fundamental package for scientific computing with Python. [Электронный ресурс]. URL: https://numpy.org/ (дата обращения: 11.12.2025).
22. Hartmann J., Netzer O. Natural Language Processing in Marketing // Artificial Intelligence in Marketing. – 2023. – p. 191–215.
23. Huang S. Exploring the Influence of Natural Language Processing Technology on Marketing Strategy Innovation Management in Emerging Markets for Multinational Corporations // Journal of Logistics, Informatics and Service Science. – 2024. – № 3.
24. Hunter J. D. Matplotlib: visualization with Python. [Электронный ресурс]. URL: https://matplotlib.org/ (дата обращения: 25.11.2025).
25. McKinney W. Pandas: powerful Python data analysis toolkit. [Электронный ресурс]. URL: https://pandas.pydata.org/ (дата обращения: 30.11.2025).
26. Pedregosa F. Scikit-learn: machine learning in Python. [Электронный ресурс]. URL: https://scikit-learn.org/ (дата обращения: 04.12.2025).
27. Python 3 documentation. collections: high-performance container datatypes. [Электронный ресурс]. URL: https://docs.python.org/3/library/collections.html (дата обращения: 16.11.2025).
28. Python 3 documentation. logging: logging facility for Python. [Электронный ресурс]. URL: https://docs.python.org/3/library/logging.html (дата обращения: 22.11.2025).
29. Python 3 documentation. os: miscellaneous operating system interfaces. [Электронный ресурс]. URL: https://docs.python.org/3/library/os.html (дата обращения: 10.12.2025).
30. Python 3 documentation. re: regular expression operations. [Электронный ресурс]. URL: https://docs.python.org/3/library/re.html (дата обращения: 28.11.2025).
31. Reitz K. Requests: HTTP for Humans. [Электронный ресурс]. URL: https://requests.readthedocs.io/ (дата обращения: 07.12.2025).
32. Cambia; Queensland University of Technology. The Lens: patent and scholarly literature database. [Электронный ресурс]. URL: https://www.lens.org/ (дата обращения: 19.11.2025).
33. Timoshenko A., Hauser J. R. Identifying Customer Needs from User-Generated Content // Marketing Science. – 2019. – № 1. – p. 1-20. – doi: 10.1287/mksc.2018.1123.
34. Taylor C. Ray, Tedlow R. S. New and Improved: The Story of Mass Marketing in America // Journal of Marketing. – 1994. – № 3. – p. 123.
35. Wedel M. Market Segmentation: Conceptual and Methodological Foundations / M. Wedel, W. Kamakura. Dordrecht: Kluwer Academic Publishers, 1999
Страница обновлена: 25.07.2026 в 19:40:39
Download PDF | Downloads: 10
Consumer segmentation based on TF-IDF text clustering in social networks
Artyunin A.D.Journal paper
Marketing and marketing research
Volume 31, Number 2 (April-June 2026)
Abstract:
The article presents an approach to consumer psychographic segmentation based on clusterization of text data published by users on the social network VKontakte. A pilot study of the behavior of members of the official Moskvich brand community was conducted. It was based on application of natural language processing tools (TF-IDF, lemmatization, and machine learning). As a result, the article identifies consumer stable clusters, ranging from groups focused on congratulatory and emotional topics to segments involving commercial and club-related activities.
The article discusses the prospects of applying this methodology to enhance the effectiveness of marketing communications, as well as the limitations of the current study related to the need for further expansion and refinement of the sample.
Keywords: consumer segmentation, NLP, TF-IDF, text analysis, big data, marketing
JEL-classification: M30, M31, C38, C55, C88
References:
Bird S., Loper E., Klein E. NLTK: Natural Language Toolkit. Retrieved December 02, 2025, from https://www.nltk.org/
C. da Costa-Luis da Costa-Luis C. tqdm: a fast, extensible progress bar for Python and CLI Retrieved November 09, 2025, from https://tqdm.github.io/
Cambia; Queensland University of TechnologyThe Lens: patent and scholarly literature database. Retrieved November 19, 2025, from https://www.lens.org/
Florido-Benítez L. (2024). Generative artificial intelligence: a proactive and creative tool to achieve hyper-segmentation and hyper-personalization in the tourism industry International Journal of Tourism Cities. 11 (1). 83-103.
Ford G. (2022). My life, my achievements
Harris C. R. NumPy: the fundamental package for scientific computing with Python. Retrieved December 11, 2025, from https://numpy.org/
Hartmann J., Netzer O. (2023). Natural Language Processing in Marketing Artificial Intelligence in Marketing. 191–215.
Huang S. (2024). Exploring the Influence of Natural Language Processing Technology on Marketing Strategy Innovation Management in Emerging Markets for Multinational Corporations Journal of Logistics, Informatics and Service Science. 11 (3).
Hunter J. D. Matplotlib: visualization with Python. Retrieved November 25, 2025, from https://matplotlib.org/
Ivakhin D. E., Andieva E. Yu. (2025). Automatic Text Analysis for Identifying Professional Skills: A Hybrid Approach Based on TF-IDF and Neural Network Embeddings. Vestnik nauki. (4). 685-692.
Kirillova E. N. (2019). Craft Workshops in the Space of a Medieval City (According to Livre des Métiers of Paris). Izvestiya Uralskogo federalnogo universiteta. Ser. 2: Gumanitarnye nauki. 21 (4). 29-38. doi: 10.15826/izv2.2019.21.4.065.
Kravchenko Yu.A., Mansur A.M., Mokhammad Zh. Kh. (2021). Text Vectorization Using Data Mining Methods. IZVESTIYA SFedU. ENGINEERING SCIENCES. (2).
Kraynov A. L. (2024). Digital Identity as a Condition of Human Existence in a Digital Society. Proceedings of the Saratov University. New series. Series: Philosophy. Psychology. Pedagogy. (2). 137-141.
Kuzevanova A. L. (2010). Torgovlya v srednevekovoy Rusi: dinamika tsennostnyh printsipov (sotsiologicheskiy analiz). Srednerusskiy vestnik obschestvennyh nauk. (4). 60-65.
McKinney W. Pandas: powerful Python data analysis toolkit. Retrieved November 30, 2025, from https://pandas.pydata.org/
Muraveva L. A. (2008). Russian commercial entrepreneurship (1725-1761). Finance and credit. (36). 64-73.
Pareto V. (2016). Textbook of Political Economy
Pedregosa F. Scikit-learn: machine learning in Python. Retrieved December 04, 2025, from https://scikit-learn.org/
Python 3 documentation. collections: high-performance container datatypes. Retrieved November 16, 2025, from https://docs.python.org/3/library/collections.html
Python 3 documentation. logging: logging facility for Python. Retrieved November 22, 2025, from https://docs.python.org/3/library/logging.html
Python 3 documentation. os: miscellaneous operating system interfaces. Retrieved December 10, 2025, from https://docs.python.org/3/library/os.html
Python 3 documentation. re: regular expression operations. Retrieved November 28, 2025, from https://docs.python.org/3/library/re.html
Ratmanskiy A. V., Romanovich V. K. (2025). Modern Methods of Developing an Organization’s Financial Strategy. Economic systems. (2). 149-157.
Reitz K. Requests: HTTP for Humans. Retrieved December 07, 2025, from https://requests.readthedocs.io/
Sloun A. P. (2021). My years at General Motors
Smit A. (2023). An Inquiry into the Nature and Causes of the Wealth of Nations
Starovoytova Ya.Yu., Fyodorov M.V. (2010). Evolution and concepts of market segmentation. Journal of New Economy. (3). 17-23.
Taylor C. Ray, Tedlow R. S. (1994). New and Improved: The Story of Mass Marketing in America Journal of Marketing. 58 (3). 123.
Timoshenko A., Hauser J. R. (2019). Identifying Customer Needs from User-Generated Content Marketing Science. 38 (1). 1-20. doi: 10.1287/mksc.2018.1123.
Wedel M. Market Segmentation: Conceptual and Methodological Foundations / M. Wedel, W. Kamakura. Dordrecht: Kluwer Academic Publishers, 1999