Использование интернет-сервисов по поиску работы для оценки влияния технологий на спрос на труд
Рудаков И.О.1![]()
1 Центральный экономико-математический институт, ,
Скачать PDF | Загрузок: 25
Статья в журнале
Креативная экономика (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 18, Номер 8 (Август 2024)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=69154041
Аннотация:
В научной литературе часто обсуждают влияние современных технологий на спрос на труд. Одни исследователи считают, что цифровые технологии будут приводить к замещению труда роботизированными системами и снижению занятости; другие полагают, что новые технологии будут приводить к росту спроса на работников, умеющих обращаться с этими технологиями. Одним из источников подтверждения или опровержения данных точек может стать открытая информация с интернет-сервисов по поиску работы.
В работе была обработана и проанализирована информация по вакансиям из свободной базы данных сервиса по поиску работы HeadHunter. На основе анализа была выявлена разница в спросе на творческие и умственные профессии по вакансиям между Москвой и остальной Россией, зафиксирована поляризация работников по уровню заработной платы, сделана попытка оценки влияния разных навыков в описании вакансии на соответствующую этой вакансии заработную плату. Проведенный анализ сигнализирует о верности гипотез техно-скептиков: новые технологии увеличивают спрос и зарплаты на специалистов, владеющими этими технологиями.
Статья будет интересна исследователям влияния технологий на труд.
Ключевые слова: оценка влияния технологий на спрос на труд, влияние навыков на зарплату, поляризация работников по зарплате, спрос на труд, интернет-сервисы по поиску работы
Финансирование:
Исследование выполнено при финансовой поддержке гранта РНФ № 23-28-00358 «Институциональные и структурные условия адаптации к шокам экономического развития»
Введение
Существует значительное количество исследований, посвященных изучению влияния новых технологий на общий объем трудовых ресурсов. Выводы и прогнозы исследователей можно условно разделить на две основные категории: сторонники технологического оптимизма утверждают, что процесс замещения трудовых ресурсов капиталом будет протекать быстрее, чем способность людей адаптироваться к новым технологическим условиям, в то время как сторонники технологического скептицизма считают, что трудовые ресурсы смогут успешно адаптироваться к изменениям.
Аргументация техно-оптимистов основывается на предположении, что автоматизация позволит организовать производственные процессы с минимальным участием человека. Согласно выводам, которые делают Д. Аджемоглу и П. Рестрепо, новые рабочие места, возникающие вследствие автоматизации, во-первых, значительно уступают в количестве замещаемым рабочим местам на уровне предприятия, а во-вторых, требуют принципиально иного уровня квалификации и набора навыков [4, стр. 1-45] В подтверждение своей гипотезы авторы исследовали, что в производствах, где растет доля роботов (капитала) доля работников (труда) уменьшается [5, 1-92].
Также можно выделить работу В. Маринуди и др. [13, c. 3-18], в которой авторы провели сегментирование трудовых задач в сельскохозяйственном секторе по осям рутинный-творческий, физический-умственный труд; а также сделали прогноз эффекта внедрения роботизации на эти задачи и профессии, которые подразумевают выполнение этих задач. Исследованием изменения структуры трудового капитала, в том числе под воздействием новых технологий, занимались В. Е. Гимпельсон, А. А.Зудина, Р. И Капелюшников [1, c. 1-148]
Вторая группа исследователей, техно-скептики, обосновывает маловероятность массовой безработицы, вызываемой автоматизацией. Исследования влияния новых технологий на безработицу, поляризации рынка труда и изменения его структуры на макроэкономическом уровне с использованием статистических методов проводилось такими учеными как Д. Аутор [7, с. 1553-1597], М. Диллиндер [9, с. 290-310], В.Даут [8, с. 1-63], и Г. Гретц [11, с. 753-768]. В этих исследованиях авторы отмечают увеличение совокупного спроса на труд после внедрения технологий в различных секторах экономики и в разные временные периоды.
Одной из первых попыток структурирования и систематизации методик и оценок влияния технологий на труд занимался Б. Мартенс [14, c. 5-33]. Прогнозированием и оценкой воздействия новых технологий в будущем занимались M. Арнтц [6, с. 254-280], К. Фрей [10, c. 254-280], Бессен Дж. [12, с. 5-55], Капелюшников Р. [2, с. 32-36], и Устюжанина Е.В. [3, с. 1788-1804]
Цель данной статьи состоит в том, чтобы оценить влияние технологий на спрос на труд используя данные сервиса по поиску работы в сети интернет. Для достижения этой цели необходимо выполнить ряд подзадач: (1) оценить качество данных, получаемых с сервисов поиска работы; (2) понять, какую информацию можно получить из этих данных, чтобы ответить на вопрос задачи; (3) произвести расчеты и обсудить, насколько они позволяют ответить на вопрос об оценке влияния технологий на спрос на труд.
Научная новизна данной работы состоит в использовании в анализе уникального набора данных из сервиса по поиску работы HeadHunter; а также использование LLM-модели (Chat GPT) для получения данных по требуемым в вакансиях технологических программах.
Оригинальность подхода состоит в создании системы показателей направления влияния новых технологий на совокупный спрос на труд, которая может помочь определить, приводит ли распространение новых технологий к росту спроса на труд или к его замещению; т.е. поможет понять, какой из прогнозных сценариев реализуется в конкретный момент времени.
Авторская гипотеза состоит в том, что обработка данных с сервисов по поиску работы вместе с возможностями LLM моделей по извлечению информации из текстовых данных позволит понять направление и величину влияния новых технологий на спрос на труд.
Методология сбора данных и их качество
Для анализа была использована база данных вакансий HeadHunter. Подключение к ней осуществлялось с помощью Hedhunter API, который предлагает сама компания.
Открытая (бесплатная) база данных HeadHunter содержит информацию об открытых на момент подключения вакансиях. Каждая из вакансий может быть описана большим количеством различных параметров, которые задает компания. Одним из важных параметров вакансии является её профессиональная группа, определяемая компанией.
Подключение позволяет забирать не более 2000 вакансий по каждой из профессиональных групп. На апрель 2024 в базе данных было представлено 174 профессиональные группы для периода. Сбор данных происходил в начале и конце рассматриваемых месяцев, с дальнейшим удалением дубликатов.
Также подключение дает доступ к агрегированной информации по количеству вакансий в разбивке по регионам РФ. В этом случае выгружается полная информация о количестве вакансий; ограничения только в периодах, за которые эти данные могут быть получены.
Ограничение в 2000 вакансий несет в себе риск того, что данные по профессиональным группам, в которых на сервисе имеется больше вакансий, могут не быть репрезентативной выборкой этой группы, а следовательно результаты анализа не могут быть применены в полной мере на эту группу. Невозможно обойти данное ограничение (по крайней мере, в бесплатной версии), однако можно оценить степень этого риска с помощью агрегированной информации о вакансиях. Чем выше доля выгружаемых 2000 вакансий от общего количества вакансий в группе, тем ниже риск низкой репрезентативности. Для проверки обозначенных гипотез, этот риск можно принять и игнорировать.
Отдельно стоит отметить риски ограничения репрезентативности при использовании одного источника данных. В рамках статьи используется только база данных HeadHunter. Сервис HeadHunter является одним из крупнейших сервисов по поиску работы, и соответственно данных по вакансиям. Однако это не решает проблему репрезентативности. В базе данных платформы находятся вакансии компаний, которые посчитали, что платформа позволит наиболее эффективно найти соискателей на эти вакансии. Это означает, что у разных категорий вакансий существуют разные каналы привлечения соискателей. Так, для найма курьеров (таксистов и многих других) Яндекс использует свои ресурсы: рекламу для соискателей в своих продуктах, отдельные сайты для публикации вакансий и отклика на неё. Это справедливо для многих крупных работодателей России. Также существуют отдельные категории профессий и работ, вакансии на которые публикуются только на бумажных носителях.
Дальнейший анализ и выводы могут быть применимы только к конкретной платформе (HeadHunter), или к сегменту людей, которые используют эту платформу в качестве основного.
Методология расчетов будет описана далее по тексту по мере необходимости.
Работа разбита на несколько логических разделов. Вначале будет дана характеристика использованных данных и способ их получения. Во втором разделе будет рассмотрено сравнение спроса на труд по профессиональным ролям между Москвой и остальной Россией. На третьем этапе будет представлен анализ зарплаты работников в зависимости от разных параметров вакансий (опыт работы, уровню квалификации, роли в компании и др.). В четвертой части будет представлена визуализация поляризации работников (вакансий) по уровню зарплат. В последнем разделе будет представлена попытка оценки уровня зарплаты от навыков, указываемых в вакансиях.
Сравнение структуры рынка труда Москвы и остальной России
Предположение о том, что с развитием технологий доля профессий, связанных с творческим и умственным трудом, будет расти можно проверить, сравнив структуру рынка вакансий в Москвой и остальной России. При этом будем опираться на следующие предположения.
Основное предположение, позволяющее сделать сравнение, состоит в том, что в столице технологии появляются раньше и распространяются быстрее, по сравнению с остальной Россией. В Москве сильнее развиты институты по созданию, тестированию, адаптации и распространению новых технологий - они обеспечиваются такими элементами как: ведущие университеты (и научные организации), штаб-квартиры крупнейших компаний, цифровая инфраструктура города, квалифицированный человеческий капитал. Распространение технологий далее идет от столицы к остальным регионам. Исходя из этого предположения можно рассматривать Москву и остальную Россию как условные временные периоды «до» и «после».
В таблице 1 представлены результат расчетов. В первой колонке указано количество вакансий по Москве для каждой профессиональной роли. Во второй колонке указана доля профессиональной роли от общего количества вакансий в Москве. Такой же подход был использован для заполнений колонок для России и России без Москвы.
Исходя из данных таблицы можно сделать несколько выводов. Первый заключается в том, что наибольший спрос по всей РФ (и Москве) имеет место на специалистов по продажам, врачей, поваров, курьеров, водителей. С точки зрения характеристик труда, это сфер услуг с высокой долей неопределенности в задачах, а также низкоквалифицированный труд.
Таблица 1. Топ 20 профессиональных ролей по количеству вакансий в Москве и РФ.
|
Профессиональная
роль |
Москва
|
Россия
|
Россия без Москвы
| |||
|
Количество вакансий
|
Доля по столбцу
|
Количество вакансий
|
Доля по столбцу
|
Количество вакансий
|
Доля по столбцу
| |
|
Другое
|
22 821
|
10,83%
|
149 345
|
12,07%
|
126 524
|
12,32%
|
|
Менеджер по продажам, менеджер по работе с
клиентами
|
20 373
|
9,67%
|
112 531
|
9,09%
|
92 158
|
8,98%
|
|
Продавец-консультант, продавец-кассир
|
16 284
|
7,73%
|
103 319
|
8,35%
|
87 035
|
8,48%
|
|
Водитель
|
5 690
|
2,70%
|
62 068
|
5,02%
|
56 378
|
5,49%
|
|
Бухгалтер
|
6 520
|
3,09%
|
37 959
|
3,07%
|
31 439
|
3,06%
|
|
Врач
|
3 948
|
1,87%
|
34 699
|
2,80%
|
30 751
|
3,00%
|
|
Оператор call-центра, специалист
контактного центра
|
1 750
|
0,83%
|
32 418
|
2,62%
|
30 668
|
2,99%
|
|
Повар, пекарь, кондитер
|
4 629
|
2,20%
|
32 353
|
2,61%
|
27 724
|
2,70%
|
|
Инженер-конструктор, инженер-проектировщик
|
5 303
|
2,52%
|
28 066
|
2,27%
|
22 763
|
2,22%
|
|
Программист, разработчик
|
10 093
|
4,79%
|
25 362
|
2,05%
|
15 269
|
1,49%
|
|
Кладовщик
|
3 603
|
1,71%
|
24 612
|
1,99%
|
21 009
|
2,05%
|
|
Разнорабочий
|
1 434
|
0,68%
|
21 774
|
1,76%
|
20 340
|
1,98%
|
|
Слесарь, сантехник
|
1 643
|
0,78%
|
21 673
|
1,75%
|
20 030
|
1,95%
|
|
Администратор
|
4 826
|
2,29%
|
21 551
|
1,74%
|
16 725
|
1,63%
|
|
Курьер
|
3 203
|
1,52%
|
20 614
|
1,67%
|
17 411
|
1,70%
|
Второй вывод, что в Москве больше всего нерутинных, творческих, аналитических профессий: у них наибольший вес как внутри Москвы, так и в общем зачете по России.
Сегментация имеющихся вакансий по: роли в компании, уровню квалификации, по квадрантам творческий-рутинный-умственный-ручной
Второй группой сигналов об изменениях рынка труда могут стать данные о зарплатах. Согласно гипотезе техно-скептиков (появление и развитие новых рабочих мест) новые технологии будут приводить к росту спроса на специалистов, которые их используют, что должно отражаться на росте зарплат этих профессионалов. Рассматривая данные сервисов по поиску работы были получены оценки предлагаемых работодателями зарплат.Для данного и последующих разделов данные необходимо было дополнительно обработать. В результате из 164 тыс. вакансий на HeadHunter за декабрь 2023 и январь 2024 были отобраны только вакансии, которые соответствуют следующим критериям:
1) Имеют полную занятость
2) Отмечены как полный день
3) Указана зарплата больше МРОТ
После применения критериев было получено 70 тыс. вакансий. Сильное различие между исходным и итоговым набором данных объясняется несколькими проблемами с данными:
a) Ошибки в базе данных (например, зарплата 7 руб. в месяц)
b) Неверное описание вакансии работодателем (зарплата указывается за смену, а вакансия отмечается как полная занятость и полный день (а не сменная занятость)
c) Во многих вакансиях зарплата не указывается
Эти вакансии неравномерно распределены между 174 профессиональными ролями, которые выделяет HeadHunter. Вакансии были сгруппированы по профессиональной роли, категории опыта, занятости. Для каждой такой группы была найдена средняя зарплата и количество вакансий в группе. Далее внутри каждой профессиональной роли была рассчитана доля каждого сегмента по количеству вакансий. Разное требование по опыту влияет на зарплату в вакансии.
Поскольку нам важно получить среднюю оценку влияния технологий на зарплату, нам не так важно, в каком именно сегменте опыта это происходит. Поэтому для каждой роли нужно найти усредненную взвешенную зарплату. После этого для каждой профессиональной роли была проведена ручная разметка дополнительных сегментов: роль в компании, относится ли вакансия к ИТ, уровень требуемой квалификации. Основным критерием определения вакансии к определенному сегменту - экспертная оценка.
Следует пояснить, что каждую группу вакансий, определяемых колонками «сектор ИТ» и «Роль в компании», можно представить в виде распределений зарплат: по каждому из этих распределений можно рассчитать среднее, минимальное и максимальное значения, что и было сделано (см. таблицу 2).
Таким образом, 174 профессиональные роли можно сгруппировать в несколько сегменты, что упрощает анализ имеющихся данных.
Таблица 2. Описательная статистика по сегментам
|
сектор ИТ
|
Роль в компании
|
Кол-во
вакансий |
Средняя
зарплата |
Минимальная
Средняя Зарплата |
Максимальная
Средняя Зарплата |
|
1
|
Специалист
|
4 342
|
155 957
|
103 219
|
215 147
|
|
Руководители
|
168
|
242 555
|
239 385
|
245 725
| |
|
Топ-менеджмент
|
112
|
278 325
|
278 325
|
278 325
| |
|
Всего
|
4 622
|
175 661
|
103 219
|
278 325
| |
|
0
|
Специалист
|
67 215
|
100 394
|
61 915
|
176 306
|
|
Работник
|
28 348
|
81 457
|
55 676
|
120 061
| |
|
Менеджер
|
14 117
|
104 849
|
67 642
|
151 793
| |
|
Продажи
|
10 313
|
161 163
|
92 189
|
280 744
| |
|
Руководители
|
7 822
|
153 235
|
85 921
|
265 398
| |
|
Не указано
|
1 387
|
96 627
|
96 627
|
96 627
| |
|
Топ-менеджмент
|
1 285
|
289 368
|
193 085
|
413 162
| |
|
Всего
|
130 487
|
116 990
|
55 676
|
413 162
| |
|
Итого
|
135 109
|
122 077
|
55 676
|
413 162
|
Подробнее по расчетным колонкам таблицы:
В колонке «Средняя зарплата» рассчитана среднее значение по средневзвешенным зарплатам профессиональных ролей.
В колонке «Минимальная Средняя зарплата» и «Максимальная Средняя зарплата» рассчитаны минимальное и максимальное значение по средневзвешенным зарплатам профессиональных ролей.
Из таблицы следует, что (1) занятые в ИТ профессиях в среднем зарабатывают больше, чем в не ИТ профессиях, за исключением топ-менеджеров. Следует отметить, что в какой-то определенной не ИТ роли (или для какой-то конкретной вакансии) зарплата может быть выше - здесь сравниваются 2 бинарные категории: ИТ и не ИТ.
Также следует, что за хороших специалистов роли «продаж» компании готовы платить большие зарплаты, сопоставимые с зарплатами работников ИТ (то же для сегментов руководителей и топ-менеджеров). Об этом можно косвенно судить исходя из разницы между максимальной и минимальной зарплаты работников продаж и специалистов ИТ. Эта разница почти в 2 раза меньше для ИТ специалистов, чем для продаж; что сигнализирует о большем уровне риска (неустойчивости) в продажах
Визуализация поляризации работников по зарплатам
Третий тип сигналов, который был получен в результате анализа данных сервиса по поиску работы - косвенная оценка поляризации работников по уровню дохода. Согласно гипотезев среднесрочном периоде технологии будут приводить к поляризации работников по уровню квалификации (уровню освоения технологий), что должно будет отражаться в поляризации зарплат.Определение перцентилей зарплат. Вакансии были отсортированы от наименьшего к наибольшему перцентилю по уровню зарплаты. По каждой вакансии было определено к какому сегменту перцентиля она относится: для этого использовали децили от 0 до 90%, и далее отдельные перцентили для 95%, 97%, 99%. Далее была найдена средняя зарплата для каждого из сегментов перцентилей - визуализация представлена на рис. 1.
Рисунок 1. Средняя зарплата по перцентилям зарплат
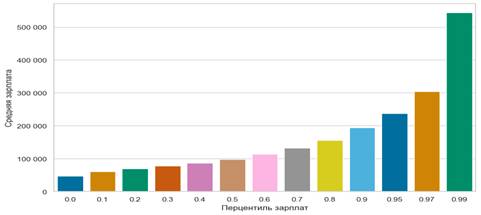
Источник: Данные HeadHunter, авторские расчеты
Видим, что средняя зарплата крайних правых перцентилей намного выше, чем средняя зарплата крайних левых.
Примечательно, что темп прироста зарплат относительно стабилен до 80 перцентиля. После этого переход в более дальние сегменты сопровождается более резким ростом зарплаты.
Далее были рассмотрены распределение вакансий (их количества) по перцентилям зарплат: для каждого перцентиля (сегмента) было посчитано количество вакансий в нем. Визуализация представлена на рис. 2.
Наблюдаем довольно специфичную поляризацию. Видим, что распределение вакансий по перцентилям зарплат равномерно для 80% вакансий - до 80 перцентиля спрос (количество вакансий) в сегментах сопоставим. Однако, начиная с 90 и выше - количество вакансий резко сокращается. Анализируя распределение вакансий вместе со средними зарплатами по перцентилям, можно сказать, что при сохранении такой динамики будет увеличиваться финансовый разрыв между вакансиями в сегментах до 90 перцентиля и сегментах после.
Рисунок 2. Распределение вакансий по перцентилям зарплат
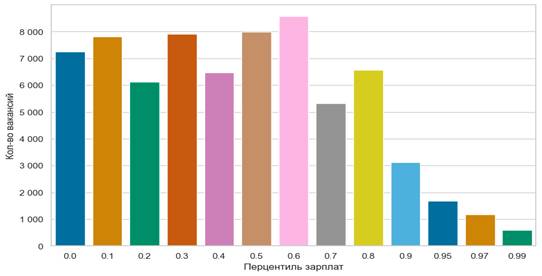
Источник: Данные HeadHunter, авторские расчеты
Скорее всего, это уже происходило и происходит некоторое продолжительное время. Это должно проявляться в том, что у последнего дециля объем сбережений (располагаемых средств) будет больше. Следующим шагом нужно определить, могут ли являться технологии ключевым фактором такого разделения.
Попытка оценки влияния требуемых технологических компетенций вакансии и на зарплату
Четвертый и важнейший тип данных, который можно получить из сервисов по поиску работы, является соответствие зарплат и требуемых технологий. С помощью этого можно проверить гипотезы о влиянии технологий на спрос на труд: увеличивают ли они зарплаты работников, происходит ли поляризация по технологическим навыкам, происходит ли замещение низко-технологичных работ, увеличивается ли количество технологических вакансий.Однако эти данные представлены в неструктурной текстовой форме сложной для обработки и анализа. Для решения этой проблемы было использовано подключение к сервисам больших языковых моделей (LLM-модели, например ChatGPT).
Из базы данных HeadHunter было получено полное описание вакансии - что заполняют работодатели в требованиях. Это выглядит в форме неструктурированного текста: невозможно применить алгоритм, который бы позволил достать из описаний тысяч вакансий: навыки, программы и названия технологий.
Далее сервису ChatGPT по каждой вакансии передается текстовое описание вакансии, из которой нужно достать описание технологий. В рамках этой задачи было сделано несколько итераций по формулированию задачи для ChatGPT - таким образом, чтобы получать стабильный постоянный результат, отправляя этой программе десятки тысяч описаний вакансий. Финальный текстовый запрос:
"Извлеките элементы технологического стека, упомянутые в описании вакансии. Технология указывает на то, что вам необходимо программное обеспечение для выполнения этой задачи. (пример: 'Excel;SQL;1С - НЕ ВКЛЮЧАЙТЕ ПРИМЕР В ВЫВОД!). Исключите "мягкие" навыки. Используйте ';' в качестве разделителя между элементами, которые вы извлекаете. Обеспечьте лаконичный вывод в пределах 150 лексем. Верните текст, содержащий навыки".
В качестве описаний вакансий использовались вакансии, в которых (1) указана профессиональная роль «Аналитик», (2) указывается зарплата, (3) подразумевается полная занятость полный день.
В результате для каждой вакансии был получен список программ и технологий, которые запрашиваются в работе. Пример результата алгоритма представлен ниже.
Рисунок 3. Результат работы алгоритма по одной из вакансий

Источник: результат обработки авторского скрипта
По изображению видно, что даже несмотря на указания в текстовом запросе, алгоритм все равно выдал элементы, которые не относятся к технологиям и программам: прогнозирование, оптимизация, анализ кода. Поэтому, после получения списков программ от ChatGPT (из всех вакансий), все элементы были вручную размечены по следующим категориям: language (иностранные языки), domain_knowledge (сюда были отнесены специфические акронимы типа МСФО, LTV, ARPU - это не технологии, но частые акронимы, подразумевающие использование технологий и методик из финансов и менеджмента), business_architecture (всё, что связано с проектированием бизнес-процессов), office_program (такие как MS Office), special_software (например, 1-С), coding (языки программирования), visualization (инструменты визуализации такие как Tableau), other (всё остальное, шум от ChatGPT), experience_cat (этот параметр был получен из HeadHunter)
В результате по каждой из вакансий была получена бинарная оценка категорий навыков: есть (1) или нет (0) категории навыка в описании вакансии. Такая структура данных позволила применить линейную регрессию для оценки влияния параметров (категорий) на среднюю зарплату: полученные коэффициенты представлены на рис. 4.
Видим, что средняя зарплата по выборке составляет 40 000 рублей. Наибольший вклад в увеличение зарплаты в данном наборе данных вносят: параметр business_architecture (напомним, что это компетенции, связанные с проектированием бизнес-процессов) и параметр «опыт работы».
После применения линейной регрессии получили следующую сводную таблицу по результатам.
Таблица 3. Результаты применения линейной регрессии
|
Переменная
|
Коэффициент
|
Стандартная ошибка
|
t-значение
|
P>t
|
|
const
|
40 270
|
16 000
|
2,51
|
0,01
|
|
language
|
-5 161
|
19 500
|
-0,27
|
0,79
|
|
domain_knowledge
|
1 093 751
|
11 600
|
0,42
|
0,67
|
|
other
|
-8 269
|
7 961
|
-1,04
|
0,30
|
|
business_architecture
|
38 900
|
9 487
|
4,10
|
0,00
|
|
office_program
|
-37 080
|
7 545
|
-4,91
|
0,00
|
|
special_software
|
2 322
|
7 552
|
0,31
|
0,76
|
|
coding
|
10 150
|
7 247
|
1,40
|
0,16
|
|
visualization
|
-7 037
|
9 303
|
-0,76
|
0,45
|
|
experience_cat
|
50 740
|
5 363
|
9,46
|
0,00
|
Показатель Adjusted R-squared показал, что модель объясняет 47.5% вариации в данных. Также видим, что 6 параметров показывают p-value выше распространенного порога в 0.05, т.е. не являются значимыми. Следующим шагом убираем из модели линейной регрессии параметры, которые не достигли статистически значимого результата. После этого обновляем расчеты.
Таблица 4. Уменьшенная модель линейной регрессии
|
Переменная
|
Коэффициент
|
Стандартная
ошибка |
t-value
|
P>t
|
|
const
|
36 230
|
13 900
|
2,61
|
0,01
|
|
business_architecture
|
40 910
|
9 189
|
4,45
|
0,00
|
|
office_program
|
-34 910
|
7 087
|
-4,93
|
0,00
|
|
experience_cat
|
51 100
|
5 311
|
9,62
|
0,00
|
В результате в финальной модели у нас остается 3 наиболее важных фактора, влияющих на величину заработной платы вакансий из категории аналитик: (1) требования к знанию программ по проектированию бизнес-процессов, (2) требования к знанию офисных программ (Excel), (3) требования к опыту работы. На изображении 6 представлены коэффициенты полученной модели.
Согласно этой модели средняя зарплата без влияния 3 указанных выше факторов равна 36 тыс. руб. Знание программ по проектированию бизнес процессов увеличивает зарплату на 41 тыс. руб., увеличение категории опыта (нет опыта, 1-3 лет, 3-6 лет, более 6 лет) увеличивает зарплату на 51 тыс. руб. за каждый следующий уровень; а знание офисных программ уменьшает зарплату на 34 тыс. руб..
Последнее утверждение может показаться странным, однако если посмотреть на распределение зарплат в зависимости от наличия требований знания офисных программ можно заметить, что в вакансиях с более высокими зарплатами не прописывается требование знания офисных программ.
Рисунок 4. Распределение зарплат в зависимости от наличия требования к знанию Офисных программ в описании вакансии
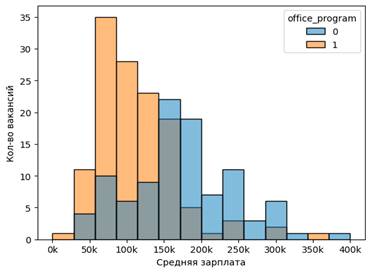
Источник: авторские расчеты
И это характерно для вакансий, где требуется больший объем опыта.
Рисунок 5. Распределение зарплат в зависимости по требованиям знания Офисных программ и сегмента опыта в описании вакансии
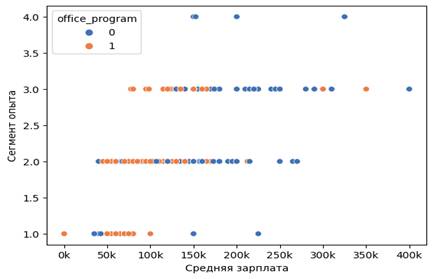
Источник: авторские расчеты
Если же взять случайную вакансию, где не указываются офисные программы, но предлагается высокая зарплата, то можно увидеть, что знание офисных программ подразумевается, хотя и не указывается прямым текстом. Например, текст с требованиями по вакансии Маркетолог-аналитик c предлагаемой зарплатой в 150 тыс. руб. выглядит следующим образом:
«...проведение сплит-тестирования писем, анализ их эффективности. Анализ эффективности рекламных кампаний и качества трафика. Оперативная "работа над ошибками" на основе проведенного анализа. Изучение и анализ рынка (спрос, конкуренты, общая конъюнктура интернет-рынка в данной нише) ... Для нас важно: Умение генерировать целевой поток лидов Знание UNIT-экономики и умение ее просчитывать»
Из описания вакансии следует, что отчетность и расчет unit-экономики будет производиться именно в Excel (или любом другом сервисе электронных таблиц), что является офисной программой. После проверки ряда случайных вакансий, была выявлена та же проблема.
Таким образом, выявили еще один недостаток или усложнение, связанные с текстовыми данными: работодатели указывают не все используемые технологии и программы в работе, а критически необходимые; такие требования, как офисные программы, особенно для позиций с высокими требованиями по опыту, подразумеваются в описании вакансии, но напрямую не указываются.
Заключение
По результатам проделанной работы в рамках текущих данных можно сделать несколько выводов, которые применимы к сервису поиска вакансий HeadHunter:
1) в Москве больше всего нерутинных, творческих, аналитических профессий: у них наибольший вес как внутри Москвы, так и в сумме по России.
2) Наибольший спрос по всей РФ (и Москве) на специалистов по продажам, врачам, поварам, курьерам, водителям - сфера услуг с высокой долей неопределенности в задачах и низкая, как правило, квалификация.
3) Занятые в ИТ профессиях в среднем зарабатывают больше, чем в не ИТ профессиях, за исключением топ-менеджеров. Отметим, что в какой-то определенной не ИТ роли зарплата может быть выше - здесь сравниваются 2 бинарные категории: ИТ и не ИТ.
4) За хороших специалистов по продажам компании готовы платить большие зарплаты, сопоставимые с зарплатами работников ИТ (то же для сегментов руководителей и топ-менеджеров). Об этом можно косвенно судить исходя из разницы между максимальной и минимальной зарплатами работников продаж и специалистов ИТ. Эта разница почти в 2 раза меньше для ИТ специалистов, чем для продаж, что сигнализирует о большем уровне риска (неустойчивости) в продажах.
5) Наблюдается поляризацию работников по уровню зарплат. Распределение вакансий по перцентилям зарплат равномерно для 80% вакансий - до 80 перцентиля спрос (количество вакансий) в сегментах сопоставим. Однако, начиная с 90 и выше - количество вакансий резко сокращается, а средняя зарплата резко растет.
6) Наиболее сильными факторами, определяющими размер зарплаты в профессиональной роли «Аналитик» (по критериям HeadHunter) - опыт работы и знание программ, связанных с проектированием бизнес-процессов.
Также можно сделать вывод по возможностям досок объявлений для оценки влияния технологий на спрос на труд. Напомним исходное предположение по возможностям анализа досок объявлений: спрос на труд на досках объявлений будет проявляться в вилке зарплат, количестве вакансий по разным отраслям/профессиональным ролям.
По результатам работы видим, что предположение подтвердилось. Более структурно, аналитическую пользу от досок объявлений можно сформулировать следующим образом:
- Позволяют оценить распределение вакансий разных категорий между развитыми и догоняющими регионами в конкретный момент времени; таким образом, можно косвенно оценивать степень технологизации экономики между регионами; а также косвенно проверять аргумент о перетоке трудовых ресурсов в менее технологически развитые регионы.
- Для вакансий с указанными зарплатами позволяет оценивать поляризацию рынка труда (сторона спроса) по уровню зарплат, по уровню квалификации, принадлежности к ИТ сфере, и по другим срезам. Стоит заметить, что срезы: их критерии, разметка - должна быть проведена вручную.
- Для вакансий с указанными зарплатами, по которым получается получить описания требований, можно вычленять дополнительные параметры с помощью алгоритмов LLM (Chat GPT). Эти параметры (в дополнение к имеющимся) позволяют применять регрессионные модели с большим количеством параметров, оценивая важность этих параметров в размер зарплаты. Однако при этом необходимо учитывать стоимость применения сервиса (Chat GPT).
Основной проблемой остается качество данных в базе данных HeadHunter:
а) Сегментация вакансий по профессиональным ролям, скорее всего, работает не корректно: в группу аналитиков помещаются, как обычные сотрудники аналитики, так и руководители аналитики (что еще уместно), а также бизнес-архитекторы, которых уместнее выделить в отдельный сегмент.
б) В указании зарплат могут быть допущены ошибки (которые зачастую даже не совпадают с отображением на сайте)
в) Работодатели указывают не полные требования к вакансии. Несмотря на то, что это не является проблемой работы самого HeadHunter, это тоже влияет на данные и результаты анализа
г) Ограничения HeadHunter по выгрузке данных: невозможно выгрузить более определенного количества строк за один запрос. Выгрузка случайных вакансий так же невозможна
Источники:
2. Капелюшников Р. Влияние четвертой промышленной революции на рынок труда // Аист на крыше. Демографический журнал. – 2018. – № 6(6). – c. 32-36.
3. Устюжанина Е.В., Сигарев А.В., Шеин Р.А. Цифровая экономика как новая парадигма экономического развития // Национальные интересы: приоритеты и безопасность. – 2017. – № 10. – c. 1788-1804. – doi: 10.24891/ni.13.10.1788.
4. Acemoglu D., Restrepo P. Robots and Jobs: Evidence from US Labor Markets // NBER Working Paper 23285. – 2017. – doi: 10.3386/w23285.
5. Acemoglu Daron, Pascual Restrepo Automation and New Tasks: How Technology Displaces and Reinstates Labor // Journal of Economic Perspectives. – 2019. – № 2. – p. 3-30. – doi: 10.1257/jep.33.2.3.
6. Arntz Melanie, Gregory Terry, Zierahn Ulrich Revisiting the Risk of Automation // Economics Letters. – 2017. – p. 157-160. – doi: 10.1016/j.econlet.2017.07.001.
7. David H. Autor, David Dorn The Growth of Low-Skill Service Jobs and the Polarization of the US Labor Marke // The American Economic Review. – 2013. – № 5. – p. 1553-1597. – doi: 10.1257/aer.103.5.1553.
8. Dauth Wolfgang, Findeisen Sebastian, Jens Suedekum, Nicole Woessner German Robots - The Impact of Industrial Robots on Workers. C.E.P.R. Discussion Papers. [Электронный ресурс]. URL: https://doku.iab.de/discussionpapers/2017/dp3017.pdf.
9. Dillender Marcus O., Eliza C. Forsythe Computerization of White Collar Jobs // Upjohn Institute Working Paper. – 2019. – doi: 10.17848/wp19-310.
10. Frey Carl Benedikt, Osborne Michael A. The future of employment: How susceptible are jobs to computerisation? // Technological Forecasting and Social Change, Elsevier. – 2017. – p. 254-280. – doi: 10.1016/j.techfore.2016.08.019.
11. Georg Graetz, Guy Michaels Robots at Work // The Review of Economics and Statistics. – 2018. – № 5. – p. 753-768. – doi: 10.1162/rest_a_00754.
12. James Bessen Automation and Jobs: When Technology Boosts Employment // Economic Policy. – 2019. – № 100. – p. 589-626. – doi: 10.1093/epolic/eiaa001.
13. Marinoudi V., Lampridi M., Kateris D., Pearson S., Sørensen C.G., Bochtis D. The Future of Agricultural Jobs in View of Robotization // Sustainability. – 2021. – № 13. – p. 12109. – doi: 10.3390/su132112109.
14. Martens B., Tolan S. Will This Time Be Different? A Review of the Literature on the Impact of Artificial Intelligence on Employment, Incomes and Growth // JRC Digital Economy Working Paper. – 2018. – doi: 10.2139/ssrn.3290708.
Страница обновлена: 25.07.2026 в 15:00:42
Download PDF | Downloads: 25
Application of online job search services to the assessment of the impact of technology on labor demand
Rudakov I.O.Journal paper
Creative Economy
Volume 18, Number 8 (August 2024)
Abstract:
The impact of modern technologies on the demand for labor is often debated in the academic literature. Some researchers believe that digital technologies will lead to the replacement of employees by robotic systems and reduce employment; others believe that new technologies will lead to an increase in the demand for employees who can use these technologies. One of the means of substantiating or disproving these assertions is to examine publicly available information from online job search services.
In the article, information on vacancies from the free database of the job search service HeadHunter was processed and analyzed. On the basis of the analysis the difference in demand for creative and intellectual professions by vacancies between Moscow and the rest of Russia was revealed; the employee polarization by wage level was recorded. An attempt to assess the impact of different skills in the job description on the wage corresponding to this vacancy was made.
The analysis corroborates the assertions of techno-skeptics, indicating that the advent of new technologies has led to an increased demand for specialists who possess these technologies, and consequently, an augmented remuneration for such professionals.
The article will be of interest to researchers of the impact of technology on work.
The research was funded by the Russian Science Foundation, grant No. 23-28-00358 "Institutional and structural conditions for adaptation to shocks of economic development".
Keywords: assessing the impact of technology on labor demand, impact of skills on wages, employee wage polarization, labor demand, internet job search services
Funding:
References:
Acemoglu D., Restrepo P. (2017). Robots and Jobs: Evidence from US Labor Markets NBER Working Paper 23285. doi: 10.3386/w23285 .
Acemoglu Daron, Pascual Restrepo (2019). Automation and New Tasks: How Technology Displaces and Reinstates Labor Journal of Economic Perspectives. 33 (2). 3-30. doi: 10.1257/jep.33.2.3.
Arntz Melanie, Gregory Terry, Zierahn Ulrich (2017). Revisiting the Risk of Automation Economics Letters. 159 157-160. doi: 10.1016/j.econlet.2017.07.001.
Dauth Wolfgang, Findeisen Sebastian, Jens Suedekum, Nicole Woessner German Robots - The Impact of Industrial Robots on WorkersC.E.P.R. Discussion Papers. Retrieved from https://doku.iab.de/discussionpapers/2017/dp3017.pdf
David H. Autor, David Dorn (2013). The Growth of Low-Skill Service Jobs and the Polarization of the US Labor Marke The American Economic Review. 103 (5). 1553-1597. doi: 10.1257/aer.103.5.1553.
Dillender Marcus O., Eliza C. Forsythe (2019). Computerization of White Collar Jobs Upjohn Institute Working Paper. doi: 10.17848/wp19-310.
Frey Carl Benedikt, Osborne Michael A. (2017). The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change, Elsevier. 114 254-280. doi: 10.1016/j.techfore.2016.08.019.
Georg Graetz, Guy Michaels (2018). Robots at Work The Review of Economics and Statistics. 100 (5). 753-768. doi: 10.1162/rest_a_00754.
Gimpelson V.E., Zudina A.A., Kapelyushnikov R.I., Lukyanova A.L. i dr. (2017). Rossiyskiy rynok truda: tendentsii, instituty, strukturnye izmeneniya [The Russian labor market: trends, institutions, structural changes] M.: Tsentr strategicheskikh razrabotok. (in Russian).
James Bessen (2019). Automation and Jobs: When Technology Boosts Employment Economic Policy. 34 (100). 589-626. doi: 10.1093/epolic/eiaa001.
Kapelyushnikov R. (2018). Vliyanie chetvertoy promyshlennoy revolyutsii na rynok truda [The impact of the Fourth Industrial Revolution on the labor market]. Aist na kryshe. Demograficheskiy zhurnal. (6(6)). 32-36. (in Russian).
Marinoudi V., Lampridi M., Kateris D., Pearson S., Sørensen C.G., Bochtis D. (2021). The Future of Agricultural Jobs in View of Robotization Sustainability. (13). 12109. doi: 10.3390/su132112109.
Martens B., Tolan S. (2018). Will This Time Be Different? A Review of the Literature on the Impact of Artificial Intelligence on Employment, Incomes and Growth JRC Digital Economy Working Paper. doi: 10.2139/ssrn.3290708.
Ustyuzhanina E.V., Sigarev A.V., Shein R.A. (2017). Tsifrovaya ekonomika kak novaya paradigma ekonomicheskogo razvitiya [Digital economy as a new paradigm of economic development]. National interests: priorities and security. 13 (10). 1788-1804. (in Russian). doi: 10.24891/ni.13.10.1788.