Методология оценки уровня и перспектив демографического развития в США
Максимцев И.А.1 ![]() , Костин К.Б.1
, Костин К.Б.1 ![]() , Малевич Ю.В.1
, Малевич Ю.В.1 ![]() , Кургина С.М.2
, Кургина С.М.2 ![]()
1 Санкт-Петербургский государственный экономический университет, Санкт-Петербург, Россия
2 Национальный исследовательский университет «Высшая школа экономики», Москва, Россия
Скачать PDF | Загрузок: 6
Статья в журнале
Экономика, предпринимательство и право (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 16, Номер 5 (Май 2026)
Аннотация:
В работе проанализированы результаты научных исследований ведущих отечественных и зарубежных экономистов, посвященных концепции повышения уровня демографии. Представлены результаты эконометрического и кластерного анализа, на основе которых сформирована универсальная авторская методология и методика оценки уровня демографического развития страны на примере США. Разработаны и представлены универсальные авторские предложения, направленные на повышение уровня демографии. Статья может быть полезна специалистам в области мировой экономики и международного бизнеса, а также исследователям, занимающихся непосредственно вопросами демографии
Ключевые слова: мировая экономика, эконометрика, МНК, демография, регрессионный анализ
JEL-классификация: C21, C32, C42, C51
Введение
За последнюю декаду в развитых странах, и в США в частности, наблюдается постепенное снижение уровня рождаемости населения. Так, в 2020 году средние число рождений на 1 женщину за всю её жизнь в США составил 1,64%. В 2021 году – 1,62%, в 2022 году – 1,65%, в 2023 году – 1,62%, в 2024 году – 1,60%, а к 2025 году этот коэффициент дошел до отметки в 1,59% [29]. Данная тема является актуальной как никогда, поскольку в развитых странах наблюдается отчетливо выраженная тенденция к уменьшению уровня рождаемости. Экономическая проблема заключается в потенциально отсроченном снижении уровня рабочей силы через 20 лет, что подтверждается демографическим провалом и, как следствие, может привести к затяжной рецессии. Данная социально-экономическая проблема вызвана такими факторами, как: изменения традиционной модели семьи, поскольку население в возрасте до 25-30 лет ставит в приоритет получение образование и построение карьеры. Кроме того, социально-экономическая нестабильность вследствие экономических кризисов и политических противоречий последних лет привела к тому, что многие американцы испытывают недоверие к власти в Еще одни немаловажный фактор, оказывающий отрицательное влияние на желание иметь детей – это рост стоимости жилья. Так, по данным ассоциации риэлторов (NAR), средняя стоимость жилья в Америке составляла 389 900 тыс. долл., а к 2024 году цена возросла на 13% и составила 442 500 тыс. долл. [28].
Цель исследования заключается в проведении эконометрического анализа уровня рождаемости США для выявления ключевых социально-экономических факторов, определяющих уровень рождаемости населения, а также разработки универсальных авторских предложений по повышению уровня рождаемости.
Научная новизна исследования заключается в разработке универсальной авторской демографической математической модели процессов воспроизводства населения на примере США, как безусловного мирового лидера по объему номинального ВВП, производительности труда, доходам на душу населения, индексам развития человеческого потенциала и качеству жизни, для дальнейшего прогнозирования уровня демографического развития.
В работе использованы такие методы научного познания, как статистический анализ, регрессионный анализ и кластерный анализ.
Гипотеза исследования состоит в том, что, по мнению авторов, уровень рождаемости определяется в первую очередь такими наиболее значимыми факторами, как ВВП на душу населения, уровнем безработицы, и процентом женщин с высшим образованием.
Вопросам демографических тенденций посвящены труды многих ученых-экономистов. Так, Филипенко А.А. в своей работе [21] исследует изменение переписи населения США не только как статистический срез, но и индикатор социально-экономических изменений.
Агибалова Е.Л. и Каржанова Н.В. в своей работе [1] анализируют две крупнейшие экономики – США и Китая для выявления макроэкономических, торговых и демографических трендов.
Александров А.Г. в своей работе [2] изучает современные демографические тенденции США при помощи анализа данных. Автор приходит к заключению, что отрицательная демографическая тенденция усиливает социальные противоречия в государстве, а политика борьбы с этим неэффективна. Алексеева Е.А. в своей работе [3] проводит исследование о влиянии преступности на уровень демографии в России и за рубежом, включая США. Петровская Н.Е. в своей работе [16] исследует демографический вопрос США в разрезе иммигрантов и предпринимательства. Лисовых Е.И. и Суркина Ф.Ж. в своей работе [12] рассматривают проблему демографии в контексте факторов, которые на неё влияют, а именно: особенности демографической политики, старение населения, динамику смертности, социальные программы поддержки семьи и миграционную политику.
Жунг Ю. в своей работе [35] рассматривает проблему рождаемости населения Южной Кореи с макроэкономической точки зрения. Зарубежные авторы Гуззо К., Маннирг В. и др. исследуют демографический вопрос в контексте нежелания молодых людей в США заводить детей [32]. Дэвид Н. в своей работе [27] исследует низкий уровень рождаемости США в контексте макроэкономических последствий, а именно влияние снижения уровня рождаемости на уровень жизни населения. Авторы Герузо М. и Спирс Д. [30] исследуют вероятность возвращения к стабильному росту рождаемости населения при нынешних социально-экономических условиях. Авторы Гобби П., Ханнуш А. и Росси П. в своей работе [38] исследуют отличия темпов снижения рождаемости в разных странах со схожим уровнем экономики и здравоохранения.
В приведенных статьях рассмотрены социально-экономические причины снижения глобального уровня рождаемости в развитых странах, к которым можно отнести: рост заработной платы и карьерных ожиданий у женщин, высшее образование, обеспеченность жильем, уровень безработицы и т.д. Спад рождаемости населения – системная проблема, которая влечет за собой социально-экономические последствия, а эти последствия, в свою очередь, приводят к финансовым и культурным изменениям, что не всегда является положительным.
Предварительный анализ данных
Для более четкого понимания данных, важным первоначальным этапом анализа является проверка взаимосвязи между эндогенными и экзогенными переменными. Для простоты восприятия в таблице 1 представлена краткая характеристика всех переменных и даны сокращенные названия, которые будут использоваться в ходе работы.
Таблица 1 — Краткая характеристика переменных для анализа (составлено авторами на основе [29])
|
|
Переменная
|
Характеристика
|
|
Эндогенная
|
y (birth)
|
y – ур-нь рождаемости в США в 2023
г., % (birth)
|
|
Экзогенная
|
(div)
|
- количество
разводов на 1000 чел., % (div)
|
|
(mar)
|
- количество
браков на 1000 чел., % (mar)
| |
|
(sal)
|
- уровень
средней заработной платы в 2023г., $ (sal)
| |
|
𝒙𝟒(die)
|
- смертность от
сердечно-сосудистых заболеваний на 100000 чел., % (die)
| |
|
𝒙𝟓(unempl)
|
- уровень
безработицы, % (unempl)
| |
|
(gini)
|
- коэффициент
Джинни, % (gini)
| |
|
(dec)
|
- децильный
коэффициент (dec)
| |
|
(med)
|
- мед. страхование
для людей с низким доходом (med)
| |
|
𝒙𝟗(hous)
|
- индекс
доступности жилья (hous)
| |
|
(ir)
|
- максимальная %
ставка по потреб. кредитам, % (ir)
| |
|
𝒙𝟏𝟏(we)
|
- % женщин с
высшим образованием в возрасте 25-34 лет (we)
| |
|
(gdp)
|
- ВВП на душу
населения по ПСС штата к ср. ВВП США (gdp)
|
В таблице 1 представлена эндогенная
переменная - y
(birth), то
есть та, которая изменяется под влиянием экзогенных переменных, которых в
данном анализе 12: ![]() (div);
(div); ![]() (mar);
(mar); ![]() (sal);
(sal); ![]() (die);
(die); ![]() (unempl);
(unempl); ![]() (gini);
(gini); ![]() (dec);
(dec); ![]() (med);
(med); ![]() (hous);
(hous); ![]() (ir);
(ir); ![]() (we)
и
(we)
и ![]() (gdp).
(gdp).
С точки зрения социально-экономической взаимосвязи, влияние регрессоров можно разделить на две группы: положительные и отрицательные. Отрицательное влияние на y оказывают количество разводов, так как этого говорит о нестабильности института семьи и нежелании иметь детей. Переменная средней заработной платы может оказывать как положительный эффект на рождаемость, так и отрицательный, поскольку, с одной стороны, рост дохода увеличивает ресурс семьи, но, также, рост зарплаты увеличивает «цену» времени, потраченного на ребенка. Переменная, которая характеризует смерть от заболеваний имеет негативный характер, поскольку говорит о низком уровне развития медицины, что также подавляет желания иметь детей, поскольку люди чувствуют медицинскую незащищенность. Переменная безработицы оказывает отрицательный эффект, поскольку от неимения денег люди не могут завести ребенка, чтобы должным образом воспитать его и дать качественное образование. У Индекса Джинни и Децильного коэффициента связь с y неоднозначная, поскольку могут снижать рождаемость из-за общей экономической неуверенности населения, но также они показателя могут и не влиять на прямую на уровень рождаемости, поскольку больший % семей, которые заводят детей – средний класс. Индекс доступности жилья может иметь как отрицательную, так и положительную связь с уровнем рождаемости, поскольку именно он указывает на способность людей иметь свое жилье, что является одной из главных предпосылок к рождению ребенка. Переменная, которая отвечает за % ставку имеет отрицательный характер при росте, поскольку в таком случае стоимость жилья увеличивается. И наконец, переменная, отвечающая за женское образование также неоднозначна, поскольку при её росте может как увеличиться доход, необходимый для воспитания ребенка, также и снизиться желание заводить детей из-за нехватки времени. Переменные, определяющие количество браков и относительный ВВП имеют положительный эффект, поскольку увеличивают вероятность рождения детей.
Для выявления взаимосвязи между переменными, и определения характера связей между ними, были смоделированы графики линейности при помощи программного продукта RStudio [1].
На рисунке 1 представлены результаты проверки взаимосвязей между эндогенными и экзогенными переменными.
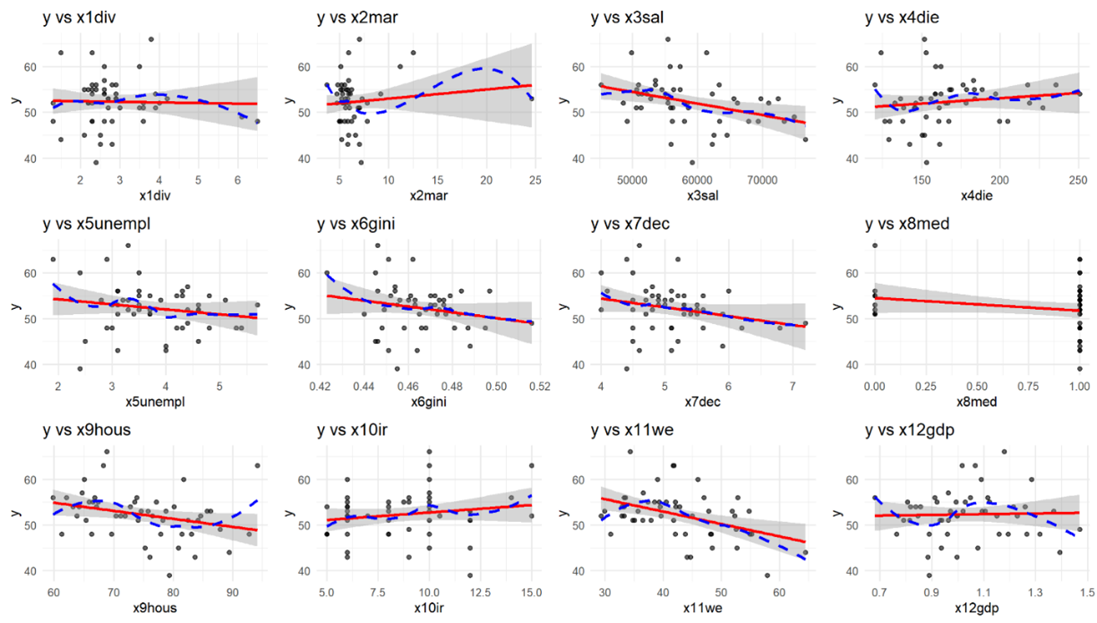
Рисунок 1 — Результаты проверки на взаимосвязь между эндогенными и экзогенными переменными (Составлено авторами по [23)]
На рисунке 1 представлены результаты
проверки на линейность, которая показала, что переменные ![]() (die),
(die),
![]() (unempl),
(unempl),
![]() (hous),
(hous),
![]() (ir),
(ir),
![]() (we),
(we),
![]() (gdp) имеют
приблизительную линейную тенденцию, то есть они способствуют снижению уровня
рождаемости в долгосрочной перспективе. Переменные
(gdp) имеют
приблизительную линейную тенденцию, то есть они способствуют снижению уровня
рождаемости в долгосрочной перспективе. Переменные ![]() (div),
(div),
![]() (mar),
(mar),
![]() (sal),
(sal),
![]() (gini),
(gini),
![]() (dec) имеют
нелинейность или очень слабую связь, то есть связь между y
и всеми x не может быть описана
прямой линией, т.е. они не взаимосвязаны. Переменную
(dec) имеют
нелинейность или очень слабую связь, то есть связь между y
и всеми x не может быть описана
прямой линией, т.е. они не взаимосвязаны. Переменную ![]() (med)
некорректно
описывать в контексте линейности, так как она бинарная.
(med)
некорректно
описывать в контексте линейности, так как она бинарная.
Основываясь на заявленной гипотезе
исследования, предполагается, что переменная образование (𝒙𝟏𝟏(we))
будет значима и отрицательно влиять на показатель y,
а переменная средняя заработная плата ( ![]() (sal))
будет иметь положительный эффект. Исходя из логического смысла, переменные,
определяющие доступность жилья (𝒙𝟗(hous)),
количество браков (
(sal))
будет иметь положительный эффект. Исходя из логического смысла, переменные,
определяющие доступность жилья (𝒙𝟗(hous)),
количество браков ( ![]() (mar)),
уровень ВВП (
(mar)),
уровень ВВП ( ![]() (gdp))
будут иметь положительный эффект на уровень рождаемости, поскольку рост данных
переменных предполагает благоприятные условия для рождения детей. Переменная,
отвечающая за уровень разводов (
(gdp))
будут иметь положительный эффект на уровень рождаемости, поскольку рост данных
переменных предполагает благоприятные условия для рождения детей. Переменная,
отвечающая за уровень разводов ( ![]() (div))
будет иметь отрицательный эффект, поскольку это говорит об ухудшении отношений
между людьми и распаде семей.
(div))
будет иметь отрицательный эффект, поскольку это говорит об ухудшении отношений
между людьми и распаде семей.
В ходе данного исследования предполагается наличие проблем с мультиколленирностью [2], поскольку в наборе данных существуют тесно взаимосвязанные друг с другом переменные. Также не исключается проблема гетероскедастичности [3], поскольку есть вероятность, что дисперсия случайной ошибки непостоянна. Также присутствует проблема эндогенности [4], поскольку объясняющая переменная может коррелировать с ошибками модели.
Предварительный анализ данных является важным шагом перед началом моделирования, так как он помогает отчистить данные, выбрать оптимальный инструментарий для будущего моделирования и сделать всеобъемлющие выводы на основе полученных результатов.
База данных типа cross-section для исследования собрана за 2023 год, с тем, чтобы наглядно рассмотреть влияние социально-экономических шоков таких, как: пандемия, внедрение ИИ, а также нестабильная политическая обстановка.
Выбор временного ряда также обоснован тем, что за 2023 году собрана максимально полная статистическая информация по выбранным показателям во всех штатах Америки. Поскольку ключевая цель работы заключается в изучении демографической ситуации в США при помощи регрессионного анализа, то важным условием является полнота выборки. Удовлетворяющим данное условием оказался только 2023 год из наиболее «свежих», поскольку по нему не наблюдалось пропусков в данных.
При дальнейшем выборе инструментов для анализа была проведена проверка на нормальность распределения переменной y (birth). Так, был построен график плотности распределения y. На рисунке 2 представлены результаты графика плотности распределения для y.
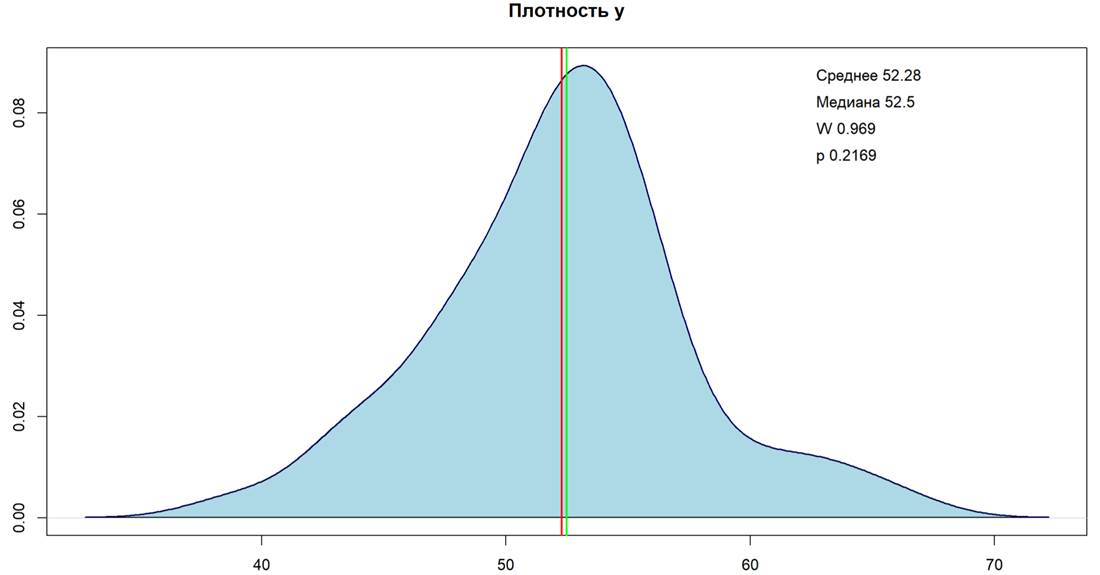
Рисунок 2 — График нормального распределения показателя y - рождаемость (Составлено авторами по [4, 15, 17])
Из рисунка 2 видно, что значение среднего (52,28) и медианы (52,5) практически равны, что говорит о распределении данных без большого смещения, однако наблюдаются значения, где плотность распределения равна 0. Это происходит из-за того, что показатель рождаемости в штате Вермонт составляет 39,00, что можно характеризоваться как выброс. Правый хвост графика отличен от левого, что также указывает на асимметрию в данных, поскольку в анализе есть штаты, которые имеют положительное отклонение от среднего значения – штат Вайоминг (66,00). Для подтверждения вышесказанного проведен тест Шапиро-Уилка на нормальность распределения, который подходит для анализа со средним количеством выборки (50) [31]. Согласно тесту, на 5% уровне значимости, Н0 – данные распределены нормально, H1- данные распределены ненормально. После проведения теста получились значения p-value = 0,2169 W= 0,9693, так как значение p>0,05 принимаем гипотезу H0 на 5% уровень значимости, а значение W указывает на то, что данные близки к нормальному распределению (0,9693), поскольку диапазон значения W лежит в интервале [0;1].
Чтобы проанализировать другие характеристики переменных более детально, была проведена описательная статистика датафрейма, результаты которой представлены на рисунке 3.
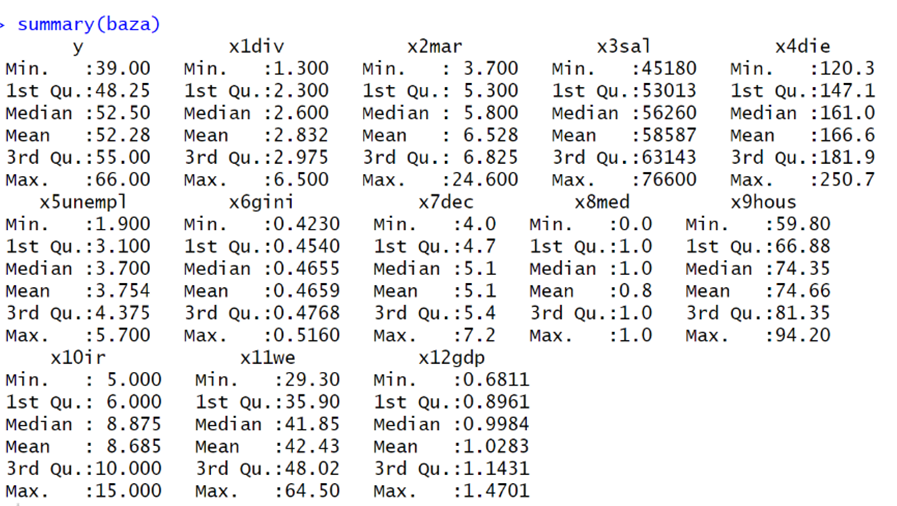
Рисунок 3 — Описательная статистика датафрейма (Составлено авторами по [29])
На рисунке 3 представлена описательная
статистика (min, первый квантиль,
median, mean,
3 квантиль и max) по всем
переменным. Показатель y
(birth)
– уровень рождаемости имеет минимальное значение (39,00), максимальное (66,00),
а среднее (52,28). Переменная ![]() (div)
- количество
разводов имеет минимальное значение (1,30), максимальное
(6,50), а среднее (2,83). Переменная
(div)
- количество
разводов имеет минимальное значение (1,30), максимальное
(6,50), а среднее (2,83). Переменная ![]() (mar) -
количество
браков имеет
минимальное значение (3,70), максимальное (24,50), а среднее (6,52). Переменная
(mar) -
количество
браков имеет
минимальное значение (3,70), максимальное (24,50), а среднее (6,52). Переменная
![]() (sal)
– средняя заработная плата имеет
минимальное значение (45180), максимальное (76600), а среднее (58587).
Переменная
(sal)
– средняя заработная плата имеет
минимальное значение (45180), максимальное (76600), а среднее (58587).
Переменная ![]() (die)
– смертность
от сердечно-сосудистых заболеваний имеет минимальное
значение (120,3), максимальное (250,7), а среднее (166,6). Переменная
(die)
– смертность
от сердечно-сосудистых заболеваний имеет минимальное
значение (120,3), максимальное (250,7), а среднее (166,6). Переменная ![]() (unempl) –
уровень
безработицы имеет минимальное значение (1,90), максимальное
(5,70), а среднее (3,75). Переменная
(unempl) –
уровень
безработицы имеет минимальное значение (1,90), максимальное
(5,70), а среднее (3,75). Переменная ![]() (gini)
–
индекс
Джинни имеет
минимальное значение (0,42), максимальное (0,51), а среднее (0,46). Переменная
(gini)
–
индекс
Джинни имеет
минимальное значение (0,42), максимальное (0,51), а среднее (0,46). Переменная ![]() (dec) –
децельный
коэффициент имеет минимальное значение (4,0), максимальное (7,2),
а среднее (5,1). Переменная
(dec) –
децельный
коэффициент имеет минимальное значение (4,0), максимальное (7,2),
а среднее (5,1). Переменная ![]() (med)
– наличие
мед. страховки является бинарной переменной, то есть той, которая принимает
значения 1 – да и 0 – нет, поэтому некорректно и невозможно делать по ней
описательную статистику. Переменная
(med)
– наличие
мед. страховки является бинарной переменной, то есть той, которая принимает
значения 1 – да и 0 – нет, поэтому некорректно и невозможно делать по ней
описательную статистику. Переменная ![]() (hous)
–
индекс доступности жилья имеет минимальное
значение (59,80), максимальное (94,20), а среднее (74,66). Переменная
(hous)
–
индекс доступности жилья имеет минимальное
значение (59,80), максимальное (94,20), а среднее (74,66). Переменная ![]() (ir)
–
максимальная процентная ставка имеет минимальное значение (5,00),
максимальное (15,00), а среднее (8,68).
Переменная
(ir)
–
максимальная процентная ставка имеет минимальное значение (5,00),
максимальное (15,00), а среднее (8,68).
Переменная ![]() (we)
–
доля
женщин с высшим образование имеет минимальное
значение (29,30), максимальное (64,50), а среднее (42,43). Переменная
(we)
–
доля
женщин с высшим образование имеет минимальное
значение (29,30), максимальное (64,50), а среднее (42,43). Переменная ![]() (gdp)
–
ВВП
на душу населения по ПСС штата к ср. ВВП США имеет минимальное
значение (0,6811), максимальное (1,47), а среднее (1,02). Подводя итоги, можно
заключить, что в данных отсутствуют явные аномалии, однако наблюдаются явные
выбросы у переменной
(gdp)
–
ВВП
на душу населения по ПСС штата к ср. ВВП США имеет минимальное
значение (0,6811), максимальное (1,47), а среднее (1,02). Подводя итоги, можно
заключить, что в данных отсутствуют явные аномалии, однако наблюдаются явные
выбросы у переменной ![]() (mar),
поскольку его максимальное значение существенно превышает 3 квантиль. Для
корректности дальнейшего анализа следует провести проверку на выбросы, которая и
будет выполнена на дальнейшем этапе исследования.
(mar),
поскольку его максимальное значение существенно превышает 3 квантиль. Для
корректности дальнейшего анализа следует провести проверку на выбросы, которая и
будет выполнена на дальнейшем этапе исследования.
Для того, чтобы понимать, как данные взаимодействуют между собой и выявить скрытые взаимосвязи, существует ряд способов: диаграмма рассеивания, корреляционная матрица, box plot диаграмма.
В качестве первого инструмента была построена диаграмма рассеивания, которая отображает взаимосвязь между двумя переменными на координатной плоскости. На рисунке 4 представлен результат построения диаграммы.
Рисунок 4 — Диаграмма рассеивания (Составлено авторами по [22])
Из рисунка 4 видно, как переменные
распределились на графике. Однако, аналогичное исследование было проведено на
этапе определения взаимосвязей между переменными. Тем не менее, переменные: 𝒙𝟏𝟏(we),
𝒙𝟗(hous),
𝒙𝟓(unempl),
𝒙𝟒(die),
![]() (ir),
(ir),
![]() (gdp) имеют
умеренную линейную взаимосвязь, а переменные:
(gdp) имеют
умеренную линейную взаимосвязь, а переменные: ![]() (mar),
(mar), ![]() (sal),
(sal), ![]() (div)
и
(div)
и ![]() (gini)
нелинейную,
и потенциально их можно исключить из анализа, однако следует тем не менее
проверить, какой эффект они окажут на саму модель.
(gini)
нелинейную,
и потенциально их можно исключить из анализа, однако следует тем не менее
проверить, какой эффект они окажут на саму модель.
Далее была построена матрица парных коэффициентов корреляции, которая представлена в виде таблицы с пересечение столбцов и строк, которые показывают тесноту связи между переменными. [5, 6] На рисунке 5 представлен результат построения матрицы парных коэффициентов корреляции.
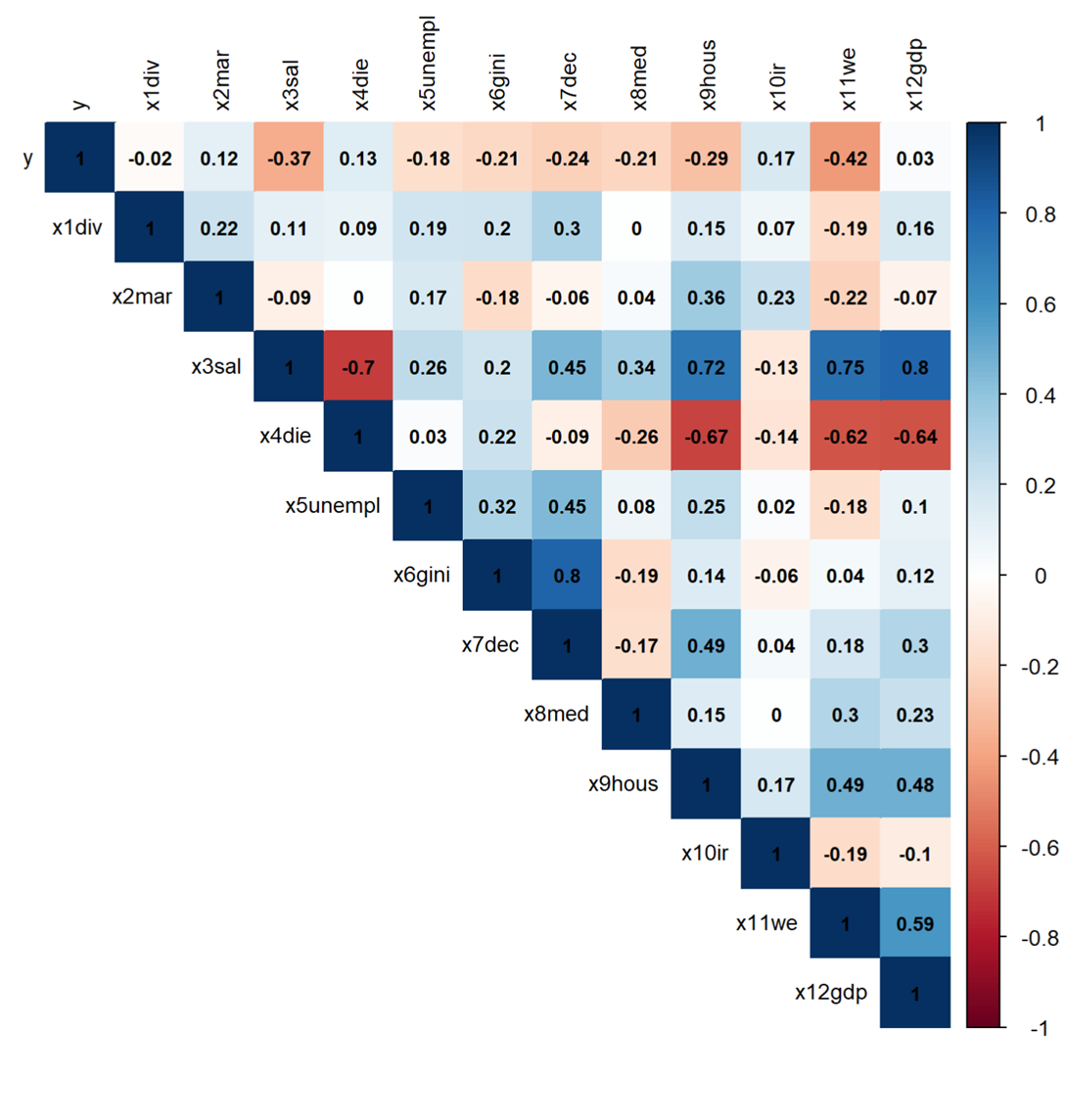
Рисунок 5 — Матрица парных коэффициентов корреляции (Составлено авторами по [5, 6])
На рисунке 5 представлена корреляция всех переменных с y. Можно отметить сильную отрицательную корреляцию между рождаемостью и образованием женщин (-0,42), что логически обосновано, поскольку образование меняет фокус внимание женщины с детей на карьеру. Индекс жилья и рождаемость также имеют отрицательную связь (-0,29), то есть чем меньше доступность жилья, тем ниже рождаемость. Из оставшихся взаимосвязей также хотелось бы выделить рождаемость и безработицу (-0,18) и рождаемость и среднюю зарплату (-0,37). Это логических обосновано, поскольку если нет источника заработка, то и нет ресурса заводить детей. А вот отрицательная корреляция (-0,37) говорит, как раз-таки, об эффекте замещения, то есть рост дохода увеличивает стоимость времени, а время, потраченное на ребенка, обходится дороже, поскольку в этот момент люди упускают реальный заработок.
Заключительным инструментов визуализации взаимодействия переменных является Box plot, который показывает плотность данных и наличие в них выбросов, то есть значений, которые выделяются из общей массы данных. На рисунке 6 представлен результат построения Box plot.
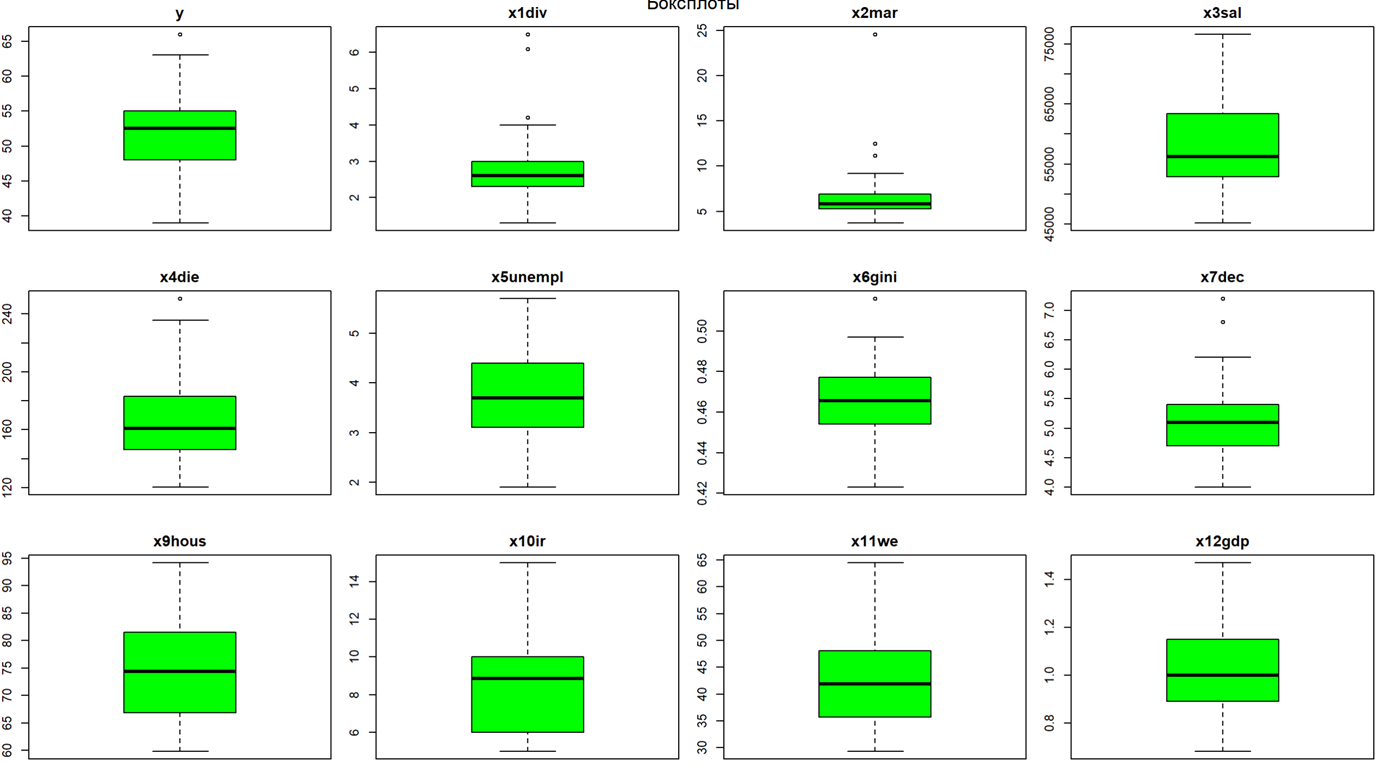
Рисунок 6 — Box Plot (Составлено авторами по [22])
Из рисунка 6 видно, что переменные 𝒙𝟏𝟏(we),
𝒙𝟗(hous),
𝒙𝟓(unempl), ![]() (ir),
(ir), ![]() (gdp)
и
(gdp)
и ![]() (sal) не
имеют выбросов, то есть данные близки к нормальному распределению. Переменные
(sal) не
имеют выбросов, то есть данные близки к нормальному распределению. Переменные ![]() (div),
(div), ![]() (mar),
𝒙𝟒(die),
(mar),
𝒙𝟒(die), ![]() (gini),
(gini),
![]() (dec) имеют
незначительные выбросы.
(dec) имеют
незначительные выбросы.
Для того, чтобы сделать корректные выводы по дальнейшему анализу необходимо провести проверку на выбросы, при помощи которой можно выявить скрытые аномалии, которые влияют на качество анализа. Результаты проверки представлены на рисунке 7.
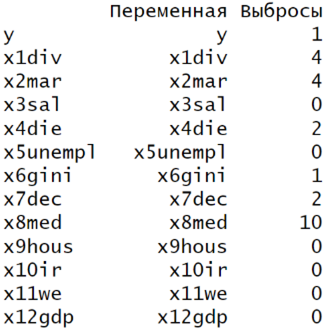
Рисунок 7 — Проверка датафрейма на наличие выбросов (Составлено авторами по [22])
Из рисунка 7 видно, что переменные: средний уровень заработной платы (x3sal), уровень безработицы (x5unempl), индекс доступности жилья (x9hous), максимальная % ставка (x10ir), доля женщин с высшим образованием (x11we) и ВВП на душу населения по ПСС (x12gdp) не имеют аномальных значений, поскольку данные однородны. Переменная мед. страхование для людей с низким доходом (x8med) имеет 10 выбросов. Стоит учесть, что эта переменная является бинарной, то есть в тех штатах Америки, где показатель 1 – люди имею мед. страховку при низком уровне зарплаты, а где 0 – не имеют. В 40 штатах страховка предусмотрена, а в 10 – нет (Алабама, Вайоминг, Джорджия, Канзас, Миссисипи, Северная Каролина, Теннесси, Техас, Флорида, Южная Каролина). Это штаты, где уровень заработной платы ниже среднего значения (58586,6), что говорит о низком социально-экономическом уровне населения, которое не способно покрывать мед. расходы, соответственно, данные значения не являются выбросами, они отражают прямую экономическую ситуацию, которая происходит в штате, поэтому их удалять некорректно. Показатель индекс Джинни (x6gini) имеет один аномальный объект – штат Нью-Йорк (0,51), это небольшое отклонение от среднего по показателю (0,46). Данное явление нельзя назвать выбросом, поскольку оно несет в себе социально-экономический подтекст, так как Нью-Йорк – единственный штат, в котором более 20% жителей жили за чертой бедности, а доход 20% самых богатых жителей мегаполиса в 40 раз превышал доход 20% самых бедных. Показатели разводов (x1div) и браков (x2mar) имеют по 4 аномальных объекта, а показатели смертности от сердечно-сосудистых заболеваний (x4die) и децильный коэффициент (x7dec) по 2, что также не является аномалией, а особенностью социально-экономической обстановки в штатах. Кроме того, 2% данных, как в первом случае, и 4% как во 2, от общей совокупности в 50 наблюдений являются весомыми значениями, поэтому было принято решение оставить их для дальнейшего анализа.
Классический регрессионный анализ
В рамках следующего шага будет построена регрессионная модель, основанная на анализе данных, результатах анализа релевантной литературы, и своих научных предположениях.
При
анализе научной литературы было выявлено, что на показатель рождаемость могут
влиять такие факторы, как: средняя заработная плата – ![]() доля
женщин с высшим образованием в возрасте 25-34 лет -
доля
женщин с высшим образованием в возрасте 25-34 лет - ![]() ,
индекс доступности жилья -
,
индекс доступности жилья - ![]() (hou
(hou ![]() и
уровень безработицы -
и
уровень безработицы - ![]() В
рамках проведения предварительного анализа данных была сделана проверка на
линейность, которая установила, что переменные: децельный коэффициент -
В
рамках проведения предварительного анализа данных была сделана проверка на
линейность, которая установила, что переменные: децельный коэффициент - ![]() и
индекс Джинни -
и
индекс Джинни - ![]() (gini)
имеют
почти идеальную линейную зависимость (рисунок 1), следовательно, было принято
решение выбрать именно их. Далее была построена матрица парных коэффициентов
корреляции (рисунок 5), которая показала, что (y) имеет
среднюю отрицательную зависимость с показателем
(gini)
имеют
почти идеальную линейную зависимость (рисунок 1), следовательно, было принято
решение выбрать именно их. Далее была построена матрица парных коэффициентов
корреляции (рисунок 5), которая показала, что (y) имеет
среднюю отрицательную зависимость с показателем ![]() (sal) (-0,37),
который уже есть в списке регрессоров,
(sal) (-0,37),
который уже есть в списке регрессоров, ![]() (we)
(-0,42),
(we)
(-0,42), ![]() (hous)
(-0,29),
(hous)
(-0,29), ![]() (dec)
(-0,24),
(dec)
(-0,24), ![]() (gini)
(-0,21) и
(gini)
(-0,21) и ![]() (unempl)
(-0,18). Кроме того, была
проведена проверка на выбросы (рисунок 7), которая показала, что у переменных:
максимальная % по потреб.кредитам –
(unempl)
(-0,18). Кроме того, была
проведена проверка на выбросы (рисунок 7), которая показала, что у переменных:
максимальная % по потреб.кредитам – ![]() (ir) и ВВП
на душу населения по ПСС штата к ср. ВВП в США -
(ir) и ВВП
на душу населения по ПСС штата к ср. ВВП в США - ![]() (gdp) выбросы
отсутствуют. Также необходимо проверить тезис о том, что чем выше уровень
образования женщин
(gdp) выбросы
отсутствуют. Также необходимо проверить тезис о том, что чем выше уровень
образования женщин ![]() (we) и
заработной платы
(we) и
заработной платы ![]() (sal),
тем ниже уровень рождаемости (Y).
Необходимо также добавить качественную переменную –
мед.
страхование для людей с низким доходом
(sal),
тем ниже уровень рождаемости (Y).
Необходимо также добавить качественную переменную –
мед.
страхование для людей с низким доходом ![]() (med). Таким
образом, авторская регрессионная модель примет следующий вид:
(med). Таким
образом, авторская регрессионная модель примет следующий вид:
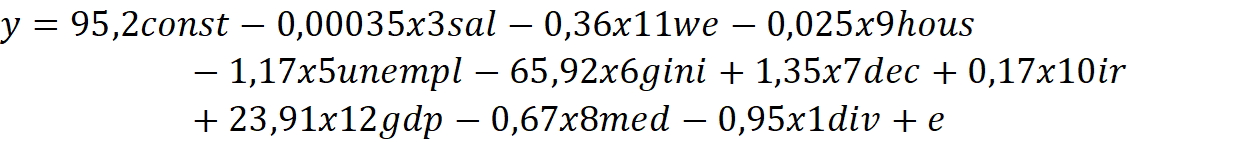
В регрессионной модели 12 регрессоров включая const. Необходимо проверить регрессию на значимость в целом при помощи F-теста [5]. H0: незначимая регрессия, H1: значимая регрессия. Df1= 9, df2=40, a=0,05. Исходя из таблицы Фишера F-табл=2,12, a=0,1. F-табл=1,79, a=0,01. F-табл=2,88=> отвергаем H0. Регрессия в целом значима на всех уровнях значимости, так как F-расчет (4.8) > F-крит (2.12).
Исходя из таблицы ANOVA коэффициенты const (***), x12gdp (***) и x11we (*) значимы, поскольку их p-value меньше 0,05. То есть при изменении (x11we) (процент женщин с высшим образованием) на 1% y (рождаемость) уменьшается на 0,36 б.е., что является социально-экономически обоснованным явлением, поскольку женщины нацелены на получение образования и построение карьеры, поэтому рождение детей откладывается. При изменении показателя (x12gdp) (ВВП на душу населения по ПСС штата к ср. ВВП в США) на 1% y (рождаемость) увеличивается на 23,91 б.е., что также справедливо, поскольку рост ВВП означает повышение дохода населения, что позволяет людям чувствовать себя экономически защищенными и заводить детей.
![]() , а
, а ![]() , то есть доля дисперсии зависимой переменной, объясняемая
нашей моделью с учетом предикторов, составляет 41%, что является хорошим
результатом. Однако следует провести ряд статистических тестов, чтобы
попытаться оптимизировать имеющуюся модель.
, то есть доля дисперсии зависимой переменной, объясняемая
нашей моделью с учетом предикторов, составляет 41%, что является хорошим
результатом. Однако следует провести ряд статистических тестов, чтобы
попытаться оптимизировать имеющуюся модель.
Попытаемся определить, можно ли считать, что две выборки принадлежат одной генеральной совокупности, то есть лучше оценивать одну регрессию, или две разных. Для этого необходимо провести тест Чоу [6] [19].
Для начала, необходимо определить
Дамми-переменную, то есть ту, значения которой 0 или 1. В нашем случаем, такой
переменной является ![]() (med) –
мед.страхование для людей с низким доходом. 1 – штат, где такое страхование
принято и 0 – не принято. Таким образом, H0:
зависимость едина для двух выборок, H1:
зависимость для двух выборок разная. Df1
= 10, df2
= 30, а=0,05 F-табл
(2,16), а=0,01 F-табл
(2,98), а=0,1 F-табл
(1,81) => H0
не отвергается на всех уровнях значимости, так как F-расчет
(0,45) < F-табл,
а значит зависимость для двух выборок одна.
(med) –
мед.страхование для людей с низким доходом. 1 – штат, где такое страхование
принято и 0 – не принято. Таким образом, H0:
зависимость едина для двух выборок, H1:
зависимость для двух выборок разная. Df1
= 10, df2
= 30, а=0,05 F-табл
(2,16), а=0,01 F-табл
(2,98), а=0,1 F-табл
(1,81) => H0
не отвергается на всех уровнях значимости, так как F-расчет
(0,45) < F-табл,
а значит зависимость для двух выборок одна.
Далее, для того, чтобы выявить спецификацию модели был проведен тест Рамсея [7] по генеральной совокупности. H0: спецификация модели является правильной, H1: спецификация модели является неправильной. Df1 = 2, df2 = 38, а=0,05 F-табл ≈ (3,23), а=0.1 F-табл ≈ (2,4), а=0,01 F-табл ≈ (5,1) => H0 не отвергается на всех уровнях значимости, так как F-расчет (0,67) <F- табл спецификация нашей модели верна [20].
Чтобы определиться, какая модель – линейная или логарифмическая лучше, стоит для начала привести линейную модель к виду полулогарифмической и провести тест Бокса-Кокса [8].
Для начала необходимо перевести авторскую модель в логарифмическую форму:
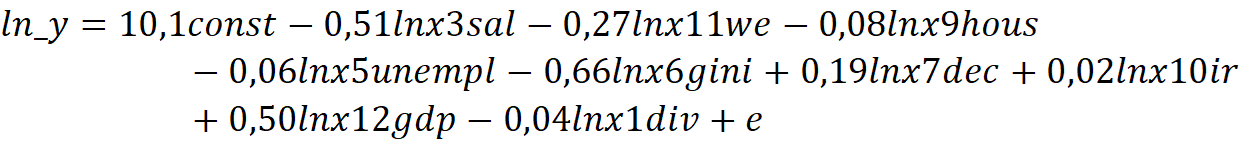
В регрессионной модели 10 регрессоров, включая const. Проведем F-тест для оценки значимости регрессии в целом. H0: незначимая регрессия, H1: значимая регрессия. Df1= 9, df2=40. Исходя из таблицы Фишера a=0,05 F-табл (2,12), а=0,1 F-табл (1,79), а=0.01 F-табл (2,88) =>H0 отвергаем. Таким образом, регрессия в целом значима на всех уровнях значимости, так как F-расчет (4,7) > F-табл.
Исходя из таблицы ANOVA коэффициенты const (***), x12gdp (***) и x11we (*) значимы, поскольку их p-value меньше 0.05. То есть при изменении x11we (процент женщин с высшим образованием) на 1% y (рождаемость) уменьшается на 0,27%, что является социально-экономически обоснованным явлением, поскольку женщины нацелены на получение образования и построение карьеры, поэтому рождение детей откладывается. При изменении показателя x12gdp (ВВП на душу населения по ПСС штата к ср. ВВП США) на 1% y (рождаемость) увеличивается на 23,91%, что также имеет место быть, поскольку рост ВВП означает повышение дохода населения, что позволяет людям чувствовать себя экономически защищенными и заводить детей.
![]() , а
, а ![]() , то есть
доля дисперсии зависимой переменной, объясняемая авторской моделью с учетом
предикторов, составляет 40%, что является хорошим результатом.
, то есть
доля дисперсии зависимой переменной, объясняемая авторской моделью с учетом
предикторов, составляет 40%, что является хорошим результатом.
Далее для выбора между линейной и логарифмической моделью необходимо сделать преобразование Бокса-Кокса. Для этого необходимо найти лямбду, которая равна 1,15. Это говорит о том, что лямбда стремится к 1, а значит авторская модель является линейной, и дальнейшее преобразование не требуется.
Анализ проблем с данными
После этого, необходимо проверить разработанную модель на наличие мультиколлинеарности, чтобы избежать неточности оценок. Результаты проверки представлены на рисунке 8.

Рисунок 8 – Мультиколлинеарность (Составлено авторами по [14])
Из рисунка 8 видно, что переменные x3sal (уровень средней заработной платы) и x7dec (дефицильный коэффициент) имеют сильную мультиколлинераность, так как их VIF>5 поэтому было принято решение убрать их из модели. После этого была построена новая модель ANOVA:
![]()
В регрессионной модели 8 регрессоров, включая const. Проведем F-тест для оценки значимости регрессии в целом. H0: незначимая регрессия, H1: значимая регрессия. Df1= 7, df2=42, исходя из таблицы Фишера a=0.05 F-табл ≈ (2,49), а=0,1 F-табл ≈ (2,4), а=0,01 F-табл (5,1) =>H0 отвергаем. Регрессия в целом значима на всех уровнях значимости, так как F-расчет (5,6) > F-табл.
Исходя из таблицы ANOVA коэффициенты const (***), x12gdp (***), x11we (***) и x5unempl (*) значимы, поскольку их p-value меньше 0.05. То есть при изменении x11we (процент женщин с высшим образованием) на 1% y (рождаемость) уменьшается на 0,51 б.е., что является социально-экономически обоснованным явлением, поскольку женщины нацелены на получение образования и построение карьеры, поэтому рождение детей откладывается. При изменении показателя x12gdp (ВВП на душу населения по ПСС штата к ср. ВВП США) на 1% y (рождаемость) увеличивается на 18.52 б.е., что также имеет место быть, поскольку рост ВВП означает повышение дохода населения, что позволяет людям чувствовать себя экономически защищенными и заводить детей. При изменении показателя x5unempl (безработица) на 1% y (рождаемость) уменьшается на 1,7 б.е., поскольку высокая безработица вызывает экономическую нестабильность и недоверие к будущему, поэтому люди склонны откладывать рождение ребенка.
![]() , а
, а ![]() , то есть
доля дисперсии зависимой переменной, объясняемая нашей моделью с учетом
предикторов, составляет 39%, что является хорошим результатом.
, то есть
доля дисперсии зависимой переменной, объясняемая нашей моделью с учетом
предикторов, составляет 39%, что является хорошим результатом.
Затем, чтобы выявить наличие неоднородности наблюдения, проведем проверку на гетероскедастичность при помощи теста Уайта, Гольфельда-Кванта и Бройша Пагана [23]:
1. Тест Уайта [9]. H0: нет гетероскедастичности, H1: есть гетероскедастичность. Поскольку df1= 1, а=0,05 Хи^2-табл (3,84), а=0,01 Хи^2-табл (6,64), а=0,1 Хи^2-табл (2,71) => H0 не отвергается на всех уровнях значимости, так как Хи^2-расчет (0,03) < Хи^2-крит => нет г/ск.
2. Тест Голдфелда Куандта [10]. H0: в модели отсутствует г/ск, H1: в модели есть г/ск. Поскольку df1=17 df2=17, а=0,05 F-табл (≈2,27), а=0,01 F-табл (≈3.20), а=0,1 F-табл (≈1,75) => H0 не отвергается всех уровнях значимости, так как F-расчет (0,87) < F-табл => нет г/ск.
3. Тест Бройша Пагана [11]. H0: в модели отсутствует г/ск, H1: в модели есть г/ск. Поскольку df1=7, а=0,05 X^2-табл (14,7), а=0,01 X^2-табл (18.48), а=0,1 X^2-табл (12,02) при 5% и 1% уровне значимости => H0 не отвергается, так как X^2-табл > X^2-расчет (12,68) => нет г/ск, а при 10% уровне значимости H0 отвергается, так как X^2-табл (12,02) < X^2-расчет (12,68) => есть г/ск на 10% уровне значимости. Поскольку в этом тесте была обнаружена гетероскедастичность, было принято решение рассчитать взвешенный МНК и робастные ошибки:
![]()
В регрессионной модели 8 регрессоров включая const. H0: незначимая регрессия, H1: значимая регрессия. Df1= 7, df2=42, исходя из таблицы Фишера а=0,05 F-табл≈(2,24), а=0,01 F-табл≈(3,12), а=0.1 F-табл≈(1,87) => H0 отвергаем, регрессия в целом значима на всех уровнях значимости, так как F-табл < F-расчет (5,56).
Исходя из таблицы ANOVA коэффициенты const (***), x12gdp (***), x11we (***) и x5unempl (*) значимы, поскольку их p-value меньше 0,05. То есть при изменении x11we (процент женщин с высшим образованием) на 1% y (рождаемость) уменьшается на 0,51 б.е., что является социально-экономически обоснованным явлением, поскольку женщины нацелены на получение образования и построение карьеры, поэтому рождение детей откладывается. При изменении показателя x12gdp (ВВП на душу населения по ПСС штата к ср. ВВП США) на 1% y (рождаемость) увеличивается на 18,83 б.е., что также имеет место быть, поскольку рост ВВП означает повышение доходов населения, что позволяет людям чувствовать себя экономически защищенными и заводить детей. При изменении показателя x5unempl (безработица) на 1% y (рождаемость) уменьшается на 1,68 б.е., что также является объяснимым, поскольку безработица говорит об отсутствии дохода у населения, что откладывает рождение детей.
![]() , а
, а ![]() то есть доля дисперсии зависимой переменной, объясняемая разработанной
моделью с учетом предикторов, составляет 39%, что является хорошим результатом.
то есть доля дисперсии зависимой переменной, объясняемая разработанной
моделью с учетом предикторов, составляет 39%, что является хорошим результатом.
Для обнаружения автокорреляции первого порядка в остатках регрессионной модели необходимо провести тест Дарбина-Уотсона. H0: p=0 (нет автокорреляции), H1: p > 0 (положительная автокорреляция). df1 = 42 k=7, n=50 при а=0,05. Согласно таблице ДВ dl= 1,32 du=1,57. Результат 2,32 попадает в интервал, где нет автокорреляции=>H0 не отвергаем на уровне 5%, автокорреляция отсутствует, так как du(1,57)< dw(2,23). Также проведен тест Бройша-Годфри для тестирования автокорреляции второго порядка. H0: нет автокорреляции возмущений. H1: имеет место автокорреляция возмущений порядка p. df=2 исходя из таблицы Хи распределения а=0,05 Хи^2-табл (5,99), а=0,1 Хи^2-табл (4,46), а=0,01 Хи^2-табл (9,21) => H0 не отвергается, автокорреляция отсутствует на всех уровнях значимости, так как Хи-табл > Хи-расчет (3,09).
В модели может
присутствовать потенциальная проблема эндогенности в результате одновременности
или обратной причинно-следственной связи. Для потенциального решения этой
проблемы был выбран метод инструментальных переменных (ИП). В теории
эндогенными переменными могут быть все, кроме бинарных (x8med), однако, сложность
этого определения заключается в подборе верных инструментов. Для каждой
переменной, задействованной в работе, можно было бы подобрать свои инструменты.
Так, например, для переменной ![]() –
количество насильственных действий на 100 тыс. человек.
–
количество насильственных действий на 100 тыс. человек. ![]() –
премии за стаж работы.
–
премии за стаж работы. ![]() –
% бездетных
женщин в возрасте 40-50 лет.
–
% бездетных
женщин в возрасте 40-50 лет. ![]() –
смертность от передозировки психотропными веществами,
–
смертность от передозировки психотропными веществами, ![]() –
уровень минимальной заработной платы,
–
уровень минимальной заработной платы, ![]() –
доход старшего поколения в семье,
–
доход старшего поколения в семье, ![]() (dec) –
% людей с капиталом выше среднего
(dec) –
% людей с капиталом выше среднего ![]() (hous)
– среднее время, потраченное на проезд в общественном транспорте,
(hous)
– среднее время, потраченное на проезд в общественном транспорте, ![]() (ir)
- % кредитов на основе стоимости дома,
(ir)
- % кредитов на основе стоимости дома, ![]() –
доля мужчин с высшим образованием из всей совокупности выпускников,
–
доля мужчин с высшим образованием из всей совокупности выпускников, ![]() (gdp)
– коэффициент деловой активности. Для большинства этих инструментов отсутствуют
данные на должном для проведения достоверных расчётов уровне, поэтому в данном
исследовании была сделана проверка только двух переменных
(gdp)
– коэффициент деловой активности. Для большинства этих инструментов отсутствуют
данные на должном для проведения достоверных расчётов уровне, поэтому в данном
исследовании была сделана проверка только двух переменных ![]() и
и
![]() .
Для
.
Для ![]() использовался
уровень минимальной заработной платы (inst_wage),
поскольку этот показатель задает минимальную границу денежной платы за труд,
что влияет на выбор человека, работать в компании или нет. То есть большой %
людей будет не согласен работать вообще при минимальном уровне заработной
платы, отсюда будет расти уровень безработицы, но не влиять на уровень
рождаемости напрямую, поскольку люди будут находится в поисках лучшего
варианта. Для
использовался
уровень минимальной заработной платы (inst_wage),
поскольку этот показатель задает минимальную границу денежной платы за труд,
что влияет на выбор человека, работать в компании или нет. То есть большой %
людей будет не согласен работать вообще при минимальном уровне заработной
платы, отсюда будет расти уровень безработицы, но не влиять на уровень
рождаемости напрямую, поскольку люди будут находится в поисках лучшего
варианта. Для ![]() использовался
показатель количество насильственных действий на 100 тыс. человек (vio),
поскольку этот показатель напрямую может влиять на подход людей к созданию
семьи, но не на показатель рождаемости. Оценка ИП модели показала, что
выбранные инструменты достаточно слабые, поскольку F-статистика
для vio и inst_wage
< 10 (0,6 и 0,07), а p-value
для этих переменных >0,05 (0,7 и 0,4). Также был проведен тест Хаусмана, по
котором p-value>
0.05 (0,103 и 0,440), соответственно гипотезу об экзогенности исходных переменных
не отвергается, что указывает на отсутствие значимой эндогенности в данной
спецификации. А значит, исходная модель взвешенного МНК может считаться
состоятельной, и корректировка при помощи ИП не требуется.
использовался
показатель количество насильственных действий на 100 тыс. человек (vio),
поскольку этот показатель напрямую может влиять на подход людей к созданию
семьи, но не на показатель рождаемости. Оценка ИП модели показала, что
выбранные инструменты достаточно слабые, поскольку F-статистика
для vio и inst_wage
< 10 (0,6 и 0,07), а p-value
для этих переменных >0,05 (0,7 и 0,4). Также был проведен тест Хаусмана, по
котором p-value>
0.05 (0,103 и 0,440), соответственно гипотезу об экзогенности исходных переменных
не отвергается, что указывает на отсутствие значимой эндогенности в данной
спецификации. А значит, исходная модель взвешенного МНК может считаться
состоятельной, и корректировка при помощи ИП не требуется.
Подводя итоги проведенного анализа и всем проделанным тестам и расчетам можно заключить, что оптимальная модель сформировалась на этапе построения Взвешенного МНК. На рисунке 8 представлена ANOVA.

Рисунок 8 – Взвешенный МНК, ANOVA (Составлено авторами по [14, 26])
На рисунке 8 представлена конечная наилучшая модель взвешенного МНК. Модель состоит из 8 регрессоров включая const. Проверим регрессию на значимость в целом при помощи F-теста. H0: незначимая регрессия, H1: значимая регрессия. Df1= 7, df2=42, a=0,05 исходя из таблицы Фишера F-табл ≈ 2,24, a=0,1 F-табл ≈ 1,87, a=0,01 F-табл ≈ 3,12=> H0 отвергаем. Регрессия в целом значима на всех уровнях значимости, так как F-расчет (5,56) > F-крит.
Исходя из таблицы ANOVA коэффициенты const (***), x12gdp (***), x11we (***) и x5unempl (*) значимы, поскольку их p-value меньше 0,05. То есть при изменении (x11we) (процент женщин с высшим образованием) на 1% y (рождаемость) уменьшается на 0,51 б.е., что является социально-экономически обоснованным явлением, поскольку в США женщины нацелены на получение образования и построения карьеры. Это является причиной сдвига с семейных ценностей в самореализацию и рождение детей откладывается. Соответственно и уровень рождаемости от этого падает. При изменении показателя (x12gdp) (ВВП на душу населения по ПСС штата к ср. ВВП США) на 1% y (рождаемость) увеличивается на 18,83 б.е., что также имеет место быть, поскольку рост ВВП означает повышение дохода населения, что позволяет людям чувствовать себя экономически защищенными и заводить детей. При изменении (x5unempl) (уровень безработицы) на 1% y (рождаемость) уменьшается на 1,68 б.е., что также является социально-экономически обоснованным, поскольку безработица ведет к сокращению дохода домохозяйств, что также откладывает рождение детей как долгосрочный и финансово-затратный процесс.
![]() , а
, а ![]() , то есть доля дисперсии зависимой переменной, объясняемая
нашей моделью с учетом предикторов, составляет 39%, что является хорошим
результатом.
, то есть доля дисперсии зависимой переменной, объясняемая
нашей моделью с учетом предикторов, составляет 39%, что является хорошим
результатом.
Кластерный анализ
Авторами было принято решение провести кластерный анализ, с целью разнесения всех американских штатов по релевантным задачам исследования группам. Первым шагом в кластеризации является установление оптимального числа кластеров для наших объектов. В качестве проверки выбран метод силуэта [8,10]. Результаты применения метода представлен на рисунке 9.
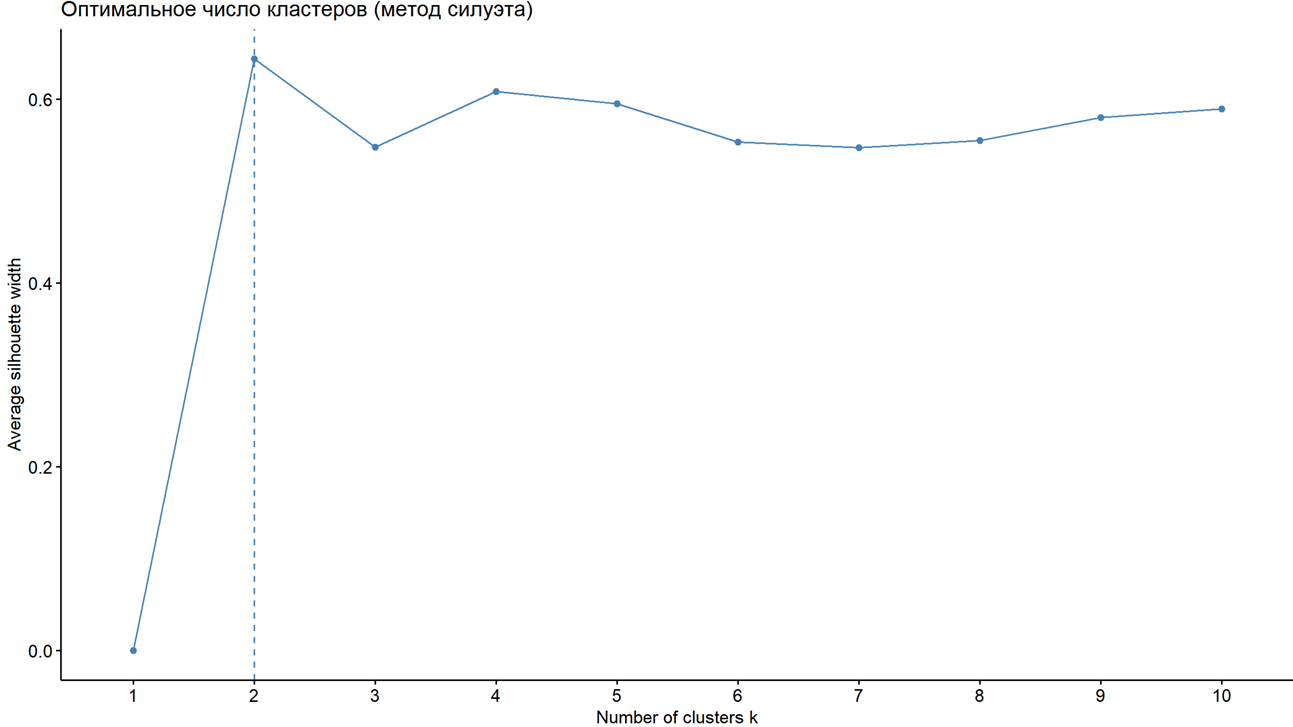
Рисунок 9 – Метод силуэта (Составлено авторами по [8,10])
На рисунке 9 представлены результаты применения метода силуэта, в итоге было получено оптимальное число кластеров равное 2, то есть k = 2. Для верификации полученного результата также был проведен метод локтя, см. рисунок 10.
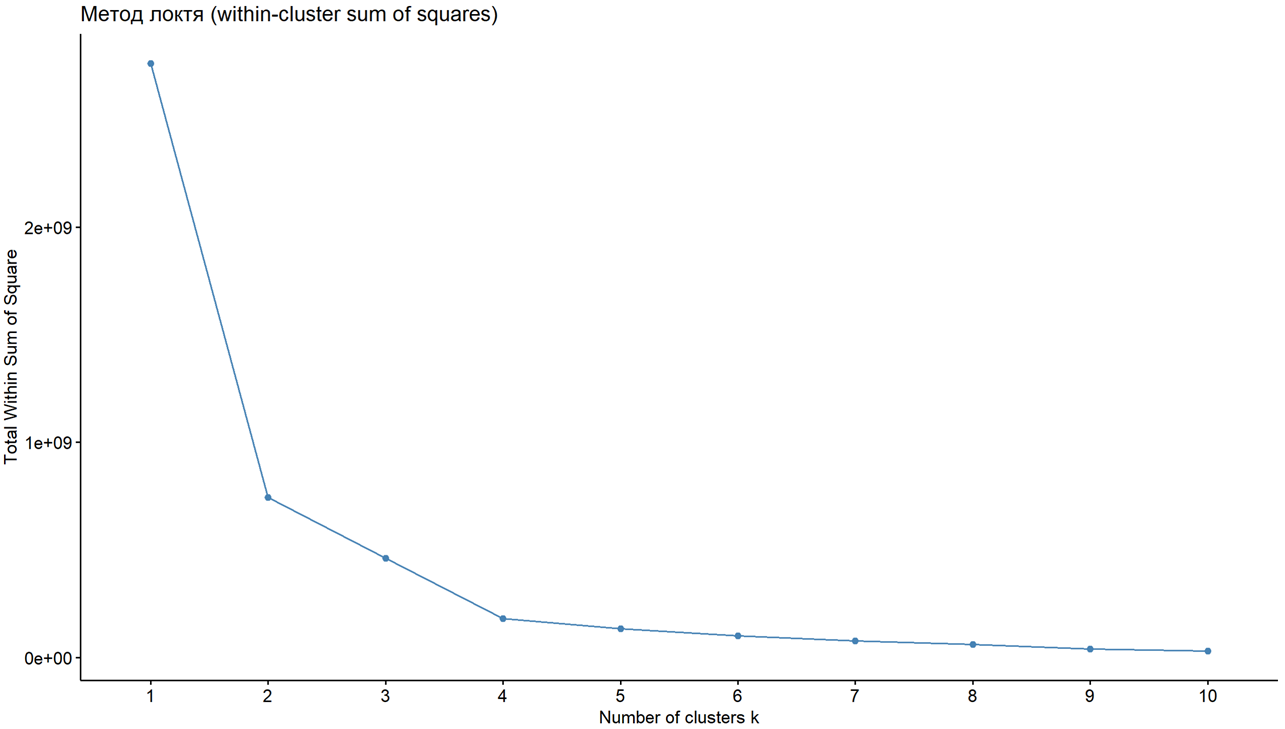
Рисунок 10 – Метод локтя (Составлено авторами по [8,10])
Оптимальное рекомендованное число кластеров также k=2.
Для проведения непосредственно кластеризации был выбран метод К-медоидов [8,10]. Суть метода заключается в том, чтобы найти кластеры, в которых наблюдения очень похожи друг на друга. Медоиды близки по смыслу центроидам, но, в отличие от них, являются объектом, принадлежащим кластеру. Визуализация метода представлена на рисунке 11.
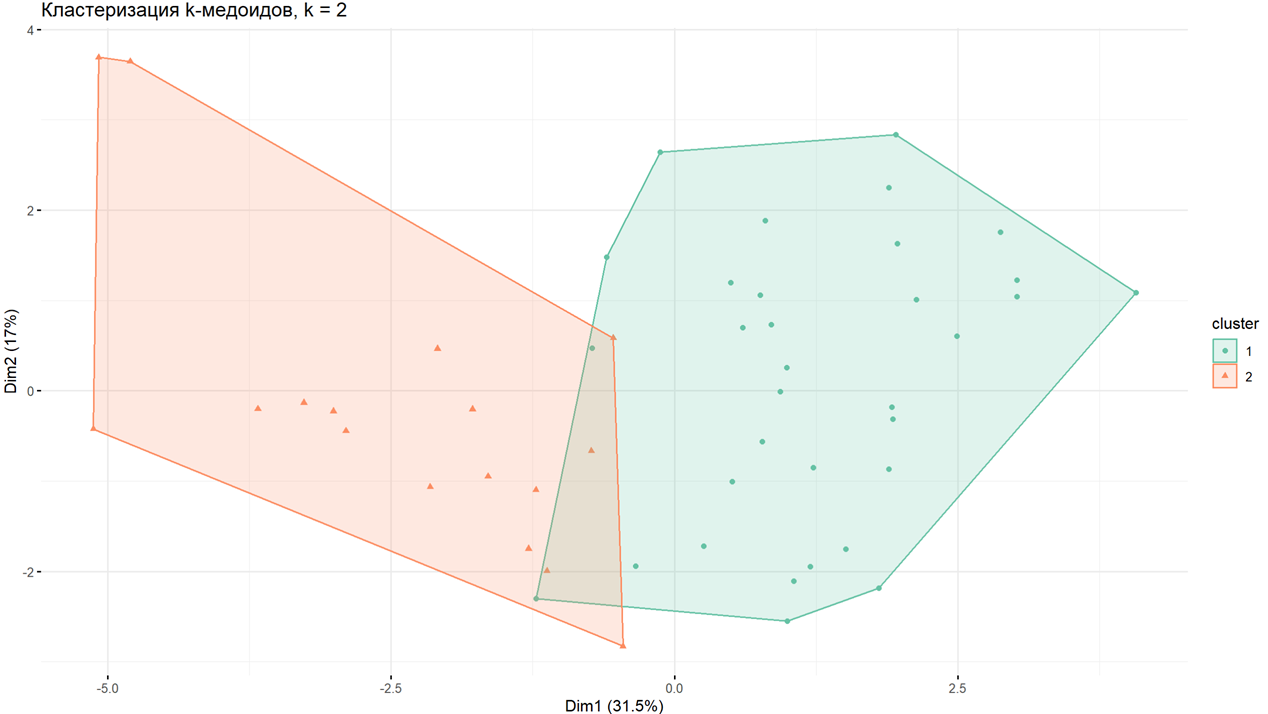
Рисунок 11 – Визуалиазция метода к -медоидов (Составлено авторами по [8,10])
Благодаря применению метода К-медоидов были сгруппированы и визуализированы два кластера. В первый кластер вошло 33 объекта, а во второй кластер 17. Подробная таблица разбиения американских штатов по кластерам представлена в таблице 2.
Таблица 2 – Информация по кластерам (Составлено авторами по [8,10])
|
Переменная
|
Среднее значение по переменной в 1 кластере
|
Среднее значение по переменной во 2 кластере
|
Состав 1 кластера
|
Состав 2 кластера
|
|
x1div
|
2,800000
|
2,894118
|
Айдахо, Айова, Алабама, Аризона, Арканзас
|
Аляска
|
|
x2mar
|
6,733333
|
6,129412
|
Вайоминг, Вермонт, Висконсин
|
Вашингтон, Виргиния
|
|
x3sal
|
54026,67
|
67438,24
|
Джорджия
|
Гавайи
|
|
x4die
|
179,4727
|
141,5176
|
Западная
Виргиния
|
Делавэр
|
|
x5unempl
|
3,636364
|
3,982353
|
Индиана
|
Иллинойс
|
|
x6gini
|
0,4644545
|
0,4685882
|
Канзас,
Кентукки
|
Калифорния, Колорадо, Коннектикут
|
|
x7dec
|
4,954545
|
5,382353
|
Луизиана
|
Массачусетс, Миннесота, Мэриленд
|
|
x9hous
|
71,05152
|
81,66471
|
Миссисипи, Миссури, Мичиган, Монтана, Мэн
|
Нью-Гэмпшир, Нью-Джерси, Нью-Йорк
|
|
x10ir
|
8,901515
|
8,264706
|
Небраска, Невада, Нью-Мексико
|
Орегон
|
|
x11we
|
38,75758
|
49,55294
|
Огайо, Оклахома
|
Род-Айленд
|
|
x12gdp
|
0,94736
|
1,18545
|
Пенсильвания
|
|
|
Северная Дакота, Северная Каролина
| ||||
|
Теннесси, Техас
| ||||
|
Флорида
| ||||
|
Южная Каролина, Южная Дакота, Юта
|
Первый кластер можно назвать традиционно-промышленным, поскольку в нем преобладают штаты со средним доходом, высокой рождаемостью и смертностью, а также с более доступным жильем.
Второй кластер можно назвать высокоразвитый, поскольку в него входят штаты, где зарплаты выше, то есть богатых людей больше, низкая смертность и высокий уровень неравенства.
По кластерам прослеживается явное деление штатов на богатые, и бедные, исходя из уровня заработной платы и распространенности высшего образования среди женщин. Также, в «богатых» штатах, то есть во 2 кластере, меньше показатель заболеваемости, поскольку там лучше развита медицина.
Если с политико-социальной точки зрения характеризовать данную группировку, то первый кластер можно назвать республиканским, где преобладают штаты с республиканской идеологией, то есть налицо уменьшение расходов на социальны выплаты и приверженность традиционным ценностям. А второй кластер демократический, где преобладают штаты с демократической идеологией, то есть акцент сделан на повышение уровня образования, поддержку социального обеспечения и открытую свободу выбора. Представленная кластеризация несет в себе обоснованные социальный, экономический и политический контекст.
Заключение
В данной работе была исследована проблема рождаемости на примере США. С каждым годом во многих странах, включая лидера по размеру ВВП США, уменьшается процент новорожденных, полноценных семей и женщин, которые хотят и готовы иметь детей.
Для анализа были взяты данные по 50 штатам Америки за 2023 год. В качестве зависимой переменной y был взят показатель – уровень рождаемость США в 2023 г., а также 12 объясняющих переменных. Авторами была получена следующая оптимальная модель взвешенного метода наименьших квадратов:
![]()
Модель имеет 8 регрессоров включая const.
В число значимых показателей вошли константа, процент женщин с высшим
образованием 25-34 лет 𝒙𝟏𝟏(we),
уровень безработицы 𝒙𝟓(unempl) и
ВВП
на душу населения по ПСС штата к ср. ВВП США ![]() (gdp).
Было выявлено следующее. При изменении % женщин с высшим образованием на 1%
рождаемость снижается на 0,51 б.е., так как растет число женщин, которые хотят
получить образование и построить карьеру, а это тяжело совместить с рождением и
воспитанием ребенка, поэтому процесс деторождения откладывается. При изменении
безработицы на 1% рождаемость снижается на 1,68 б.е., поскольку процесс
деторождения денежно-затратный, то есть он актуален для людей с высоким или
средним доходом. При изменении ВВП на 1% уровень рождаемости возрастет на 18,83,
поскольку при росте ВВП в американских штатах наблюдается экономический рост,
что позволяет сформировать денежную подушку безопасности и спланировать
рождение детей. Модель прошла ряд статистических тестов и объясняет 48% общей
дисперсии данных.
(gdp).
Было выявлено следующее. При изменении % женщин с высшим образованием на 1%
рождаемость снижается на 0,51 б.е., так как растет число женщин, которые хотят
получить образование и построить карьеру, а это тяжело совместить с рождением и
воспитанием ребенка, поэтому процесс деторождения откладывается. При изменении
безработицы на 1% рождаемость снижается на 1,68 б.е., поскольку процесс
деторождения денежно-затратный, то есть он актуален для людей с высоким или
средним доходом. При изменении ВВП на 1% уровень рождаемости возрастет на 18,83,
поскольку при росте ВВП в американских штатах наблюдается экономический рост,
что позволяет сформировать денежную подушку безопасности и спланировать
рождение детей. Модель прошла ряд статистических тестов и объясняет 48% общей
дисперсии данных.
Гипотеза, которая была выдвинута в начале исследования, подтвердилась. В ходе проведенного анализа было также выявлено, что применение регрессионного анализа способствует изучению демографической проблемы в США с высокой точностью. Использование этой методики позволила подробно изучить динамику социально-экономических показателей и определить релевантные ключевые показатели для регрессионной модели, которая способна спрогнозировать будущие значения переменных с достаточно высокой точностью.
Результаты исследования являются статистически корректными и универсальными. Они могут быть полезны для разработки или корректировки социально-экономического плана любой страны.
[1] RStudio – язык программирования для статистического анализа.
[2] Мультиколленниарность – явление, при котором наблюдается линейная зависимость между входными переменными.
[3] Гетероскедостичность – явление, при котором наблюдается неоднородность наблюдений, выражающейся в неодинаковой дисперсии случайных ошибок модели.
[4] Эндогенность – корреляция переменной с ошибками модели.
[5] F-тест – стат. тест для проверки значимости факторов в регрессионном анализе.
[6] Тест Чоу – стат. тест на наличие структурных сдвигов в выборке.
[7] Тест Рамсея – стат. тест для проверки целостности модели.
[8] Тест Бокса-Кокса – стат. тест для выбора между линейной и логарифмической моделью.
[9] Тест Уайта – стат. тест для тестирования гетероскедастичности, разработанная Х. Уайтом.
[10] Тест Голдфельда Куандта – стат. тест для тестирования гетероскедастичности.
[11] Тест Бройша Пагана - – стат. тест для тестирования гетероскедастичности.
Источники:
2. Александров Г.В. Современные тенденции развития демографической ситуации в США // Государственное управление. Электронный вестник. – 2018. – № 68. – c. 99-131.
3. Алексеева Е.А. Трансформация возрастной структуры преступников в России и за рубежом // Всероссийский криминологический журнал. – 2022. – № 1. – c. 135-146.
4. Аннаева М., Араздурдыева Ш., Аллайарова Д. Применение нормального распределения в статистике // In Situ. – 2023. – № 5. – c. 64-66.
5. Баврина А.П., Борисов И.Б. Современные правила применения корреляционного анализа // Приволжский исследовательский медицинский университет. – 2021. – № 3. – c. 70-79.
6. Базилевский М.П. Исследование новых критериев для обнаружения автокорреляции остатков первого порядка в регрессионных моделях // Математика и математическое моделирование. – 2018. – № 1. – c. 13-25.
7. Богомолова Ю.И. Демографические проблемы в США и пути их решения // Инновационные технологии в экономике и управлении: сборник материалов Всероссийской научно-практической конференции студентов и молодых ученых. Москва, 2022. – c. 30-34.
8. Гамидуллаева Л.А., Рослякова Н.А. Кластерно-эконометрический анализ российских регионов: выводы для дифференцированной экономической политики Текст научной статьи по специальности Экономика и бизнес // Экономика региона. – 2025. – № 2. – c. 283-200.
9. Голованова Е.В. Прогностический потенциал теории постиндустриализма Д. Белла // Вестник славянских культур. – 2013. – № 2. – c. 11-17.
10. Долгодворова Е.В. Кластерный анализ: базовые концепции и алгоритмы // Вопросы науки. – 2018. – № 1. – c. 1-4.
11. Кишенин П.А., Зинина А.И., Максимова Т.А. Темпы снижения рождаемости возрастают по всему миру: ловушка низкой рождаемости всё вероятнее // Демографическое обозрение. – 2024. – № 2. – c. 4-43.
12. Лисовых Е.И., Суркина Ф.Ж. Подходы к государственному регулированию демографических процессов в России и за рубежом (на примере США) // Управление качеством. – 2017. – № 18. – c. 138-142.
13. Малков С.Ю., Устюжанин В.В., Билюга С.Э., Мусиева Д.М. Демографическое и экономическое развитие стран БРИКС: моделирование и прогнозирование // Век глобализации. – 2024. – № 2. – c. 129-148.
14. Моисеев Н.А. Сравнительный анализ эффективности методов устранения мультиколлинеарности // Учет и статистика. – 2017. – № 2. – c. 62-73.
15. Орлов А.И. Распределения реальных статистических данных не являются нормальными // Политематический сетевой электронный научный журнал Кубанского государственного аграрного университета. – 2016. – № 117. – c. 71-90.
16. Петровская Н.Е. Экономические проблемы иммиграции в США // Азимут научных исследований: экономика и управление. – 2020. – № 4(33). – c. 277-280.
17. Порунов А.Н. Mathcad в руках экономиста: бокс-кокс преобразование и иллюзия Нормальности макроэкономического ряда // Бизнес-информатика. – 2010. – № 2. – c. 3-10.
18. Рождаемость в США в 2020 году упала до минимума за 40 лет. Интерфакс. [Электронный ресурс]. URL: https://www.interfax.ru/world/764766 (дата обращения: 01.12.2025).
19. Савочкин А.Е. Автоматизированная проверка гипотезы о структурной стабильности тренда посредством модификации теста Чоу // Труды Международного симпозиума Надежность и качество. – 2014. – c. 350-353.
20. Силаков Н.В. Метод обнаружения аномальных вторжений в компьютерной сети, использующий критерий Фишера // StudNet. – 2020. – № 10. – c. 60.
21. Филиппенко А.А. Демографические и политические изменения в США, отражённые в переписи населения // Россия и Америка в XXI веке. 2013-2026. – 2022. – № 2. – c. 5.
22. Хименко В.И. Диаграммы рассеяния в анализе случайных потоков событий // Журнал Информационно-управляющие системы. – 2016. – № 4. – c. 85-93.
23. Черемухин А.Д. Оценка Эффективности тестов гетероскедастичности // Вестник кибернетики. – 2024. – № 1. – c. 81-88.
24. Шалимов С.М. Модели экзогенного и эндогенного экономического роста в контексте развития экономики России // Журнал Региональное развитие: электронный научно-практический журнал. – 2015. – № 4. – c. 20.
25. Эдиев Д. М. Реконструкция показателей иммиграции в США с использованием модели демографического потенциала // Исследовано в России. – 2001. – № 14. – c. 1-14.
26. Яроменко Н.Н., Пирумян И.К., Марунич В.Г. Эконометрический анализ разводимости: основные тенденции // Вестник Академии знаний. – 2024. – № 2. – c. 540-544.
27. David N. Weil How Much Would Continued Low Fertility Affect the US Standard of Living? // Journal of Economic Perspectives. – 2026. – № 1. – p. 47-70.
28. Empowering REALTORS® to preserve, protect, and advance the right to real property for all. National Association of REALTORS. [Электронный ресурс]. URL: https://www.nar.realtor (дата обращения: 01.12.2025).
29. Explore the World Population Through Data. World Population Review. [Электронный ресурс]. URL: https://worldpopulationreview.com (дата обращения: 06.02.2026).
30. Geruso M., Spears D. The Likelihood of Persistently Low Global Fertility // Journal of Economic Perspectives. – 2026. – № 2. – p. 3-26.
31. González-Estrada E. Shapiro–Wilk test for skew normal distributions based on data transformations // Journal of Statistical Computation and Simulation. – 2019. – № 17. – p. 1-17.
32. Guzzo K., Belykh A., Manning W., Longmore M., Giordano P., Roza S. Perceptions of the Future and Pregnancy Avoidance in the U.S // Population Research and Policy Review. – 2025. – № 1. – p. 1-20.
33. Hae-Young Kim Statistical notes for clinical researchers: Chi-squared test and Fisher’s exact test // RDE. – 2017. – № 2. – p. 152-155.
34. Hamid Baghestan Factors predicting the US birth rate // Journal of Economic Studies. – 2016. – № 43. – p. 432–446.
35. Jisun Jung When massifed higher education meets shrinking birth rates: the case of South Korea // Sringer. – 2024. – № 88. – p. 2357–2373.
36. Lindström S. The Ramsey Test and the Indexicality of Conditionals — A Proposed Resolution of Gärdenfors\' Paradox // Action and Information. – 1996. – № 1. – p. 1-20.
37. Melissa S. Kearney, Phillip B. Levine Why is the Teen Birth Rate in the United States So High and Why Does It Matter? // Journal of Economic Perspectives. – 2012. – № 26. – p. 141-166.
38. Paula E. Gobbi, Anne Hannusch, and Pauline Rossi. Family Institutions and the Global Fertility Transition // Journal of Economic Perspectives. – 2026. – № 2. – p. 47-70.
Страница обновлена: 24.07.2026 в 16:12:55
Download PDF | Downloads: 6
Methodology for assessing the level and prospects of demographic development in the United States
Maksimtsev I.A., Kostin K.B., Malevich Y.V., Kurgina S.M.Journal paper
Journal of Economics, Entrepreneurship and Law
Volume 16, Number 5 (May 2026)
Abstract:
The article analyzes the results of scientific research by leading domestic and foreign economists devoted to the concept of increasing the level of demography.
The article presents the results of econometric and cluster analysis, on the basis of which the universal methodology for assessing the level of country's demographic development on the example of the United States is formed. The article provides universal proposals aimed at increasing the level of demography. The article may be useful to experts in the field of global economics and international business, as well as researchers dealing directly with demographic issues.
Keywords: world economy, econometrics, MNC, demography, regression analysis
JEL-classification: C21, C32, C42, C51
References:
Agibalova E.L., Karzhanova N.V. (2024). Economic Development and Foreign Trade: a Comparative Analysis of the United States and China. REU.RF. (39). 65-77.
Aleksandrov G.V. (2018). Current trends in the demographic situation in the United States. Public administration. Electronic Bulletin. (68). 99-131.
Alekseeva E.A. (2022). Transformation of the Age Structure of Criminals in Russia and Abroad. Vserossiyskiy kriminologicheskiy zhurnal. (1). 135-146.
Annaeva M., Arazdurdyeva Sh., Allayarova D. (2023). Applications of the Normal Distribution in Statistics. In Situ. (5). 64-66.
Bavrina A.P., Borisov I.B. (2021). Modern Rules of the Application of Correlation Analysis. Privolzhskiy issledovatelskiy meditsinskiy universitet. (3). 70-79.
Bazilevskiy M.P. (2018). Research of New Criteria for Detecting First-Order Residuals Autocorrelation in Regression Models. Matematika i matematicheskoe modelirovanie. (1). 13-25.
Bogomolova Yu.I. (2022). Demographic problems in the United States and ways to solve them Innovative technologies in economics and management. 30-34.
Cheremukhin A.D. (2024). Evaluating Effectiveness of Tests for Heteroscedasticity. Vestnik kibernetiki. (1). 81-88.
David N. (2026). Weil How Much Would Continued Low Fertility Affect the US Standard of Living? Journal of Economic Perspectives. (1). 47-70.
Dolgodvorova E.V. (2018). Cluster analysis: basic concepts and algorithms. Voprosy nauki. (1). 1-4.
Ediev D. M. (2001). Reconstruction of immigration indicators in the United States using the demographic potential model. Issledovano v Rossii. (14). 1-14.
Empowering REALTORS® to preserve, protect, and advance the right to real property for allNational Association of REALTORS. Retrieved December 01, 2025, from https://www.nar.realtor
Explore the World Population Through DataWorld Population Review. Retrieved February 06, 2026, from https://worldpopulationreview.com
Filippenko A.A. (2022). Demographic and Political Changes in the United States Reflected in the Census. Rossiya i Amerika v XXI veke. 2013-2026. (2). 5.
Gamidullaeva L.A., Roslyakova N.A. (2025). Cluster-Econometric Analysis of Russian Regions: Implications for Differentiated Economic Policy (Rus.). Economy of the region. (2). 283-200.
Geruso M., Spears D. (2026). The Likelihood of Persistently Low Global Fertility Journal of Economic Perspectives. (2). 3-26.
Golovanova E.V. (2013). Potential for Prediction in the Post-industrial Theory by D. Bell. Vestnik slavyanskikh kultur. (2). 11-17.
González-Estrada E. (2019). Shapiro–Wilk test for skew normal distributions based on data transformations Journal of Statistical Computation and Simulation. 89 (17). 1-17.
Guzzo K., Belykh A., Manning W., Longmore M., Giordano P., Roza S. (2025). Perceptions of the Future and Pregnancy Avoidance in the U.S Population Research and Policy Review. (1). 1-20.
Hae-Young Kim (2017). Statistical notes for clinical researchers: Chi-squared test and Fisher’s exact test RDE. (2). 152-155.
Hamid Baghestan (2016). Factors predicting the US birth rate Journal of Economic Studies. (43). 432–446.
Jisun Jung (2024). When massifed higher education meets shrinking birth rates: the case of South Korea Sringer. (88). 2357–2373.
Khimenko V.I. (2016). Scatterplots in Analysis of Random Streams of Events. Zhurnal Informatsionno-upravlyayuschie sistemy. (4). 85-93.
Kishenin P.A., Zinina A.I., Maksimova T.A. (2024). The Intensity of Fertility Decline Is Increasing Worldwide: Is a Low Fertility Trap Increasingly Likely. Demographic Review. (2). 4-43.
Lindström S. (1996). The Ramsey Test and the Indexicality of Conditionals — A Proposed Resolution of Gärdenfors\' Paradox Action and Information. (1). 1-20.
Lisovyh E.I., Surkina F.Zh. (2017). Approaches to the Regulation of Demographic Processes in Russia and Abroad (in the Example of the USA). Quality management. (18). 138-142.
Malkov S.Yu., Ustyuzhanin V.V., Bilyuga S.E., Musieva D.M. (2024). Modeling and Forecasting the Demographic and Economic Development of BRICS Countries. Vek globalizatsii. (2). 129-148.
Melissa S. Kearney, Phillip B. Levine (2012). Why is the Teen Birth Rate in the United States So High and Why Does It Matter? Journal of Economic Perspectives. (26). 141-166.
Moiseev N.A. (2017). Comparative analysis of the effectiveness of multicollinearity elimination methods. Uchet i statistika. (2). 62-73.
Orlov A.I. (2016). Distributions of Real Statistical Data Are Not Normal. Scientific Journal of KubSAU. (117). 71-90.
Paula E. (2026). Gobbi, Anne Hannusch, and Pauline Rossi. Family Institutions and the Global Fertility Transition Journal of Economic Perspectives. (2). 47-70.
Petrovskaya N.E. (2020). Economic Problems of Immigration to the United States. ASR: Economics and Management. (4(33)). 277-280.
Porunov A.N. (2010). Mathcad in Hands of the Economist: Box-Cox Transformation and the Illusion of Normality of Macroeconomic Series. Biznes-informatika. (2). 3-10.
Savochkin A.E. (2014). Automated verification of the hypothesis about the structural stability of the trend by modifying the Chow test. Trudy Mezhdunarodnogo simpoziuma Nadezhnost i kachestvo. 1 350-353.
Shalimov S.M. (2015). Exogenous and Endogenous Economic Growth Models in the Context of Russian Economic Development. Zhurnal Regionalnoe razvitie: elektronnyy nauchno-prakticheskiy zhurnal. (4). 20.
Silakov N.V. (2020). A Method for Detecting Abnormal Intrusions in a Computer Network That Uses the Fisher Criterion. StudNet. (10). 60.
Yaromenko N.N., Pirumyan I.K., Marunich V.G. (2024). Econometric Analysis of Divorce Rates: Key Trends. Vestnik Akademii znaniy. (2). 540-544.