Сегментация клиентов в сфере интернет-торговли с использованием методов машинного обучения
Русских Т.Н.1 ![]() , Соколова П.И.1
, Соколова П.И.1 ![]()
1 Орловский государственный университет им. И.С. Тургенева, Орел, Россия
Скачать PDF | Загрузок: 14
Статья в журнале
Креативная экономика (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 20, Номер 5 (Май 2026)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=91553405
Аннотация:
Сегментация в настоящее время является важнейшим инструментом для понимания потребностей клиентов в сфере интернет-торговли. Она позволяет повышать лояльность покупателей, увеличивает метрики удержания клиентов, обеспечивает разработку эффективных маркетинговых решений. В работе рассмотрены основные критерии сегментации, проведен обзор авторских подходов к решению задачи сегментации, результатов эмпирических исследований. Предложена методология сегментации клиентов с использованием методов машинного обучения. Программно реализовано решение задач исследовательского анализа и сегментации клиентской базы интернет-магазина. В качестве математического обеспечения выбраны метод Kmeans (к-средних), MiniBatchKMeans, метод Fuzzy c-Means (нечетких к-средних), DBSCAN. Произведена оценка качества результатов сегментации с использованием метрик кластеризации, построены портреты клиентов. Полученные выводы и результаты исследования обосновывают возможность использования предложенного инструментария в качестве математического обеспечения систем бизнес-аналитики
Ключевые слова: клиентская аналитика, сегментация, кластеризация, метрики
JEL-классификация: C38, M31, C31, C55, D12
Введение
В современных условиях развития интернет-торговли сегментирование покупателей выступает одной из ключевых задач клиентской аналитики. Она позволяет выявлять реальные потребности клиентов в товарах и услугах, обеспечивает разработку маркетинговых стратегий и персонализированных предложений, повышающих доходность компаний.
Проведенный анализ литературы показал, что авторы дают различные трактовки понятия сегментирования рынка и клиентов. Бур-Жуа Е.И., Романович В.К. под сегментированием рынка понимают стратегию маркетинга, направленную на идентификацию и изучение поведения потребителей со схожими характеристиками, предпочтениями и поведением [6, С. 26]. Горбачёва А.А., Ильяшенко С.Б. определяют сегментирование как процесс разделения рынка на определенные сегменты по различным признакам [10, C. 23]. В работе [14, C.144] авторы Куликова О.М., Суворова С.Д. под процессом сегментирования аналогично понимают процесс разделения рынка на группы по параметрам и реакциям на маркетинговые стратегию, отмечая целевую составляющую – максимальное удовлетворение запросов потребителей в отношении предлагаемых категорий товаров и услуг.
В контексте рассматриваемой предметной области под сегментацией будем понимать процесс разделения покупателей (клиентской базы) на группы c общими характеристиками и потребностям в определенных товарах.
Ключевой составляющей процесса сегментирования является выбор системы критериев. В маркетинге, как правило, выделяют четыре группы критериев: географические, социально-демографические, поведенческие, психографические [5, 6, 10, 12]. Приведенные группы критериев могут применяться и для сегментации клиентов интернет-магазинов. Так, например, сегментация по географическим критериям актуальна для интернет-магазинов, имеющих пункты выдачи товаров и филиалы в разных локациях. Социально-демографические критерии позволяют предсказывать сумму среднего чека и платежеспособность клиентов, адаптировать интерфейс приложений и разработку рекомендаций под определенные сегменты покупателей. Поведенческие критерии способствуют анализу лояльности покупателей к брендам, чувствительности покупателей к ценообразованию по основным категориям приобретаемых товаров. Психографические критерии, в первую очередь, позволяют персонализировать контент.
Приведем содержательное описание групп критериев.
1. Географические критерии: регион проживания, определяющий численность, плотность населения, тип местности, климатические условия. Доступность, стоимость и сроки доставки напрямую зависят от региона проживания покупателей интернет-магазина.
2. Социально-демографические критерии: пол, возраст, семейное положение, национальность, образование, доход, вид деятельности. Сегментирование по социально-демографическим критериям способствует разработке маркетинговых стратегий под разные социальные группы покупателей. Сегментация по доходу и роду деятельности позволяет оценить платежеспособность покупателей для формирования предложения товаров.
3. Поведенческие критерии: предпочтения, частота покупок, лояльность к бренду, чувствительность к изменению цен, поведение на сайте. В целом сегментация по данной группе критериев позволяет разрабатывать программы повышения лояльности, предлагающие бонусы и акции [6, 12].
4. Психографические критерии: интересы, ценности, мнения о покупках. Сегментирование на основе психографических критериев выявляет скрытые потребности покупателей и представляет собой более глубокий уровень анализа.
Сегментация покупателей в сфере интернет-торговли позволяет решить ряд ключевых задач, к котором можно отнести: повышение уровня удовлетворенности покупателей товарами, разработку маркетинговых стратегий для каждого сегмента покупателей, повышение лояльности целевой аудитории, снижение оттока покупателей и повышение метрик удержания клиентов, увеличение объемов продаж товаров, выстраивание долгосрочных взаимоотношений с покупателями и другие [5, 10, 19, 20].
Целью исследования является разработка методологии сегментации клиентов интернет-магазина, обеспечивающей поддержку принятия маркетинговых решений.
Научная новизна предлагаемой методики заключается в разработке и обосновании авторской методологии сегментации клиентов интернет-магазина на основе применения различных современных технологий (библиотек языка программирования Python) и методов машинного обучения без учителя (Kmeans (к-средних), MiniBatchKMeans, метод Fuzzy c-Means (нечетких к-средних), DBSCAN) с последующей оценкой качества кластеризации и выбором оптимальной сегментации для имеющейся выборки клиентских данных. В отличие от существующих авторских подходов к решению проблемы сегментации, основанных преимущественно на методах RFM-анализа и классическом методе к-средних, предлагаемая методология с использованием модификаций метода к-средних и метода DBSCAN обеспечивает принятие эффективных решений по разработке меркетинговых стратегий в условиях неоднородных клиентских данных с присутствием «шума».
Авторская гипотеза построена на предположении, что в условиях анализа неоднородных клиентских данных с присутствием аномальных наблюдений применение отдельных классических методов кластеризации не обеспечивает построение оптимальной сегментации в пространстве признаков в терминах метрик компактности и отделимости кластеров.
Методология исследования опирается на анализ клиентских данных интернет-магазина, реализацию процедур подготовки данных (обработка аномальных наблюдений, пропусков, устранение дубликатов), построение и сравнительный анализ моделей машинного обучения с использованием метрик кластеризации. Практическая реализация основных задач выполнена с использованием открытых библиотек языка программирования Python. Полученные результаты исследования будут использоваться в качестве математического обеспечения разрабатываемого авторами сервиса клиентской аналитики в сфере электронной коммерции. Для достижения цели исследования проведен обзор и анализ авторских публикаций, посвященных решению задачи сегментации.
Основная часть
В работах отечественных специалистов рассматриваются различные аспекты задачи сегментации клиентов [4, 11, 13, 16, 17], однако большее число работ носит теоретический характер [1, 5, 7, 8, 14, 18]. Авторы приводят критерии и задачи сегментации, делают обзор математического инструментария, и только отдельные исследования посвящены описанию эмпирических результатов. В качестве методов сегментации предлагается использовать экспертные методы, многомерное ранжирование, регрессионный, факторный анализ, кластеризацию, ABC-анализ, RMF-анализ, MRMF-анализ. В работе [20] Цой М.Е., Щеколдин В.Ю., Лежнина М.Н. отмечают, например, недостатки RMF-анализа, и обосновывает возможность их устранения в рамках реализации модифицированного RFM-анализа.
В таблице 1 приведены результаты обзора авторских подходов к решению задачи сегментации [1-3, 9, 15, 20, 21].
Таблица 1
Обзор авторских подходов к решению задачи сегментации потребителей
|
Авторы
|
Задача
|
Методы
|
|
Алимова
М.С., Василак Р.В. [1]
|
Сегментация пользователей
транспортных услуг
|
Опрос респондентов,
факторный анализ, самоорганизующиеся карты Кохонена
|
|
Анишкина
В.Н., Сафаров Н.И. [2]
|
Сегментация покупателей в
розничной торговли
|
Метод к-средних
|
|
Арефьева
С.Д. [3]
|
Сегментация
клиентов на основе синтетических данных
|
Метод к-средних
|
|
Гончарук
С.И., Воробьев С.П. [9]
|
Сегментация клиентов
интернет-магазина
|
RFM-анализ
|
|
Москвичев
Н.В., Бекасов Д.Е. [15]
|
Классификация
клиентов розничных сетей
|
RFM-анализ, сеть Кохонена
|
|
Цой М.Е.,
Щеколдин В.Ю., Лежнина М.Н. [20]
|
·
Сегментация
потребителей услуг транспортно-логистической компании
|
МRMF-анализ (модифицированный RFM-анализ)
|
|
Якушина
М.А., Манакова Е.В. [21]
|
Сегментация покупателей
женской одежды
|
Иерархическая кластеризация
|
При работе с большими данными решение задачи обучения без учителя, к которой относится задача сегментации, значительно усложняется. В условиях неоднородных данных и наличия аномальных наблюдений сложно найти оптимальный универсальный метод для сегментирования клиентов. Это обосновывает необходимость разработки комплексного подхода к решению задачи с использованием различных алгоритмов кластеризации.
Предлагаемая методология сегментации клиентов включает реализацию следующих этапов, отвечающих основным этапам решения задач машинного обучения:
1. Предобработка данных. Предобработка данных предполагает реализацию процедур, позволяющих подготовить имеющиеся «сырые» данные для моделирования (обучения моделей и прогнозирования). На данном этапе проводится анализ дубликатов, пропусков, аномальных наблюдений, реализуются процедуры очистки, трансформации и оптимизации данных.
2. Исследовательский анализ данных. Анализ описательных статистик, распределений признаков, корреляционный анализ, проверка статистических гипотез позволят сделать предварительные выводы о сегментах клиентов.
3. Визуализация клиентских данных с использованием методов снижения размерности.
4. Определение оптимального числа кластеров с использованием агломеративной кластеризации, метода локтя.
5. Кластеризация клиентов с использованием моделей машинного обучения.
6. Анализ метрик качества кластеризации, сравнительный анализ алгоритмов кластеризации.
7. Построение профилей клиентов.
8. Выбор оптимальной сегментации.
Сегментация не является статичным процессом в условиях активно развивающихся рынков, ввиду этого требуется проверка валидации построенных моделей, обучение моделей на новых клиентских данных.
Рассмотрим результаты решения задачи сегментации клиентов интернет-магазина с использованием различных моделей машинного обучения и библиотек языка программирования Python (Pandas, Numpy, Matplotlib, Seaborn, Sklearn и других). Сегментация проводилась на основе обезличенной выборки клиентских данных объемом 131706 записей. Датасет представлен качественными и количественными признаками: date – дата совершения сделки купли-продажи, customer_id – идентификатор клиента, transaction_id – идентификатор транзакции, sku_category – идентификатор категории, sku – артикул товара, category – наименование категории, quantity – проданное количество товара, sales_amount – сумма продаж, sales_one_prod – цена за единицу товара.
В качестве математического обеспечения сегментации выбраны метод Kmeans (к-средних), MiniBatchKMeans, метод Fuzzy c-Means (нечетких к-средних), DBSCAN.
В результате предобработки данных была сформирована новая выборка наблюдений из 22588 записей, сгруппированная по клиентам, с признаками: cnt_day_last_buy (количество дней, прошедших с даты последней покупки), cnt_all_buy (количество покупок, совершенных покупателем за все время), all_sales_buy (полная стоимость всех покупок клиента). Фрагмент выборки представлен на рисунке 1.
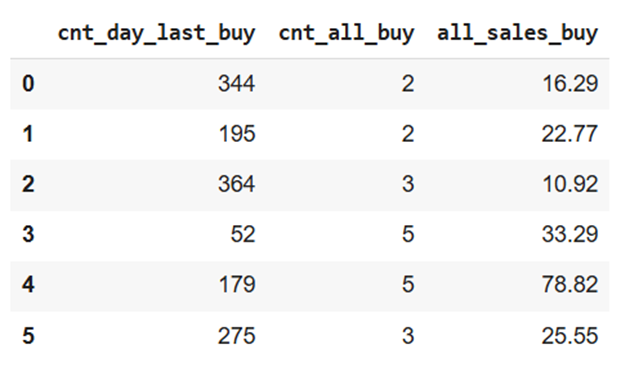
Рисунок 1. Фрагмент выборки
Источник: составлено авторами
Для решения поставленных задач признаки были стандартизированы. Используемые в исследовании алгоритмы кластеризации в качестве начальных параметров требуют задание числа кластеров. На рисунке 2 представлена дендрограмма, построенная на основе агломеративного метода кластеризации.
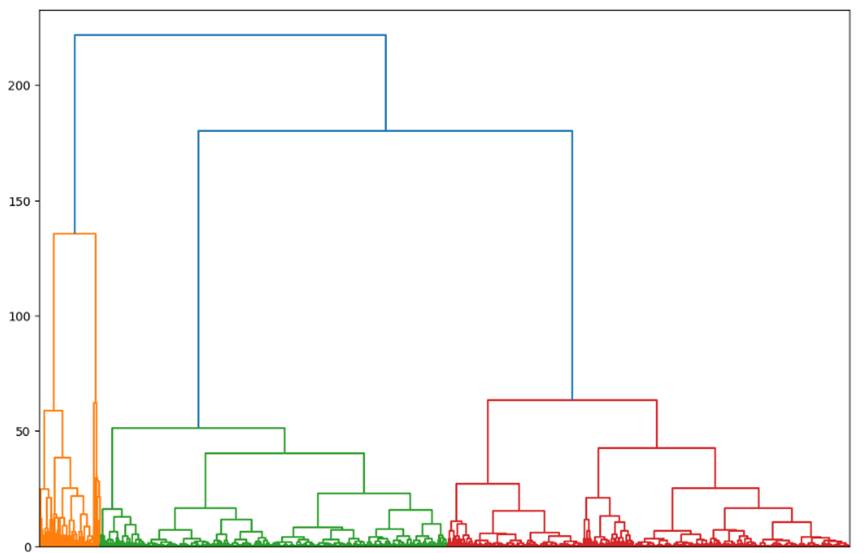
Рисунок 2. Дендограмма (агломеративная кластеризация)
Источник: составлено авторами
Анализ дендрограммы не дает однозначного ответа относительно оптимального числа кластеров, можно выдвинуть предположение о необходимости использования 3 или 4 кластеров для реализации кластерных алгоритмов. Дополнительно был проанализирован график функционала качества разбиения в рамках метода локтя, приведенный на рисунке 3.
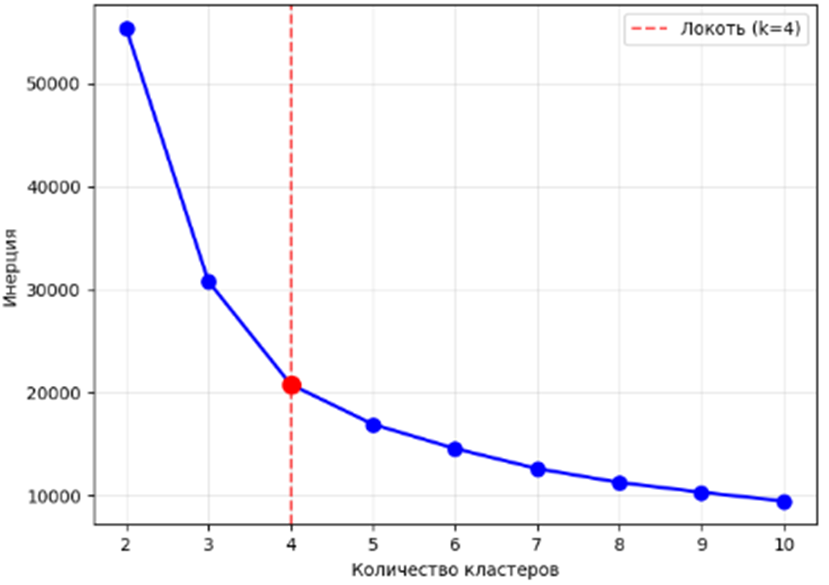
Рисунок 3. Метод локтя
Источник: составлено авторами
В качестве оптимального значения было выбрано 4 кластера.
Среди алгоритмов кластеризации первоначально был реализован метод Kmeans (к-средних). На рисунке 4 представлено распределение доли клиентов относительно покупок товаров внутри основных категорий.
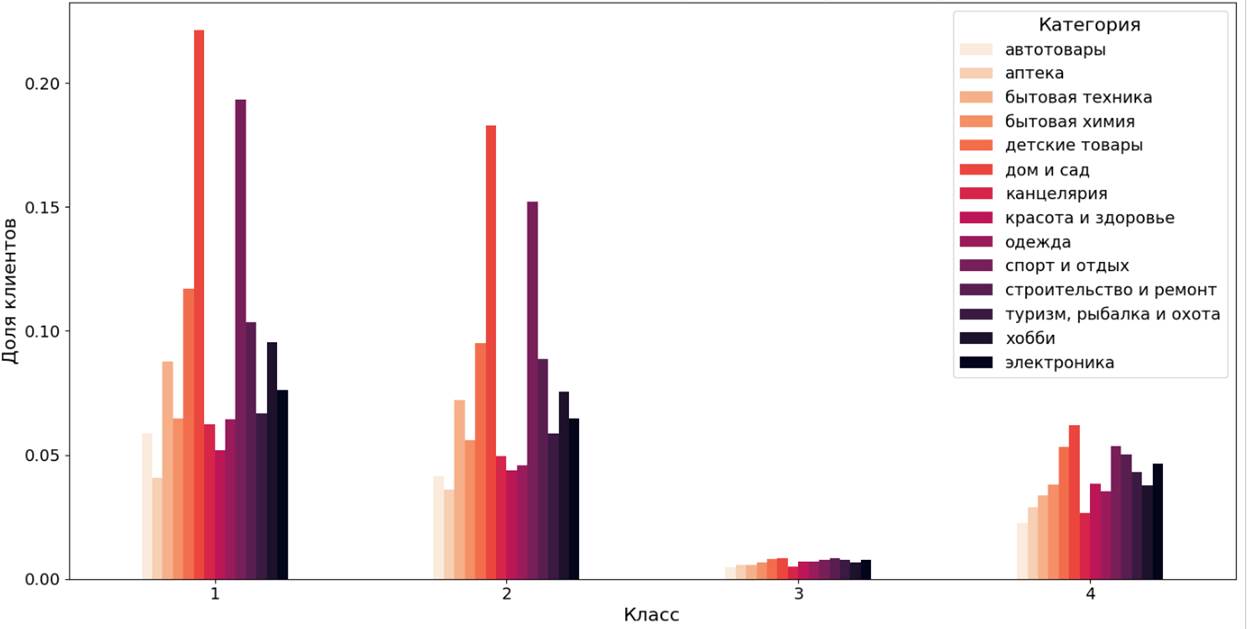
Рисунок 4. Распределение доли клиентских сегментов по отдельным категориям товаров (метод KMeans)
Источник: составлено авторами
Доли сегментов клиентов, выделенных с помощью метода KMeans, распределены в каждой категории равномерно. Преобладающие кластеры – кластер 1 и кластер 2. Среди популярных категорий клиентов этих групп можно выделить «дом и сад», «спорт и отдых» и «детские товары» (выбирают более 15% клиентов). Наименьшей популярностью пользуются категории товаров: «книги», «музыка и видео» и «товары для животных».
На рисунке 5 приведены результаты кластеризации с использованием метода MiniBatchKMeans, представляющего собой модификацию метода Kmeans (визуализация реализована с использованием метода снижения размерности).
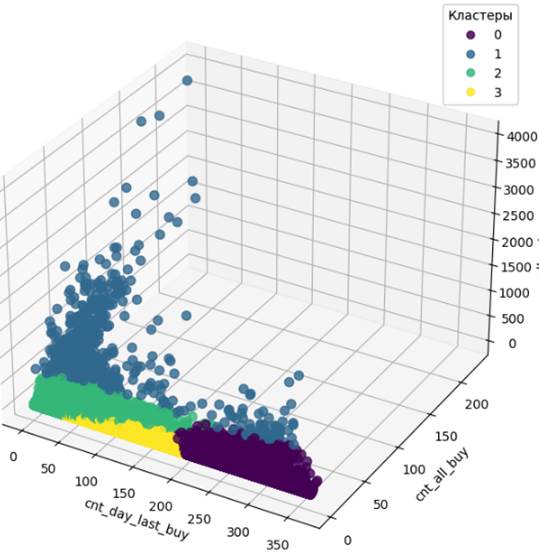
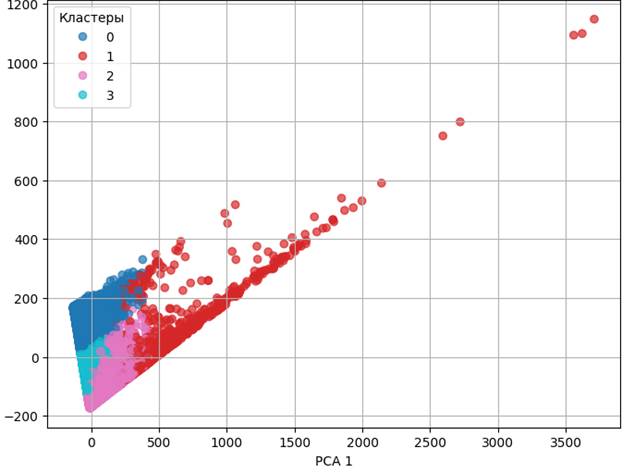
Рисунок 5. Результат кластеризации методом MiniBatchKMeans
Источник: составлено авторами
На рисунке 6 представлены профили клиентов для каждого кластера.
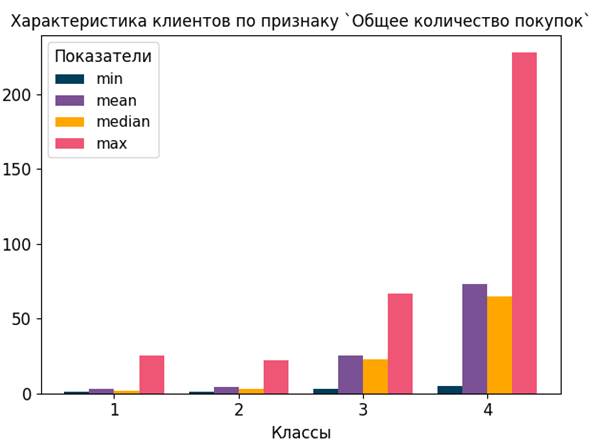
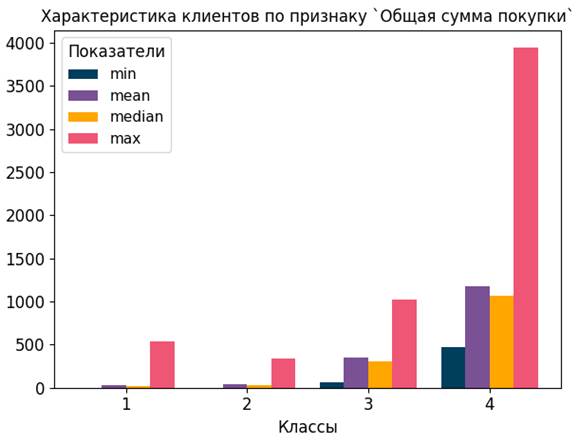
Рисунок 6. Характеристика клиентов по количеству и сумме покупок
Источник: составлено авторами
Кластер 1 – покупатели с низкой активностью, совершающие небольшое число покупок (до 10 единиц), последняя покупка была совершена более 9 месяцев назад. Класс 2 – клиенты с умеренной активностью (последняя покупка была совершена более 6 месяцев назад), заказы редкие (до 10 единиц товаров за все время), затраты на покупки в среднем составляют менее 100 д.е. Класс 3 – клиенты, совершающие небольшое число покупок (около 10 единиц), имеющие невысокие расходами (в среднем 120 д.е.). Класс 4 – наиболее ценные клиенты (последняя покупка в среднем не более месяца назад), совершающие много покупок (около 50 единиц), в среднем на общую сумму более 500 д.е.
На рисунке 7 представлено распределение доли клиентов относительно покупок товаров внутри основных категорий.
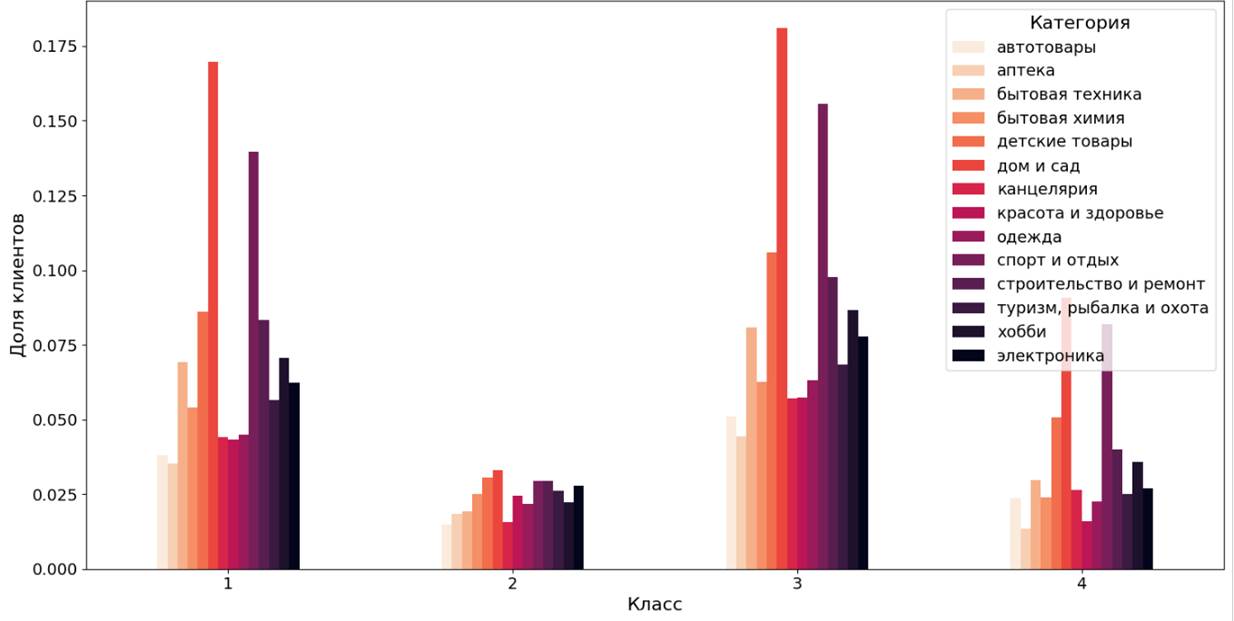
Рисунок 7. Распределение доли клиентских сегментов по отдельным категориям товаров (метод MiniBatchKMeans)
Во многих категориях товаров выделяются сегменты – класс 3, класс 1 и класс 4. Самыми востребованными категориями являются «дом и сад», «спорт и отдых» (выбирают более 12% клиентов из классов 3 и 1). Менее популярные категории, как и в предыдущем методе – «книги», «музыка и видео» и «товары для животных». Клиенты класса 2 в отличие от класса 4 чаще выбирают товары из категорий «аптека», «бытовая химия», «красота и здоровье», «туризм, рыбалка и охота» и «электроника».
На следующем этапе был реализован метод DBSCAN, который основан на концепции плотности точек данных в пространстве. Данный метод не требует заранее заданного количества кластеров, но качество работы алгоритма зависит от хорошо подобранных параметров: радиуса окрестности точки и минимального количества точек в ε-окрестности для классификации точек на корневую, граничную и шумовую.
Результаты реализации метода DBSCAN представлены на рисунке 8.
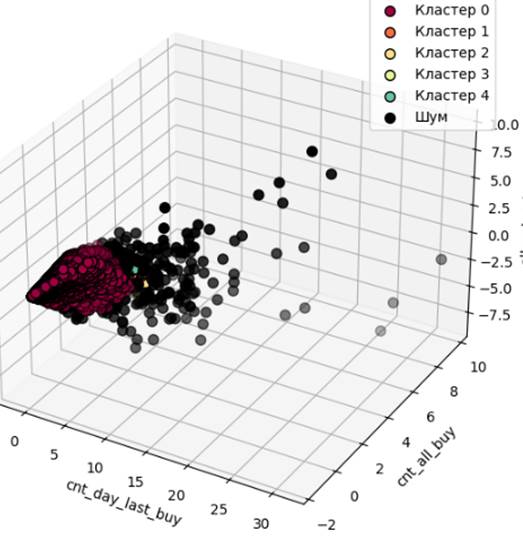
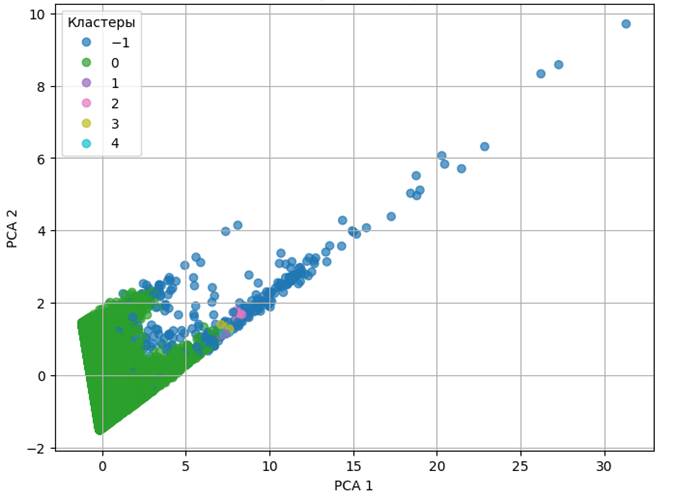
Рисунок 8. Результат кластеризации методом DBSCAN
Источник: составлено авторами
Для анализа профилей клиентов было построены распределения признаков по основным статистическим показателям внутри сегментов (рисунок 9).
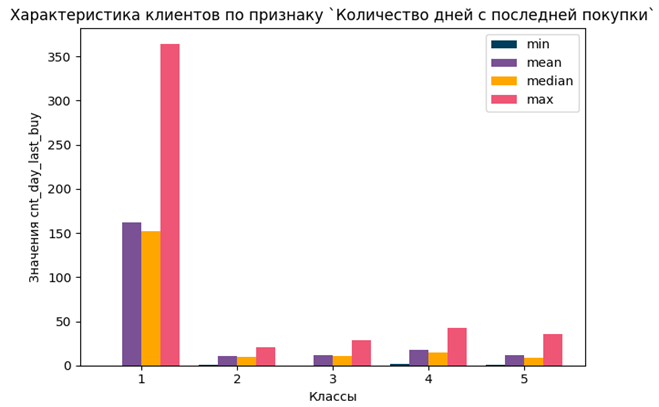
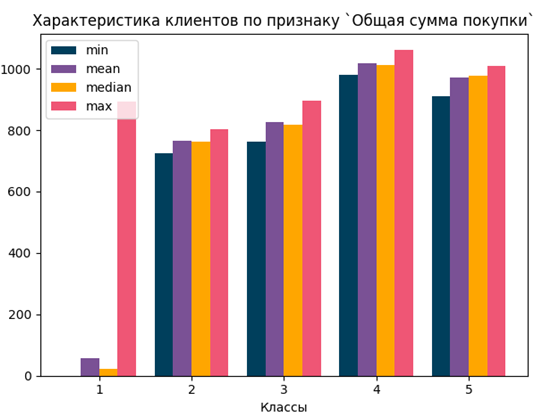
Рисунок 9. Характеристика клиентов по количеству дней с последней покупки и сумме покупок
Источник: составлено авторами
Недостатком метода DBSCAN является классификация большого числа точек пространства признаков как шумовых точек. На рисунке 10 представлено распределений долей клиентов по классам без шумовых точек.
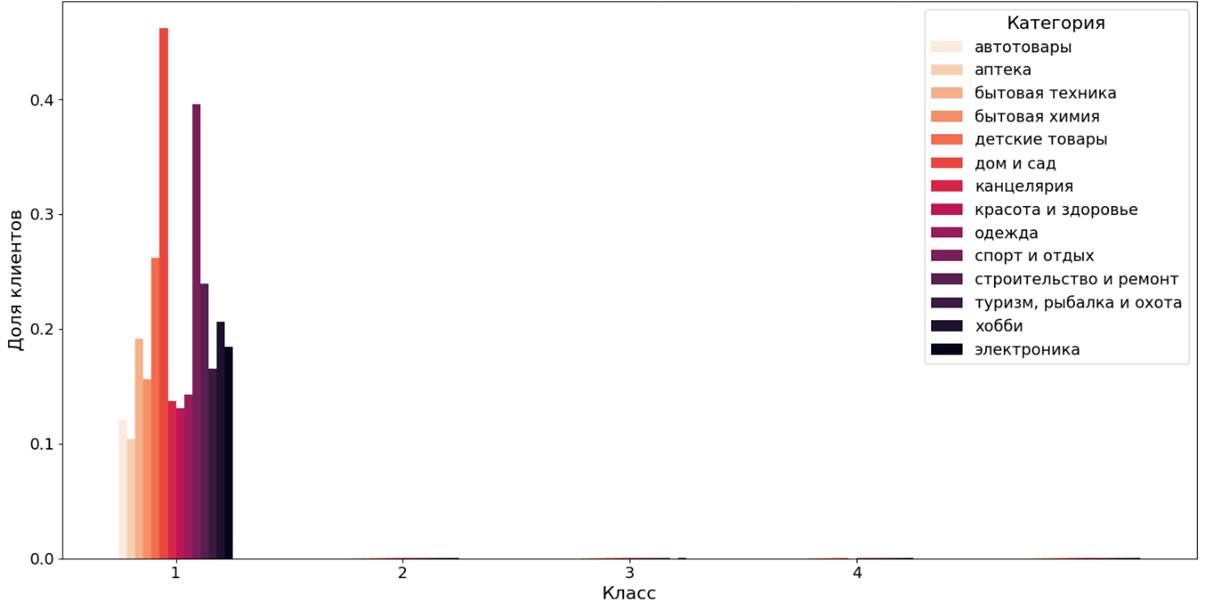
Рисунок 10. Распределение доли клиентских сегментов по категориям товаров (метод DBSCAN без учета шумовых точек)
Источник: составлено авторами
Из распределения видно, что среди категорий также выделяются две категории «сад и огород» и «спорт и отдых». Более 38% клиентов класса 1 выбирают именно эти категории. Вследствие неравномерного распределения клиентов по классам было построено распределение без класса шумовых точек (рисунок 11) и многочисленного класса 0.
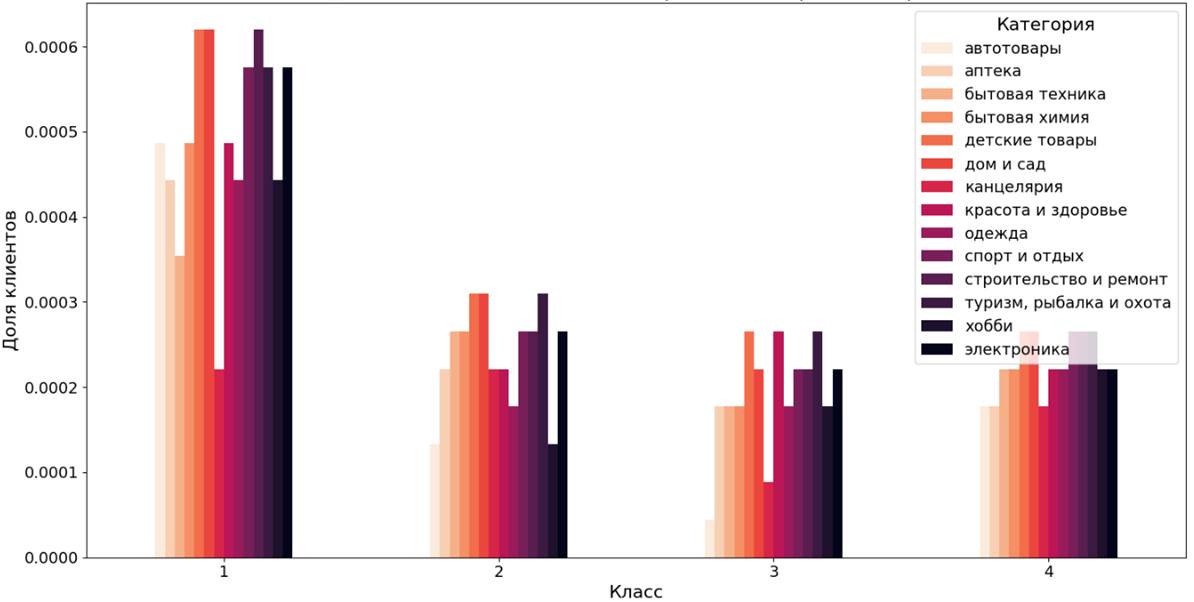
Рисунок 11. Распределение доли клиентских сегментов по категориям товаров (метод DBSCAN без учета шумовых точек и клиентов класса 0)
Источник: составлено авторами
Среди остальных классов наибольшей популярностью пользуются категории: «детские товары», «дом и сад», «спорт и отдых» и «продукты питания» (выбирают около 0,006% клиентов в классе 2).
Еще одним методом итеративной кластеризации является метод нечеткой кластеризации Fuzzy с-Means. Этот подход является расширением метода k-средних, позволяющим получить более гибкие результаты кластеризации, но он также требует заданное количество кластеров.
Для определения оптимального количества кластеров использовалась совокупность метрик оценки качества кластеризации (Fuzzy Partition Coefficient (FPS), энтропия разбиения (PE), индекс Кси-Бени (XB), индекс Дэвиса-Болдуина (DB)). Графики метрик представлены на рисунке 12. Исходя из полученных графиков, было выбрано 3 кластера. Распределение долей сегментов по категориям товаров представлено на рисунке 13.
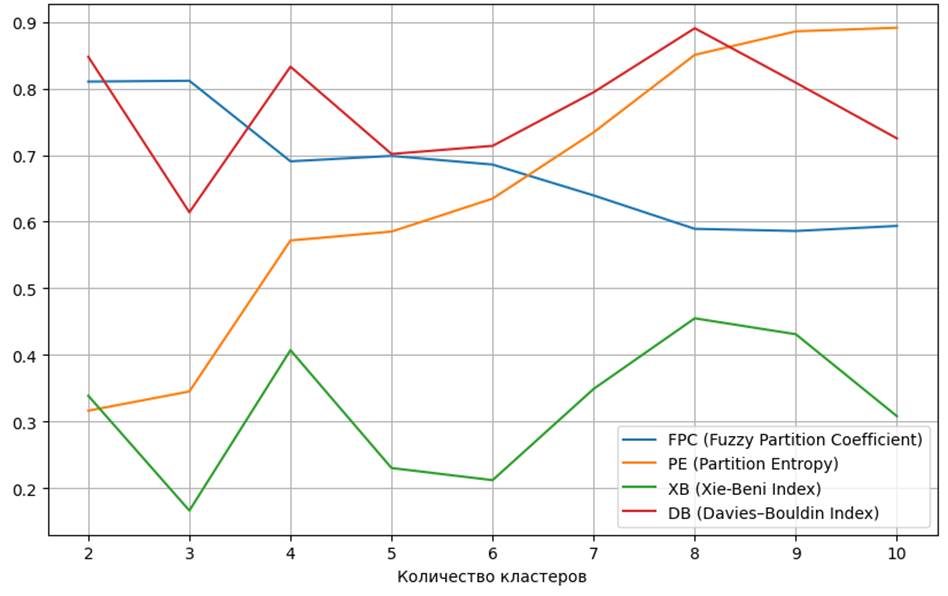
Рисунок 12. Графики метрик качества нечеткой кластеризации
Источник: составлено авторами
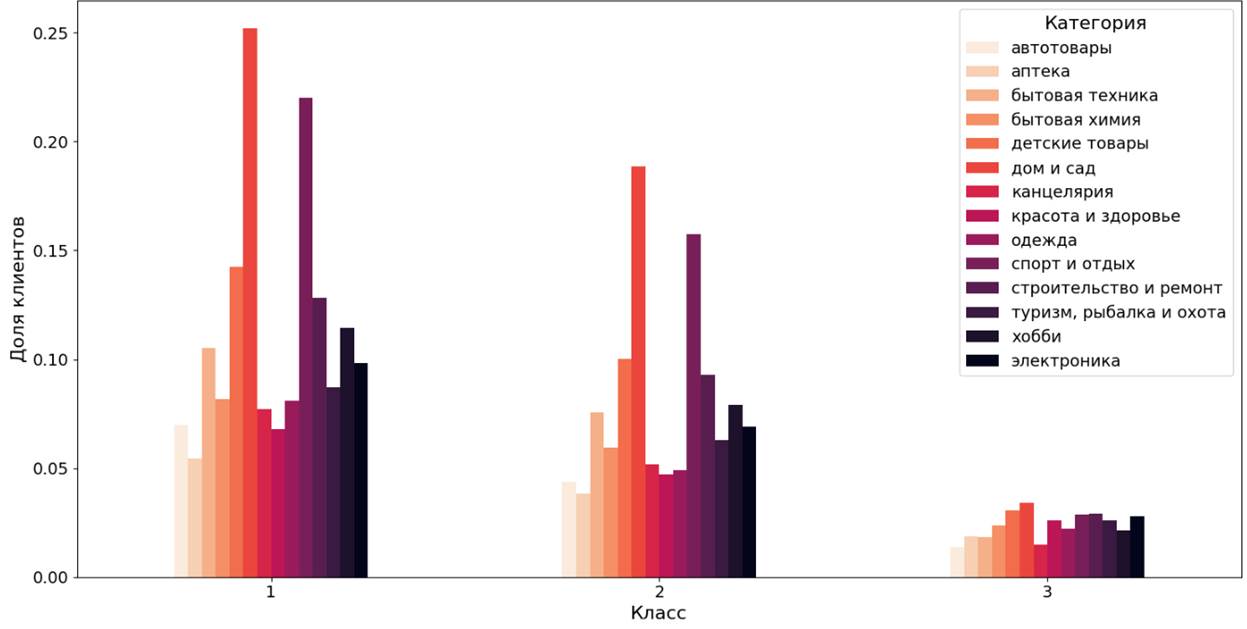
Рисунок 13. Распределение доли клиентских сегментов по категориям товаров (метод Fuzzy с-Means)
Источник: составлено авторами
Класс 1 включает клиентов, давно не совершающих покупки (в среднем последняя покупка была 9 месяцев назад). Предыдущие заказы данной группы в целом малочисленные с небольшой суммой выкупа. Класс 2 – недавние покупатели, которые ранее совершали малочисленные недорогостоящие покупки. Класс 3 представлен постоянными клиентами (последняя покупка в среднем около месяца назад), которые за все время купили около 30 единиц товаров и потратили более 700 д.е. Самыми популярными категориями товаров являются «дом и сад» и «спорт и отдых» (более 20% покупателей классов 1 и 2 в каждой категории). Среди клиентов всех классов меньше всего покупаются товары из категорий «книги», «музыка и видео», «товары для животных». Для класса 3 востребованными являются категории «дом и сад», «детские товары», «электроника», «спорт и отдых», «строительство и ремонт».
Для выбора оптимальной кластеризации была произведена оценка метрик: коэффициент силуэта, индекс Дэвиса-Болдуина, индекс Калинского-Харабаза. Результаты вычислений приведены в таблице 2.
Таблица 2
Сравнение метрик качества кластеризации реализуемых методов
|
Метрика
|
Метод
кластеризации
| |||
|
KMeans
|
MiniBatch
KMeans |
DBSCAN
|
Fuzzy с-Means
| |
|
Коэффициент силуэта
|
0.56
|
0.39
|
0.73
|
0.56
|
|
Индекс Калинского-Харабаза
|
22942.91
|
16600.20
|
1868.95
|
22956.75
|
|
Индекс Дэвиса- Болдуина
|
0.66
|
0.87
|
4.02
|
0.61
|
Источник: составлено авторами
Выводы. Метрика качества кластеризации позволяют выбрать оптимальную сегментацию. Метод DBSCAN имеет наибольшее значение метрики силуэта среди алгоритмов кластеризации, что означает хорошо разделённые сегменты. Однако для метода получены наихудшие значения метрик Калинского-Харабаза и Дэвиса-Болдуина. Метод DBSCAN выделил много шумовых точек, этим и обусловлены полученные результаты метрик. Алгоритм KMeans демонстрируют сбалансированные значения метрик Калинского-Харабаза и Дэвиса-Болдуина, при этом имеет более низкое значение метрики силуэта по сравнению с DBSCAN. Метод MiniBatchKMeans уступает во всех метриках, вероятно, из-за упрощённой оптимизации. На основе метрик можно сделать вывод, что наиболее предпочтительным алгоритмом для данной выборки являются KMeans.
Полученные результаты сегментации и построенные профили клиентов обосновывают возможность применения рассмотренных алгоритмов в качестве математического инструментария моделей систем бизнес-аналитики в сфере интернет-торговли.
Источники:
2. Анишкина В.Н., Сафаров Н.И. Кластеризация покупателей розничной торговли методом к-средних // XXIV Туполевские чтения (школа молодых ученых): материалы Международной молодёжной научной конференции. В 6-ти томах, Казань, 07-08 ноября 2019 года. Том IV. – Казань: ИП Сагиева А.Р. Казань, 2019. – c. 182-186.– url: https://elibrary.ru/item.asp?id=42409275.
3. Арефьева С.Д. Анализ клиентского поведения с использованием кластеризации и сегментации данных // Информационные технологии в строительных, социальных и экономических системах. – 2025. – № 2. – c. 63-66. – url: https://elibrary.ru/item.asp?id=82605636.
4. Бардина Н.Ю., Федюшин Н.А. Сегментация потребителей с помощью кластерного анализа // Новый университет. Серия Экономика и право. – 2015. – № 5. – c. 25-27. – url: https://elibrary.ru/item.asp?id=23823536.
5. Бельских Е.С., Романович В.К. // Матрица научного познания. – 2015. – № 2-1. – c. 104-110. – url: https://os-russia.com/SBORNIKI/MNP-2025-02-1.pdf.
6. Бур-Жуа Е.И., Романович В.К. Основные принципы сегментирования рынка // Символ науки: международный научный журнал. – 2025. – № 1-1. – c. 25-28. – url: https://elibrary.ru/item.asp?id=80259033.
7. Габбасова Ж.Р. Анализ проблем метода сегментирования потребителей // Modern Science. – 2021. – № 3-2. – c. 56-59. – url: https://elibrary.ru/item.asp?id=44924681.
8. Галямов А.Ф., Тархов С.В. Управление взаимодействием с клиентами коммерческой организации на основе методов сегментации и кластеризации клиентской базы // Вестник УГАТУ. – 2014. – № 4. – c. 149-156. – url: https://elibrary.ru/item.asp?id=22649259.
9. Гончарук С.И., Воробьев С.П. Описание RFM-анализа при сегментации клиентов интернет-магазина // Инновационная наука. – 2020. – № 2. – c. 59-62. – url: https://elibrary.ru/item.asp?id=42345983.
10. Горбачёва А.А., Ильяшенко С.Б. Сегментирование покупателей как инструмент развития торговых организаций // Профессорский журнал. Серия: Экономические науки. – 2024. – № 1. – c. 22-27. – url: https://cyberleninka.ru/article/n/segmentirovanie-pokupateley-kak-instrument-razvitanizatsiy.
11. Гречишникова Ю.Ю., Медведева О.С. Сегментация клиентов в маркетинговой деятельности IT-компании // Дневник науки. – 2023. – № 5. – c. 68. – doi: 10.51691/2541-8327_2023_5_4. .
12. Закускин С.В. Сегментация целевой группы на основании потребительских предпочтений // Креативная экономика. – 2021. – № 1. – c. 169-192. – doi: 10.18334/ce.15.1.111560.
13. Костанда А.В., Кужельная О.В., Парфенова Е.И. Основные тенденции развития потребительских предпочтений (сегментирование) ювелирной торговли на основе применения современных инструментов маркетинга // Экономика и управление народным хозяйством. – 2024. – № 19. – c. 97-105. – url: https://elibrary.ru/item.asp?id=60271944.
14. Куликова О.М., Суворова С.Д. Совершенствование подхода к процедуре сегментирования в современных рыночных условиях // Естественно-гуманитарные исследования. – 2024. – № 2. – c. 144-149. – url: https://elibrary.ru/item.asp?id=68591290.
15. Москвичев Н.В., Бекасов Д.Е. Метод автоматической классификации клиентов розничных торговых сетей на основе кластеризации // Политехнический молодежный журнал. – 2021. – № 1. – c. 5. – doi: 10.18698/2541-8009-2021-1-665.
16. Платонова А.С., Рыжкова М.Н. Применение машинного обучения для сегментации пользователей в маркетинговых исследованиях // РТС. – 2025. – № 3. – p. 47-53. – url: https://cyberleninka.ru/article/n/primenenie-mashinnogo-obucheniya-dlya-segmentatsii-polzovateley-v-marketingovyh-issledovaniyah.
17. Поляков В.А., Фомичева И.В. Новые подходы сегментации в маркетинге // Вестник Тульского филиала Финуниверситета. – 2020. – № 1. – c. 236-239. – url: https://elibrary.ru/item.asp?id=43140105.
18. Ратманский А.В., Романович В.К. Сегментирование рынка ка важный инструмент разработки маркетинговой стратегии // Экономические системы. – 2025. – № 2. – c. 149-157. – doi: 10.29030/2309-2076-2025-18-2-149-157.
19. Рожкова А.В., Степанова Э.В., Ступина А.А., Анисимов П.Е. Сегментирование потребителей новых товаров в условиях цифровой трансформации экономики // Вестник Алтайской академии экономики и права. – 2025. – № 4-2. – c. 336-344. – doi: 10.17513/vaael.4112.
20. Цой М.Е., Щеколдин В.Ю., Лежнина М.Н. Построение сегментации на основе модифицированного RFM-анализа для повышения лояльности потребителей // Российское предпринимательство. – 2017. – № 21. – c. 3113-3134. – url: https://elibrary.ru/item.asp?id=30711360.
21. Якушина М.А., Манакова Е.В. Типологизация потребительского поведения на рынке женской одежды города Москвы // Практический маркетинг. – 2011. – № 4. – c. 20-28. – url: https://elibrary.ru/item.asp?id=16225957.
Страница обновлена: 16.07.2026 в 09:59:54
Download PDF | Downloads: 14
Customer segmentation in e-commerce using machine learning methods
Russkikh T.N., Sokolova P.I.Journal paper
Creative Economy
Volume 20, Number 5 (May 2026)
Abstract:
Segmentation is currently the most important tool for understanding the needs of customers in e-commerce. It allows to increase customer loyalty and customer retention metrics. It ensures the development of effective marketing solutions. The article considers the main criteria of segmentation, provides an overview of the approaches to solving the problem of segmentation, and discusses the results of empirical research. A methodology for customer segmentation using machine learning methods is proposed. The solution of the tasks of research analysis and segmentation of the customer base of the online store is programmatically implemented. The K-Means, MiniBatchKMeans, Fuzzy C-Means, and DBSCAN methods were chosen as mathematical support. The quality of segmentation results was assessed using clustering metrics; and customer portraits were built. The conclusions and research results substantiate the possibility of using the proposed toolkit as mathematical support for business intelligence systems.
Keywords: client analytics, segmentation, clustering, metrics
JEL-classification: C38, M31, C31, C55, D12
References:
Alimova M.S., Vasilak R.V. (2025). Client Segmentation Using Software Tools for Modeling Information Systems and Data Processing. Scientific Journal of KubSAU. (210). 478-489. doi: 10.21515/1990-4665-210-047.
Anishkina V.N., Safarov N.I. (2019). Clustering of retail customers using the k-means method The 24th Tupolev Readings (School of Young Scientists). 182-186.
Arefeva S.D. (2025). Analysis of Customer Behavior Using Clustering and Data Segmentation. Informatsionnye tekhnologii v stroitelnyh, sotsialnyh i ekonomicheskikh sistemakh. (2). 63-66.
Bardina N.Yu., Fedyushin N.A. (2015). Segmentation Using Cluster Analysis. Novyy universitet. Seriya Ekonomika i pravo. (5). 25-27.
Belskikh E.S., Romanovich V.K. (2015). Designing an organization's strategy as a market segmentation. Matritsa nauchnogo poznaniya. (2-1). 104-110.
Bur-Zhua E.I., Romanovich V.K. (2025). Fundamental Principles of Market Segmentation. The Interntational scientific journal. 1 (1-1). 25-28.
Gabbasova Zh.R. (2021). Analysis of the problems of the consumer segmentation method. Modern Science. (3-2). 56-59.
Galyamov A.F., Tarkhov S.V. (2014). Customer Relationship Management of a Commercial Organization Based on Methods of Segmentation and Clustering of Customer Database. Vestnik UGATU. (4). 149-156.
Goncharuk S.I., Vorobev S.P. (2020). Description of RFM-Analysis for Segmentation of Clients of Online Store. Innovative science. (2). 59-62.
Gorbachyova A.A., Ilyashenko S.B. (2024). Customer Segmentation as a Tool for the Development of Trade Organizations. Professorskiy zhurnal. Seriya: Ekonomicheskie nauki. (1). 22-27.
Grechishnikova Yu.Yu., Medvedeva O.S. (2023). Segmentation of Customers in the Marketing Activity of the IT Company. Dnevnik nauki. (5). 68. doi: 10.51691/2541-8327_2023_5_4. .
Kostanda A.V., Kuzhelnaya O.V., Parfenova E.I. (2024). The Main Trends in the Development of Consumer Preferences (Segmentation) of the Jewelry Trade Based on the Use of Modern Marketing Tools. Economics and management of the national economy. (19). 97-105.
Kulikova O.M., Suvorova S.D. (2024). Improving the Approach to the Segmentation Procedure in Modern Market Conditions. Estestvenno-gumanitarnye issledovaniya. (2). 144-149.
Moskvichev N.V., Bekasov D.E. (2021). Method for Automatic Classification of Retail Chain Clients on the Basis of Clustering. Politekhnicheskiy molodezhnyy zhurnal. (1). 5. doi: 10.18698/2541-8009-2021-1-665.
Platonova A.S., Ryzhkova M.N. (2025). Primenenie mashinnogo obucheniya dlya segmentatsii polzovateley v marketingovyh issledovaniyakh RTS. (3). 47-53.
Polyakov V.A., Fomicheva I.V. (2020). New Segmentation Approaches in Marketing. Vestnik Tulskogo filiala Finuniversiteta. (1). 236-239.
Ratmanskiy A.V., Romanovich V.K. (2025). Modern Methods of Developing an Organization’s Financial Strategy. Economic systems. 18 (2). 149-157. doi: 10.29030/2309-2076-2025-18-2-149-157.
Rozhkova A.V., Stepanova E.V., Stupina A.A., Anisimov P.E. (2025). SEGMENTATION OF CONSUMERS OF NEW GOODS IN THE CONTEXT OF THE DIGITAL TRANSFORMATION OF THE ECONOMY. Bulletin of the Altai Academy of Economics and Law. (4-2). 336-344. doi: 10.17513/vaael.4112.
Tsoy M.E., Schekoldin V.Yu., Lezhnina M.N. (2017). Building Segmentation on the Basis of Modified RFM Analysis to Increase Customer Loyalty. Russian Journal of Entrepreneurship. 18 (21). 3113-3134.
Yakushina M.A., Manakova E.V. (2011). The Typology of Consumers’ Behavior on the Women Clothing Market of Moscow. Practical Marketing. (4). 20-28.
Zakuskin S.V. (2021). Segmentation of the target group based on consumer preferences. Creative Economy. 15 (1). 169-192. doi: 10.18334/ce.15.1.111560.