Panel data in the analysis of the regional agro-industrial complex
Ledneva O.V.1![]() , Tindova M.G.1
, Tindova M.G.1![]()
1 Негосударственное частное образовательное учреждение высшего образования Московский финансово-промышленный университет «Синергия»
Journal paper
Food Policy and Security (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Volume 12, Number 2 (April-June 2025)
Abstract:
The article evaluates the potential applications of panel data analysis tools for identifying hidden trends in regional agro-industrial complexes. The article discusses key spatiotemporal econometric analysis methods and models, such as pool, fixed-effect, and random-effect models. These models have been applied to analyze the agro-industrial potential of Russian regions. In the first stage, three models were developed: a pooled model assuming the absence of economic objects' individual characteristics, a fixed effects model assuming the presence of individual characteristics that remain unchanged over time, and a random effects model in which individual characteristics are random variables. The second stage of the study involved evaluating the adjusted coefficients of determination for each model, as well as testing the Hausman, Breusch-Pagan, and Wald tests.
Based on the modeling results, the model best describing the behavior of subjects in the Russian Federation in agricultural production was determined. The fixed-effects model serves as such a model. This is because the factors that determine agricultural production in each region are unique and stationary.
The analysis demonstrates the effectiveness of using panel data tools to study the dynamics of the agro-industrial complex's development in Russia's regions. These tools allow us to identify implicit correlations and hidden factors that were not directly used in the analysis.
Keywords: panel data, regional agro-industrial complex, pool model, fixed effects model, random effects model
JEL-classification: L90, L91, R40
Введение
Развитие инструментария анализа динамических данных неразрывно связано с развитием технических средств, применяемых в процессе этого анализа. В частности, качественный скачок произошел в 80-е годы 20 века, когда с появлением ЭВМ стала возможной обработка больших массивов информации, а именно панельных данных.
Под панельными данными понимается пространственно-временной массив информации, в котором пространственная часть представляет собой статическую причинно-следственную взаимосвязь экономических переменных. При этом желательно, чтобы одна из экзогенных переменных имела географическую привязку (например, сравнение эндогенной переменной по странам, городам, различным предприятиям и пр.). Временная часть панельного массива – это изменение всех рассматриваемых переменных во времени [1].
Следует отметить, что при формировании панельных данных к пространственной части применяются все требования, предъявляемые к пространственной информации, в частности, отсутствие мультиколлениарности между переменными; к временной части – требования, предъявляемые к динамическим рядам, в частности, требование сопоставимости рядов [2].
Сегодня панельные данные являются хорошим инструментом анализа экономической информации, и существует достаточно много работ, посвященных применению данного инструмента в анализе и прогнозировании различных экономических процессов.
Например, большая группа работ показывает целесообразность использования инструментария анализа панельных данных при оценке различного вида экономических рисков. Так, в работе Тростянского С.Н. оценивается вероятность возникновения пожаров в регионах России [3]; в работе Полякова К.Л. оценивается вероятность риска банкротства коммерческих банков [4]; в работе Сиротина В.П. оцениваются политические риски в моделях инвестирования развивающихся экономик [5].
Другая группа работ посвящена изучению возможностей применения панельных данных в оценке деятельности промышленных предприятий. Например, в работе Бахитовой Р.Х. проводится классификация регионов России по схожести производственных функций, лежащих в основе оценки объема выпускаемой ими продукции [6]. В работе Авдейчик О.В. проводится оценка инновационной деятельности промышленных предприятий [7].
Достаточно часто инструментарий анализа панельных данных применяется в анализе секторов и отраслей российской экономики: нефтяного сектора [8], лесопромышленного сектора [9], туристической отрасли [10].
Применение методов панельных данных в анализе зависимости численности сельского населения муниципальных образований Ленинградской области от уровня развития сельского хозяйства рассматривается в работе Никулиной Ю. Н. [11]. Оценка выпуска продукции животноводства регионов Нечерноземной зоны России на валовой выпуск региона с помощью эконометрических моделей панельных данных с фиксированными и случайными эффектами нашло отражение в работе Юрченко Т.В. [12].
Актуальность настоящего исследования обусловлена оценкой агропромышленной отрасли РФ, в частности, региональный аспект эффективности государственных инвестиций, активно поступающих в данный сегмент экономики, начиная с 2014 года, с момента введения ограничительных санкций на АПК России и принятия Правительством РФ Доктрины продовольственной безопасности РФ [13], используя инструментарий анализа панельных данных, чего ранее не было сделано.
Авторская гипотеза состоит в предположении того, что регионы РФ обладают индивидуальными особенностями, которые невозможно описать количественными переменными и использовать для их оценки классические методы анализа временных рядов или модели регрессии. Использование панельных данных даст возможность получить оценку специфических характеристик рассматриваемых АПК регионов страны.
В качестве объекта исследования выступает сектор АПК всех восьми федеральных округов РФ. В качестве переменных, описывающих динамику развития АПК каждого региона были рассмотрены: у – продукция сельского хозяйства, млрд.руб., х1 – посевные площади сельскохозяйственных культур, млн.га, х2 – число предприятий и организаций в АПК, тыс.шт., х3 – инвестиции в основной капитал в сфере АПК, млрд.руб., х4 – ввод основных фондов в сфере АПК, млрд.руб. В качестве временного интервала исследования был рассмотрен период с 2012 по 2023 год [14].
Материалы и методы
Использование инструментов анализа панельных данных с целью выявления скрытых тенденций, основывается на сравнении трех моделей: модели пула, модели с фиксированным эффектом и модели со случайным эффектом [15].
На первом шаге
моделирования построим модель пула (Pool
model) – регрессию по
объединенной выборке, предполагая отсутствие неоднородности между
пространственными объектами: ![]() ,
,
![]() .
.
Применяя обычный МНК-метод, получаем уравнение:
![]() .
.
Коэффициент
детерминации полученной модели равен ![]() и
он значим по критерию Фишера. Параметры данной регрессии являются несмещенными
и эффективными оценками, а при
и
он значим по критерию Фишера. Параметры данной регрессии являются несмещенными
и эффективными оценками, а при ![]() или
или
![]() являются
и состоятельными оценками коэффициента b
регрессии. Таким образом, их значимость может быть проверена с помощью критерия
Стьюдента:
являются
и состоятельными оценками коэффициента b
регрессии. Таким образом, их значимость может быть проверена с помощью критерия
Стьюдента: ![]() .
.
Далее построим модель регрессии с фиксированным эффектом (FE):
![]() ,
где параметр
,
где параметр ![]() принимает
различные значения для каждого экономического объекта выборки. Его смысл в том,
чтобы отразить влияние ненаблюдаемых переменных, характеризующих индивидуальные
особенности исследуемых объектов, в нашем случае – субъектов РФ, не меняющихся
во времени. Значения параметра
принимает
различные значения для каждого экономического объекта выборки. Его смысл в том,
чтобы отразить влияние ненаблюдаемых переменных, характеризующих индивидуальные
особенности исследуемых объектов, в нашем случае – субъектов РФ, не меняющихся
во времени. Значения параметра ![]() могут
отличаться между объектами, но для каждого конкретного объекта он не меняется с
течением времени t.
могут
отличаться между объектами, но для каждого конкретного объекта он не меняется с
течением времени t.
Для построения данной
регрессии использует метод корректировки на индивидуальные средние: ![]() ,
где
,
где ![]() ,
,
![]() ,
,
![]() [15].
[15].
Используя МНК-метод, в нашем случае получаем уравнение:
![]() ,
где
,
где ![]() и
он значим. Полученные оценки, которые также называются внутригрупповые,
состоятельны только при
и
он значим. Полученные оценки, которые также называются внутригрупповые,
состоятельны только при ![]() и
и
![]() .
.
Фиксированные эффекты
находятся с помощью равенства: ![]() ,
,
![]() ,
которые являются несмещенными и состоятельными для фиксированного n
при
,
которые являются несмещенными и состоятельными для фиксированного n
при ![]() .
.
Таким образом, в нашем случае, влияние ненаблюдаемых переменных, характеризующих индивидуальные особенности субъектов РФ, представлены в таблице.
Таблица - Индивидуальный эффект влияния факторов на продукцию сельского хозяйства по субъектам РФ модели с фиксированными эффектами
|
|
Посевные площади сельскохозяйственных
культур, млн. га
|
Число предприятий и организаций в АПК,
тыс. шт.
|
Инвестиции в основной капитал в сфере
АПК, млрд. руб.
|
Ввод основных фондов в сфере АПК,
млрд. руб.
|
|
РФ
|
-3987,7
|
7480,2
|
4225,3
|
3245,5
|
|
ЦФО
|
-428,7
|
1882,8
|
1093,3
|
713,7
|
|
С-ЗФО
|
61,6
|
499,7
|
180,7
|
96,8
|
|
ЮФО
|
-551,5
|
1094,7
|
764,2
|
645,9
|
|
С-КФО
|
-80,6
|
728,02
|
369,6
|
303,2
|
|
ПФО
|
-1531,6
|
1583,03
|
1022,8
|
812,2
|
|
УФО
|
-298,7
|
443,5
|
261,4
|
197,7
|
|
СбФО
|
-1074,2
|
913,2
|
495,5
|
378,1
|
|
ДФО
|
-67,4
|
336,5
|
143,4
|
101,6
|
Полученные значения говорят о том, что например для ПФО, факторы, которые присущи данному региону (например, географическое положение, инфраструктура, управленческий менеджмент и пр.) снижают посевные площади, увеличивают количество предприятий АПК, привлекают дополнительные инвестиции в АПК и увеличивают ввод основных фондов. Все это говорит о том, что ПФО является аграрным регионом, позволяющим при меньших площадях получать более высокие показатели работы АПК.
На следующем этапе
анализа построим модель со случайным эффектом (RE):
![]() ,
где
,
где ![]() –
ошибка модели, в которой слагаемое
–
ошибка модели, в которой слагаемое ![]() –
случайные эффекты, отражающие наличие у субъектов исследования некоторых
индивидуальных характеристик, не изменяющихся со временем, которые трудно
наблюдать или измерить. И поскольку ошибка классической регрессионной модели
возникает за счет невозможности включения в модель всех объясняющих переменных,
то такие индивидуальные эффекты включаются в общую погрешность модели. Здесь
–
случайные эффекты, отражающие наличие у субъектов исследования некоторых
индивидуальных характеристик, не изменяющихся со временем, которые трудно
наблюдать или измерить. И поскольку ошибка классической регрессионной модели
возникает за счет невозможности включения в модель всех объясняющих переменных,
то такие индивидуальные эффекты включаются в общую погрешность модели. Здесь ![]() .
.
Для построения модели со случайным эффектом используется следующий алгоритм [16]:
1. находим ![]() и
по полученным значениям строим регрессию:
и
по полученным значениям строим регрессию: ![]() ;
;
2. по полученной
регрессии находим остаточную дисперсию ![]() ;
;
3. находим ![]() –
остаточную дисперсию из модели с фиксированными эффектами:
–
остаточную дисперсию из модели с фиксированными эффектами: ![]() ;
;
4. находим ![]() ;
;
5. находим веса ![]() и
и
![]() ;
;
6. переходим к новым
переменным: ![]() и
и
![]() и
строим по ним регрессию:
и
строим по ним регрессию: ![]() .
.
В последней регрессии ![]() и
он значим, параметры модели, называемые также межгрупповыми параметрами,
являются несмещенными.
и
он значим, параметры модели, называемые также межгрупповыми параметрами,
являются несмещенными.
Алгоритм, применяемый
для построения модели со случайным эффектом, основывается на обобщенном
МНК-методе и дает модель, которая является средневзвешенным между межгрупповой
оценкой, учитывающей только межгрупповую изменчивость, и внутригрупповой оценкой,
учитывающей только внутригрупповую изменчивость, весами же являются
коэффициенты ![]() ,
показывающие межгрупповую изменчивость.
,
показывающие межгрупповую изменчивость.
Результаты
Выше было построено три модели регрессии: модель пула, которая строилась по общей выборке и не учитывала никакие индивидуальные характеристики экономических объектов; модель с фиксированным эффектом, в которой предполагается наличие неизменных во времени индивидуальных характеристик для каждого экономического объекта исследования; модель со случайным эффектом, в которой индивидуальные характеристики являются случайными величинами.
Таким образом, возникает задача оценки качества полученных регрессий и выбора лучшей модели.
В обычном регрессионном
анализе в качестве меры оценки полученного уравнения регрессии используется
коэффициент детерминации ![]() ,
показывающий долю объясненной вариации зависимой переменной. В моделях с
панельными данными понятие коэффициента детерминации требует уточнения,
поскольку внутригрупповая и межгрупповая регрессии имеют дело с разными
вариациями зависимой переменной, а также, поскольку используется обобщенный, а
не обычный МНК-метод.
,
показывающий долю объясненной вариации зависимой переменной. В моделях с
панельными данными понятие коэффициента детерминации требует уточнения,
поскольку внутригрупповая и межгрупповая регрессии имеют дело с разными
вариациями зависимой переменной, а также, поскольку используется обобщенный, а
не обычный МНК-метод.
Основываясь на том, что
коэффициент детерминации равен квадрату коэффициента корреляции между ![]() и
прогнозным значением
и
прогнозным значением ![]() ,
положим [17]:
,
положим [17]:
- для внутригрупповой
регрессии (т.е. модели с фиксированным эффектом) ![]() ,
где
,
где ![]() –
квадрат выборочного коэффициента корреляции;
–
квадрат выборочного коэффициента корреляции; ![]() ;
объем выборки равен nT;
;
объем выборки равен nT;
- для межгрупповой
регрессии ![]() ,
где
,
где ![]() ;
;
- для обычной модели
коэффициент объединенной детерминации ![]() ,
где
,
где ![]() .
.
В нашем случае: ![]() ;
;
![]() ;
;
![]() .
.
С целью выбора лучшей модели используется ряд тестов [18]:
- для сравнения модели
пула с моделью с фиксированным эффектом: выдвигается гипотеза ![]() ,
что соответствует модели с одним и тем же параметром a
для всех объектов наблюдения (модель пула) против альтернативной гипотезы
,
что соответствует модели с одним и тем же параметром a
для всех объектов наблюдения (модель пула) против альтернативной гипотезы ![]() (модель
с фиксированным эффектом); тестовая статистика
(модель
с фиксированным эффектом); тестовая статистика ![]() ,
где
,
где ![]() –
коэффициент множественной корреляции модели с фиксированными эффектами,
–
коэффициент множественной корреляции модели с фиксированными эффектами, ![]() –
коэффициент множественной корреляции модели пула; если
–
коэффициент множественной корреляции модели пула; если ![]() следует
выбрать модель пула, в противном случае – модель с фиксированным эффектом;
следует
выбрать модель пула, в противном случае – модель с фиксированным эффектом;
- для сравнения модели
пула с моделью со случайным эффектом используется тест Бройша-Пагана:
выдвигается гипотеза ![]() (модель пула); статистика критерия
(модель пула); статистика критерия 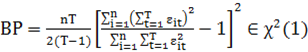 ,
где остатки берутся из модели пула; если
,
где остатки берутся из модели пула; если ![]() ,
то следует выбрать модель пула, в противном случае – модель со случайным
эффектом;
,
то следует выбрать модель пула, в противном случае – модель со случайным
эффектом;
- для сравнения модели
со случайными эффектами с моделью с фиксированными эффектами используется тест
Хаусмана: ![]() ;
;
![]() ;
статистика
;
статистика ![]() ,
где
,
где ![]() –
оценка матрицы ковариаций
–
оценка матрицы ковариаций ![]() ;
если
;
если ![]() ,
то следует выбрать модель со случайным эффектом, в противном случае – модель с
фиксированным эффектом.
,
то следует выбрать модель со случайным эффектом, в противном случае – модель с
фиксированным эффектом.
В нашем случае, в
первом тесте ![]() ,
поэтому гипотеза Н0 отклоняется и необходимо выбрать модель с
фиксированным эффектом. Во втором тесте
,
поэтому гипотеза Н0 отклоняется и необходимо выбрать модель с
фиксированным эффектом. Во втором тесте ![]() ,
следовательно гипотеза Н0 отклоняется и необходимо выбрать модель со
случайным эффектом. В третьем тесте
,
следовательно гипотеза Н0 отклоняется и необходимо выбрать модель со
случайным эффектом. В третьем тесте ![]() ,
поэтому гипотеза Н0 отклоняется и необходимо выбрать модель с
фиксированным эффектом.
,
поэтому гипотеза Н0 отклоняется и необходимо выбрать модель с
фиксированным эффектом.
В результате можно
сделать следующие выводы. Во-первых, в процессе формирования продукции
сельского хозяйства по регионам РФ присутствуют индивидуальные эффекты, которые
обусловлены факторами, характерными для каждого отдельного региона РФ.
Во-вторых, данные индивидуальные эффекты носят фиксированный характер, что
подтверждается тестом Вальда и тестом Хаусмана, т.е. факторы, определяющие
производство сельхозпродукции в каждом регионе свои и они не меняются там во
времени. В-третьих, несмотря на то, что качество полученной модели со случайным
эффектом выше (больше ![]() ,
параметры более статистически значимы, что следует из более высокой
состоятельности оценок RE-модели),
дополнительные тесты показывают ее необоснованность в качестве модели
аппроксимации.
,
параметры более статистически значимы, что следует из более высокой
состоятельности оценок RE-модели),
дополнительные тесты показывают ее необоснованность в качестве модели
аппроксимации.
Заключение
Рассмотренный в работе пример использования инструментов анализа панельных данных к исследованию регионального АПК, показал их возможности в оценке скрытых зависимостей и выявлении факторов, не участвующих в исследовании явным образом.
Полученный в работе результат – наличие фиксированных индивидуальных эффектов в АПК-деятельности экономических объектов – согласуется с тем фактом, что модели с фиксированными эффектами обычно используются в ситуациях, когда экономические объекты нельзя рассматривать как случайную выборку из некоторой более широкой совокупности (популяции). В нашем случае – федеральные округа, рассмотренные в работе, представляют собой всю генеральную совокупность.
Модели со случайными эффектами используются тогда, когда исследователя интересуют не конкретные экономические объекты, а обезличенные образы, имеющие заданные характеристики.
References:
Avdeychik O. V., Furman N. L., Medvedev V. F. (2014). Econometric models of innovative activity of industrial enterprises in Belarus. Vestnik Grodnenskogo gosudarstvennogo universiteta imeni Yanki Kupaly. Seriya 5. Ekonomika. Sotsiologiya. Biologiya. (2). 37-44.
Babeshko L. O. (2016). Econometric forecasting based on heterogeneous information Moscow: Obshchestvo s ogranichennoy otvetstvennostyu «Vega-Info».
Bakhitova R. Kh., Akhmetshina G. A., Lakman I. A. (2014). Panel modeling of production output in Russian regions. Large-Scale Systems Control. (50). 99-109.
Gelman V. Ya. (2014). Analysis of international tourism features in the Russian Federation. Vestnik of National Tourism Academy. (1). 24-27.
Hausman J. A. (1978). Specification tests in econometrics Econometrica. (46). 1251–1271.
Lapo V. F. (2014). Efficiency of investment stimulation methods in a timber industry complex: an econometric research. Prikladnaya ekonometrika. (1). 30-50.
Magnus Ya. R. (2021). Econometrics. The initial course Moscow: Izdatelskiy dom «Delo» RANKhiGS,.
Nikulina Yu. N., Yurchenko T. V., Surovtsev V. N. (2021). Rural population dependence on the level of agricultural development: panel data analysis of Leningrad oblast. Population. 24 (1). 90-102. doi: 10.19181/population.2021.24.1.9.
Nikulina Yu.N., Yurchenko T.V., Surovtsev V.N. (2021). Rural population dependence on the level of agricultural development: panel data analysis of Leningrad oblast. Population. 24 (1). 90-102. doi: 10.19181/population.2021.24.1.9.
Nosko V. P. (2005). Econometrics for Beginners (Additional Chapters)
Polyakov K. L., Polyakova M. V. (2013). The specifics of assessing the sustainability of commercial banks in the Russian conditions. “Bulletin of Statistics\\. (12). 35-44.
Sirotin V. P., Bychenkov D. V. (2013). Political risk as a factor of foreign direct investment into transition economies. Izvestiya Saratovskogo universiteta. Novaya seriya. Seriya: Ekonomika. Upravlenie. Pravo. 13 (4-1). 513-521.
Tindova M. G. (2016). Panel data analysis in the model of GDP formation "Mathematical models of complex systems and methods of their analysis" Computer science and Information technology. 421-423.
Trostyanskiy S. N., Skryl S. V., Gromov Yu. Yu. [i dr.] (2014). Econometric approach to the fire risk management for Russian regions. Pribory i sistemy. Upravlenie, kontrol, diagnostika. (5). 24-31.
Valitov Sh. M., Ankudinov A. B., Lebedev O. V. (2013). Microeconomic analysis of crude oil production and investment spending growth rates in the oil sector of Russian economy. Neftyanoe khozyaystvo. (10). 86-87.
Yurchenko T. V., Surovtsev V. N. (2024). Regional variations in the role of dairy farming in agriculture of Russia's non-black earth zone. Economy of the region. 20 (4). 1175-1189. doi: 10.17059/ekon.reg.2024-4-13.
Страница обновлена: 30.04.2025 в 23:25:38