Методы машинного обучения при оценке конкурентоспособности предприятия
Мартынова Ю.А.1
1 Санкт-Петербургский государственный университет аэрокосмического приборостроения, Россия, Санкт-Петербург
Скачать PDF | Загрузок: 78 | Цитирований: 3
Статья в журнале
Вопросы инновационной экономики (РИНЦ, ВАК)
опубликовать статью | оформить подписку
Том 10, Номер 1 (Январь-Март 2020)
Эта статья проиндексирована РИНЦ, см. https://elibrary.ru/item.asp?id=42676124
Цитирований: 3
Аннотация:
Приведены результаты классификации конкурентоспособности (КСП) предприятия с использованием методов машинного обучения. Выявлены факторы, от которых зависит КСП организации, и возможные классы КСП. При решении задачи классификации использовался модуль Classification Learner, входящий в состав программного продукта MatLab 2018b. В качестве обучающей выборки, необходимой в машинном обучении для вывода модели, применялась \\\"игрушечная\\\" база данных (Toy Dataset), которая формировалась методом Монте-Карло. Решение задачи показало, что лучшим методом при классификации КСП предприятия является алгоритм k-ближайших соседей (k-nearest neighbors – k-NN), обладающий наибольшей точностью. Кроме того, эта же задача была решена с помощью многослойной нейронной сети
Ключевые слова: машинное обучение, конкурентоспособность предприятия, модели классификации, нейронная сеть
JEL-классификация: С45, С65, D81
1. Введение
Анализ и исследование понятия «конкурентоспособность» приводят к выводу, что пока еще не сложилось общепринятого определения этого термина. Любой аналитик обращает внимание на разные аспекты конкуренции, рассматривает различные трактования данного понятия. Все это приводит к наличию многообразных определений одного и того же понятия. В целом конкурентоспособность (КСП) понимают, прежде всего, как способность конкурировать, удерживать позиции на рынке, как свойство субъектов и результатов конкурентных отношений [1] (Zhdanova, 2015). Оценивая КСП на уровне стран, отраслей, предприятий, продукции, следует учесть, что страны, отрасли, товары не конкурируют сами по себе, в основе лежит деятельность предприятий с их экономическими интересами.
В отношении КСП различных стран уже выработалась определенная точка зрения. Индекс глобальной конкурентоспособности (Global Competitiveness Index) – это глобальное исследование и сопровождающий его рейтинг стран мира по показателю экономической КСП, который рассчитывается по методике Всемирного экономического форума (World Economic Forum) [2]. Этот подход основан на комбинации статистических данных и результатов опроса руководителей крупнейших мировых компаний. Подобное исследование проводится с 2004 года и на данный момент представляет наиболее полный комплекс показателей КСП по различным странам мира. Индекс интегрирует хорошо зарекомендовавшие себя аспекты с новыми и возникающими рычагами, которые стимулируют производительность и рост. В нем подчеркивается роль человеческого капитала, инноваций, устойчивости и гибкости, которые являются не только движущими силами, но и определяющими чертами экономического успеха в мире.
Индекс глобальной конкурентоспособности составлен из большого числа переменных, которые детально характеризуют КСП стран мира, находящихся на разных уровнях экономического развития. Все переменные объединены в 12 контрольных показателей, определяющих национальную КСП, в том числе качество институтов, инфраструктуру, макроэкономическую стабильность, здоровье и образование, эффективность рынка товаров и услуг и т.д.
Совсем иначе обстоит дело с КСП предприятий. Большое количество определений этого термина КСП, разъяснений его сущности не позволяют однозначно выявить факторы, которые оказывают наибольшее влияние на КСП. Например, среди факторов КСП, контролируемых организацией, укажем следующие [3]: уровень качества продукции; предпродажное и послепродажное обслуживание, наличие сервисных центров; квалификация персонала компании; имидж компании и т.п. Наличие значительного числа публикаций в области КСП предприятий все же не позволяет придти к однозначному выводу о факторах и типах КСП, методах классификации КСП [4-6] (Zelga, 2017; Shpak, Seliuchenko, Kharchuk, 2019). Из изложенного следует цель настоящей работы, заключающаяся в применении методов машинного обучения к классификации КСП предприятий.
Далее работа структурирована следующим образом: вначале дается краткое описание принципов машинного обучения и методов, пригодных для решения поставленной задачи; затем анализируются полученные результаты для классификации КСП; в итоге указываются пути дальнейших работ.
2. Методология
Машинное обучение и его инструменты
Машинное обучение (МО) представляет собой метод моделирования, который включает данные [7, 8]. Это определение может показаться слишком кратким, но, по существу, МО – это метод, который определяет модель из данных. Здесь под данными подразумевается такая информация, как документы, аудио, изображения и т.д. Модель является конечным продуктом МО.
Машинное обучение использует теорию статистики при построении математических моделей, потому что основной задачей является формирование вывода из выборки данных. Роль компьютерных наук двойственная. Во-первых, в обучении нужны эффективные алгоритмы для решения задачи оптимизации, а также для хранения и обработки огромного количества данных, которые обычно имеются. Во-вторых, как только модель изучена, ее представление и алгоритмическое решение для вывода также должны быть эффективными. В некоторых приложениях эффективность алгоритма обучения или логического вывода, а именно его пространственная и временная сложность, может быть столь же важной, как и его точность прогнозирования.
Само название МО отражает тот факт, что описываемый метод анализирует данные, и он сам, а не человек, находит модель. Этот процесс называется «обучением», потому что он напоминает обучение с данными для поиска модели. Следовательно, данные, которые используются при МО, являются обучающими данными.
Алгоритм k-NN
Алгоритм k-ближайших соседей (k-nearest neighbors – k-NN) представляет собой контролируемый алгоритм МО, который используется для решения задач классификации. При выполнении этого метода предполагается, что подобные объекты располагаются рядом друг с другом. Алгоритм k-NN отражает идею сходства, иногда называемую расстоянием или близостью, и сводится к вычислению расстояния между точками на графике [9, 10] (Ezghazi, Zahi, Zekoua, 2017).
В этом методе входные данные состоят из k ближайших обучающих примеров в пространстве признаков. Выходные данные зависят от того, используется ли алгоритм k -NN для классификации или регрессии. При классификации выходные данные являются членами класса. Объект классифицируется множеством голосов его соседей, при этом объект присваивается классу, наиболее распространенному среди его k ближайших соседей (k является положительным целым числом, обычно небольшим). Если k = 1, то объект просто присваивается классу этого единственного ближайшего соседа.
На этапе классификации параметр k является определяемой пользователем константой, а неотмеченный вектор (точка запроса или контрольная точка) классифицируется путем назначения метки, которая наиболее часто встречается среди k обучающих выборок, ближайших к этой точке запроса. Обычно используемая метрика расстояния для непрерывных переменных – евклидово расстояние.
Для нового экземпляра прогнозы о принадлежности к классу делаются путем поиска во всем обучающем наборе k наиболее похожих экземпляров (соседей) и суммирования выходной переменной для этих k экземпляров.
Деревья решений
Деревья решений используются для предсказания размещения классов или объектов в категории по результатам измеряемых параметров [11, 12] (Azad, Moshkov, 2017; Kim, Hong, 2017). Обычно поиск решения – реализация методов для выполнения бинарной классификации путем расщепления ветвей дерева, основываясь на измеренных значениях предикторов. В таких деревьях листья представляют метки классов, а ветки представляют конъюнкции признаков, которые ведут в эти метки классов. Конечный узел содержит ответ. При классификации деревья дают ответы, которые являются номинальными, такими как «истина» или «ложь».
Деревья классификации широко используются при установлении диагноза пациента, формировании структуры данных, принятии решений. Графический вид результатов позволяет улучшить их интерпретацию. Цель формирования деревьев решений сводится к предсказанию значений зависимой переменной в функции от соответствующих значений одной или нескольких независимых переменных (предикторов).
Нейронные сети
Нейронная сеть – это «черный ящик», который отражает ситуацию с полностью неизвестным процессом, но в наличии есть наблюдения (примеры). Здесь известны входы и выход, но требуется база примеров, по которой обучается сеть. В общем случае НС представляет собой машину, моделирующую способ обработки мозгом конкретной задачи [13] (Haykin, 2009). Такая сеть реализуется с помощью электронных компонентов или моделируется программой, выполняемой на компьютере. Благодаря своим возможностям обучения и обобщения нейронные сети могут быть выражены как математическое отображение архитектуры мозга человека.
Поясним принцип нейросетевой технологии на однослойной сети с R входами и S нейронами в слое (рис. 1). В этой сети каждый элемент входного вектора р соединен с каждым входным нейроном через матрицу весов W. Нейрон с индексом i имеет сумматор, на который поступают взвешенные входы и смещения для формирования i-го скалярного выхода n(i). Различные n(i) объединяются вместе, образуя S-й элемент входного вектора n, которые являются аргументами функции активации f. В итоге на выходе сети формируется выходной вектор-столбец а.
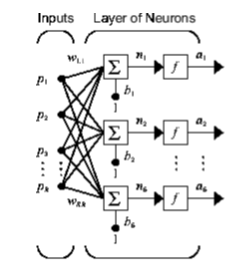
Рисунок 1. Однослойная сеть с R входными элементами
Источник: [14]
3. Результаты
В качестве факторов, влияющих на КСП предприятия, примем следующие:
1) качество выпускаемой продукции;
2) товарно-сбытовая деятельность предприятия;
3) организационно-техническое совершенство производства;
4) финансовое состояние;
5) имидж предприятия.
Такой набор факторов, по мнению автора, является достаточным для целей исследования, так как он охватывает основные аспекты КСП и не противоречит общепринятым тенденциям [3, 4] (Zelga, 2017).
Классы КСП организации установим такими [4] (Zelga, 2017):
1) нормальная (normal) – результаты конкретных взаимодействий совпадают с ожиданиями участвующих заинтересованных сторон;
2) ниже нормальной (less) – фактические результаты не соответствуют ожиданиям. Затем заинтересованные стороны, вовлеченные в эту ситуацию, предпримут действия, чтобы отказаться от взаимодействия с компанией и перейти к другой, более привлекательной;
3) выше нормальной (more) – фактические результаты выше, чем ожидалось. Заинтересованные стороны, у которых есть основания для таких оценок, стремятся укрепить свои отношения с компанией.
Для создания базы примеров, которая используется в МО при формировании модели, возможно использование двух подходов:
· применение реальных данных;
· использование «игрушечных» наборов данных.
В проводимом исследовании реальных данных еще нет, поэтому обратимся ко второму приему. В МО важно научиться правильно применять игрушечные наборы данных [15, 16] (Ramsundar, Zade, 2019; Shakla, 2019), так как обучение алгоритма на реальных данных сопряжено с трудностями и может закончиться неудачей. Игрушечные наборы данных играют решающую роль для понимания работы алгоритмов. При наличии простой синтетической выборки данных достаточно просто оценить, обучился алгоритм нужному правилу или нет. На реальных данных получить такую оценку сложно. Здесь воспользуемся методом Монте-Карло для формирования синтетической выборки данных. При розыгрыше примем для каждого фактора диапазон от 0 до 10 баллов с учетом классов и дополним результаты моделирования случайным шумом. Каждый разыгранный класс имеет по 10 строк, и вся таблица представляет собой матрицу размером 30*5. Фрагмент разыгранных данных показан в таблице 1.
Таблица 1
Фрагмент разыгранных данных
|
Х1
|
Х2
|
Х3
|
Х4
|
Х5
|
Класс
|
|
2,8
|
2,9
|
0,4
|
2,3
|
2,5
|
Less
|
|
3,0
|
1,0
|
3,9
|
3,7
|
3,7
|
Less
|
|
4,5
|
1,4
|
0,9
|
0,8
|
3,6
|
Less
|
|
3,8
|
0,7
|
1,9
|
3,2
|
0,8
|
Less
|
|
2,2
|
1,4
|
4,5
|
3,3
|
1,0
|
Less
|
На рисунке 2 в плоскости первых двух переменных (качество продукции и товарно-сбытовая деятельность) представлены все 30 смоделированных объектов, каждый из которых характеризуется определенной величиной КСП.
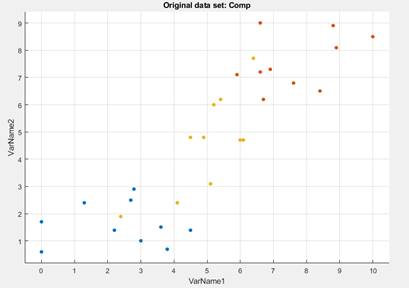
Рисунок 2. Исходные данные
Источник: получено автором.
Далее на основе такой таблицы необходимо проанализировать различные методы классификации и выбрать тот из них, который покажет лучшую точность. Для решения этой задачи воспользуемся программным продуктом MatLab 2018b. В этой версии программы имеется специальный модуль Classification Learner, открывающий более широкие возможности построения классификаторов по сравнению с более ранними версиями. Этот модуль может работать в ручном режиме (manual), когда поочередно проверяется тот или иной метод, и автоматическом (automated), когда программа просматривает все возможные решения для данной задачи и указывает лучшие результаты. Напомним, что методы МО на основе имеющихся данных формируют модель, которая может использоваться для классификации новых наблюдений. Здесь применим автоматический режим, в котором выберем опцию All Quick-To-Train. Эта опция для нашего набора данных обучит все те модели, которые являются наиболее быстрыми.
Результаты этой процедуры показаны на рисунке 3, где среди 9 проанализированных методов наивысшую точность продемонстрировал метод № 1.5 (medium k-NN).
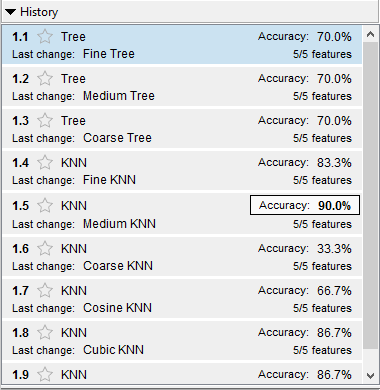
Рисунок 3. Результаты подбора модели
Источник: получено автором.
Приведем результаты для выбранного программой метода. На рисунке 4 представлена матрица ошибок для метода k-NN . Строками матрицы ошибок являются истинные классы, столбцами – предсказанные. Диагональные элементы показывают, где истинный и предсказанный классы совпадают. Сумма всех чисел в ячейках матрицы составляет 30, т.е. равняется числу объектов. Как видно из матрицы, обученный классификатор ошибался на объектах класса normal: перепутал его с классом more (1 раз) и классом less (2 раза).
На рисунке 5 показана матрица ошибок с добавлением «Доли верных положительных классификаций» ( True Positive Rates – TPR) и «Доли ложных отрицательных классификаций» (False Negative Rates –FNR), размещенных в правой части рисунка.
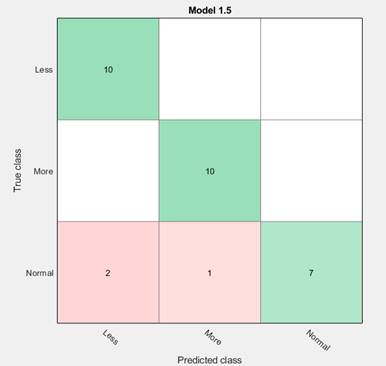
Рисунок 4. Матрица ошибок
В последних двух столбцах справа показаны сводные данные по каждому классу. Например, в третьей строке для класса normal стоят значения 70 % и 30 %, соответствующие TPR и FNR. Иными словами, для этого класса доля правильно расклассифицированных объектов составляет 70 %, а доля ошибочных – 30 %. Также видно, что объекты первого и второго классов разделены безошибочно: для них значения TPR = 100 %.
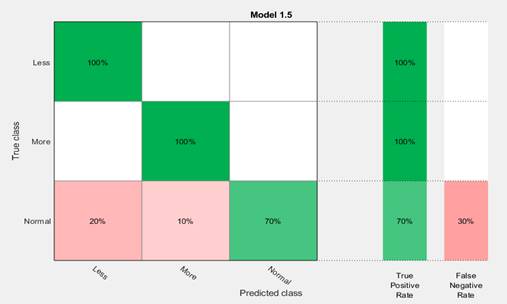
Рисунок 5. Положительные и отрицательные классификации
На рисунке 6 показана кривая операционной характеристики (receiver operating characteristic – ROC), которая показывает долю верных положительных классификаций (TPR) в функции от доли ложных положительных классификаций (false positive rate – FPR) для выбранного классификатора.
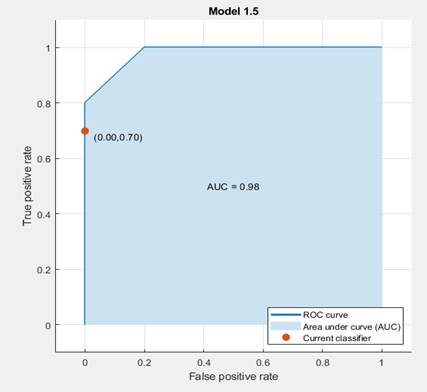
Рисунок 6. Кривая операционной характеристики
На приведенном графике идеальный результат безошибочной классификации – это линия, образующая прямой угол в верхнем левом углу графика. Плохой результат, который не лучше случайного, отображается линией, проходящей под углом 45 градусов из левого нижнего угла графика в правый верхний. Число, характеризующее площадь под кривой (Area Under Curve – AUC), является показателем общего качества классификатора. Чем больше значения AUC, тем лучше качество классификатора.
Для предсказания класса нового наблюдения необходимо после создания модели экспортировать ее в рабочую область. В итоге формируется структура trainModel, которая используется для прогнозирования с использованием новых данных. В качестве примера ниже приведен результат классификации нового вектора mj1 = (2.8 2.9 0.4 2.3 2.5):
>> yfit = trainedModel.predictFcn (mj1)
yfit =
categorial
Less
Таким образом, выбранный метод k-NN отнес КСП данного объекта к классу, который обозначен как «ниже нормальной КСП».
Обратимся к нейронной сети (НС) для классификации КСП разыгранных объектов. Хотя НС и не выбрана в автоматическом режиме как приемлемый классификатор (была выбрана опция All Quick-To-Train, нацеленная, прежде всего, на скорость вычислений). Созданная в программе MatLab двухслойная нейронная сеть с выбранным количеством нейронов, соответствующих задаче, приведена на рисунке 7.
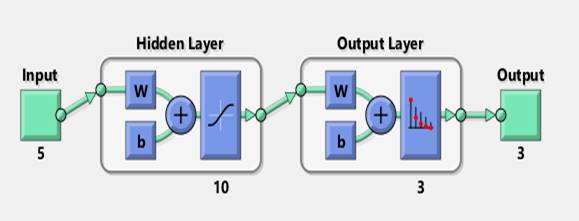
Рисунок 7. Нейронная сеть
Источник: получено автором.
Исходная совокупность данных из 30 объектов делится на 3 части в пропорции 70 %, 15 % и 15 %:
· обучающая (Training) выборка (20 объектов), которая используется для обучения сети;
· валидационная (Validation) выборка (5 объектов), применяемая для оценивания обобщающей способности сети и остановки процесса обучения в случае прекращения улучшения обобщения;
· тестовая (Testing) выборка (5 объектов), предназначенная для независимой меры характеристики сети во время и после обучения.
Часть результатов обучения представлена ниже. На рисунке 8 приведены три кривые обучения, соответствующие обучающей, валидационной и тестовой выборкам.
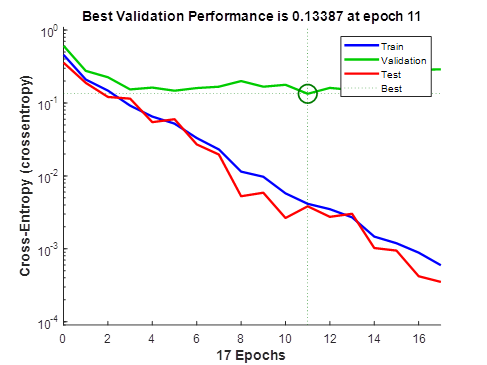
Рисунок 8. Кривые обучения сети
Источник: получено автором.
На вертикальной оси графика рисунка 8 отложена величина кросс-энтропии (cross-entropy), которая оценивает поведение сети с учетом целевых и выходных значений. Минимизация кросс-энтропии приводит к классификаторам хорошего качества. На горизонтальной оси указано количество эпох обучения, откуда видно, что на 11 эпохе произошло ухудшение обобщения сети, поэтому сеть обучилась за это время.
Для определения принадлежности предприятия-объекта с конкретному классу из 3 выделенных сохраним нейронную сеть в рабочем пространстве MatLab, а затем подадим на ее вход через командное окно параметры объекта, например, mj3 = [5.5; 6.5; 5; 5; 6].
Сеть выдает ответ в виде вектора столбца, наибольшее значение которого определяет класс:
>> fit = net (mj3)
fit =
0.0001
0.9990
0.0009.
Таким образом, с помощью нейронной сети для конкретного примера получили ответ о принадлежности объекта с такими параметрами ко второму классу (в наших обозначениях – normal).
4. Обсуждение
Полученные результаты показывают возможность применения методов машинного обучения для оценивания конкурентоспособности предприятий. Все расчеты выполнены на основе разыгранной базы данных. В реальной ситуации и сами факторы, и их значения могут быть отличными от рассмотренных в данной работе, но здесь и не преследовалась цель создания расчетной методики для оценки конкурентоспособности. Рассматривался лишь подход для классификации конкурентоспособности с использованием методов машинного обучения.
Заключение
Таким образом, в работе продемонстрировано применение методов машинного обучения с использованием программного продукта MatLab 2018b для решения задачи по конкурентоспособности предприятий. В дальнейшем предполагается проанализировать возможности формирования количественной оценки конкурентоспособности предприятий.
Источники:
2. The Global Competitiveness Report. World Economic Forum, 2018.
3. https://articlekz.com/en/article/27708.
4. Zelga К. The importance of competition and enterprise competitiveness. World Scienсе News, 72 (2017), 301-306.
5. M. J. Stankiewicz, The competitiveness of businesses, Building competitiveness companies in the conditions of globalization, 2005, Home Organizer, Torun.
6. Shpak N., Seliuchenko N., Kharchuk V. Evaluation of Product Competitiveness: A Case Study Analysis. Organizacija, Volume 52 Issue 2, May 2019, 107-125
7. Alpaydin E. Introduction to machine learning. Massachusetts Institute of Technology. 2010. - 579 р. https://www.pdfdrive.com/introduction-to-machine-learning-second-edition-adaptive-computation-and-machine-learning-e162136143.html
8. Shalev-Shwartz S., Ben-David S.. Understanding Machine Learning: From Theory to Algorithms. New York, Cambridge University Press. 2014. 449 р. https://books.google.ru/books?id=Hf6QAwAAQBAJ&hl=ru
9. Ezghazi S., Zahi A., Zekoua K. A new nearest neighbor classification method based on fuzzy set theory and aggregation operators. Expert Systems with Applications.2017, V.80, № 1, P. 58-74.https://doi.org/10.1016/j.eswa.2017.03.019
10. Zhang Х., Li Y. KRNN: k Rare-class . Nearest Neighbour classification. Pattern Recognition. 2017, V. 62, February, P. 33-44. https://doi.org/10.1016/j.patcog.2016.08.023.
11. Azad М., Moshkov М. Multi-stage optimization of decision and inhibitory for decision tree tables with many-valued decisions . European Journal of Operational Research, 2017, V. 263, Issue 3, P. 910-921. https://doi.org/10.1016/j.ejor.2017.06.026
12. Kim K. , Hong J. A hybrid decision tree algorithm for mixed numeric and categorical data in regression analysis. Pattern Recognition Letters, 2017, V. 98, P. 39-45. https://doi.org/10.1016/j.patrec.2017.08.011.
13. Haykin S., Neural Networks and Learning Machines, Pearson Education, New York, 2009.
14. Beale M., Hagan M., Demuth H.Neural Network Toolbox User's Guide. R2015b,https://mafiadoc.com/neuralnetworktoolboxuser39sguide_59c39e691723dd285cbc5dae.html (дата обращения: 22.04.2019)
15. Рамсундар Б., Заде Р.Б. TensorFlow для глубокого обучения. М.: BHV, 2019, 250 стр.
16.Шакла Н. Машинное обучение и TensorFlow. СПб.: Питер, 2019. — 336 с.
Страница обновлена: 01.08.2026 в 18:14:39
Download PDF | Downloads: 78 | Citations: 3
Machine learning methods in the assessment of the enterprise's competitiveness
Martynova Y.A.Journal paper
Russian Journal of Innovation Economics
Volume 10, Number 1 (January-March 2020)
Abstract:
The results of the enterprise's competitiveness classification using machine learning methods are presented. The factors that affect the organization's competitiveness and possible classes of competitiveness are identified. When solving the classification problem, the Classification Learner module, which is part of the MatLab 2018b software product, was used. The Toy Dataset, which was formed by the Monte Carlo method, was used as the training sample required in machine learning to output the model. The solution of the problem has shown that the best method for classifying the enterprise's competitiveness is the k-nearest neighbors (k-NN) algorithm, which has the highest accuracy. In addition, the same problem was solved using a multi-layer neural network.
Keywords: machine learning, competitiveness of the enterprise, classification models, neural network
JEL-classification: С45, С65, D81
References:
Azad M., Moshkov M. (2017). Multi-stage optimization of decision and inhibitory for decision tree tables with many-valued decisions European Journal of Operational Research. (3). 910-921.
Ezghazi S., Zahi A., Zekoua K. (2017). A new nearest neighbor classification method based on fuzzy set theory and aggregation operators Expert Systems with Applications. (1). 58-74.
Haykin S. (2009). Neural Networks and Learning Machines, Pearson Education
Kim K., Hong J. (2017). A hybrid decision tree algorithm for mixed numeric and categorical data in regression analysis Pattern Recognition Letters. (98). 39-45.
Ramsundar B., Zade R.B. (2019). TensorFlow dlya glubokogo obucheniya [TensorFlow for deep learning] (in Russian).
Shakla N. (2019). Mashinnoe obuchenie i TensorFlow [Machine learning and TensorFlow] (in Russian).
Shpak N., Seliuchenko N., Kharchuk V. (2019). Evaluation of Product Competitiveness: A Case Study Analysis Organizacija. (2). 107-125.
Zelga K. (2017). The importance of competition and enterprise competitiveness World Sciense News. (72). 301-306.
Zhdanova E.S. (2015). Analiz opredeleniy termina konkurentosposobnost predpriyatiya [Analysis of definitions of the enterprise competitiveness]. Vestnik nauki i obrazovaniya Severo-Zapada Rossii. (4). 1-9. (in Russian).